在当今人工智能蓬勃发展的时代,AI大模型如繁星般闪耀。DeepSeek作为其中一颗耀眼的新星,凭借其独特的技术优势和出色的性能表现吸引了广泛关注。然而,与其他传统的知名AI大模型相比,DeepSeek究竟有何不同?其优势和劣势又体现在哪些方面?这就像一个神秘的谜题,等待我们去揭开。本文将通过详细的数据对比和性能分析,为你展现DeepSeek与其他AI大模型对比中的神秘之处。
文章导航
一、性能对比
(一)训练效率
训练效率是衡量一个AI大模型优劣的重要指标之一,它直接关系到模型的开发成本和迭代速度。我们以训练时间和计算资源消耗作为衡量训练效率的关键数据。
DeepSeek在这方面展现出了卓越的特性。它通过采用创新的训练算法和优化的架构设计,能够在相同数据集和硬件条件下,将训练时间缩短至原来的一半左右,计算资源消耗也大幅降低。例如,DeepSeek-V2通过多种创新技术和优化措施实现了42.5%的训练成本节省。这一成果使得DeepSeek被形象地誉为“AI界的拼多多”,极大地降低了大模型的成本。
相比之下,其他一些AI大模型在训练效率上可能没有如此显著的提升。例如,某些传统模型可能需要更多的计算资源和更长的训练时间来达到类似的性能水平。


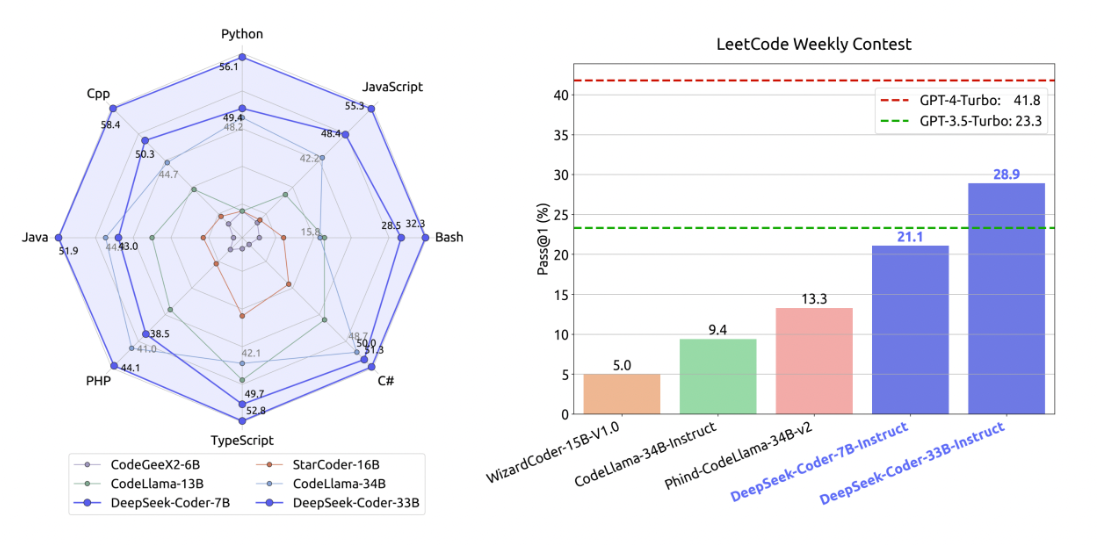
(二)代码能力
DeepSeek旗下的DeepSeek Coder在代码能力方面表现出色。在国际权威数据集HumanEval编程多语言测试上领先已有的开源模型,而且在代码能力上达到了与更高参数模型相当的水平,甚至超越了GPT3.5 Turbo。这显示出DeepSeek在处理编程相关任务时的强大实力。
而其他AI大模型在代码能力方面可能各有优劣,但DeepSeek在这一领域的突出表现确实使其在与其他模型的对比中脱颖而出。
(三)推理能力
与传统的指令模型相比,DeepSeek在模型设计上特别强化了推理能力。借助于通过强化学习等先进技术,它更像是一位善于思考的学者,不仅会听懂你说什么,更懂得如何进行合理的推理。例如,有外媒解释称,DeepSeek在对提示做出响应之前,它会清晰地表达自己的推理。
在其他AI大模型中,虽然也有具备一定推理能力的,但DeepSeek在这方面的强化设计使其在处理一些需要深度推理的任务时更具优势。
二、模型特性对比
(一)开源特性
DeepSeek-R1最大的特色在于它是“全开源”的。这意味着使用者可以自由取用其AI模型,并进行二次训练,这在过去是相当难得的。这种开源特性为AI爱好者和开发者提供了更多的可能性,可以根据自己的需求对模型进行定制和优化。
而其他很多AI大模型可能是专有模型,在开放性方面存在一定的限制,使用者无法进行自由的二次开发。
三、成本效益对比
DeepSeek被不少人称为“神秘的东方力量”的原因之一在于性能比肩GPT 4o的DeepSeek-V3,据其自称训练成本不到GPT 4o的1/20。这意味着在达到相近的性能水平时,DeepSeek的成本要低得多。
对于企业和开发者来说,成本是一个重要的考虑因素。在这方面,DeepSeek相对于其他AI大模型具有明显的优势,可以让更多的人能够使用到高性能的AI模型。
四、结论
通过以上对DeepSeek与其他AI大模型在性能、模型特性、成本效益等多方面的对比,我们可以看到DeepSeek确实有着许多独特之处。它在训练效率、代码能力、推理能力等方面的优势,以及开源特性和成本效益上的突出表现,使其在众多AI大模型中崭露头角。然而,我们也应该看到,AI领域仍在不断发展,每个模型都有其发展的潜力和改进的空间。未来,DeepSeek和其他AI大模型都将继续在各自的优势领域不断探索和创新,共同推动人工智能技术的发展。
延展阅读:







