在当今人工智能蓬勃发展的时代,国产大模型DeepSeek-V3犹如一颗璀璨的新星闪耀登场。对于广大公众而言,它提供了一种先进且适应性强的AI工具。无论是搜索、翻译还是作为虚拟助手,它都表现出色,有效改善信息处理流程,简化日常任务,在工作和生活中都能提供实用便捷的帮助,提升生活品质和效率。它的出现,无疑给国产自主研发大模型注入了强大动力,让我们对国产大模型的未来充满期待。那么,DeepSeek-V3究竟有哪些独特的特点呢?
文章导航
一、模型架构方面的特点
(一)采用混合专家(MoE)架构
DeepSeek-V3采用了创新的混合专家(MoE)架构,这一架构包含6710亿参数。这种架构的优势在于,虽然模型参数量巨大,但在实际运行过程中,每个输入只会触发370亿参数。这就使得它在维持高性能的同时,实现了计算效率和计算能力之间的良好平衡。
例如,在处理复杂任务时,它能够高效地调用不同的“专家”(参数子集)来应对,既保证了处理的准确性,又不会因为过多的参数参与运算而导致效率低下。
(二)无辅助损失的负载平衡策略
在DeepSeek-V2高效架构的基础上,DeepSeek-V3还引入了无辅助损失的负载平衡策略。通过动态调整专家偏置项,确保训练过程中的负载平衡。这一策略有效避免了传统辅助损失对模型性能的负面影响,使得模型在训练过程中能够更加稳定、高效地学习,从而提升了模型的整体性能。

二、性能表现方面的特点
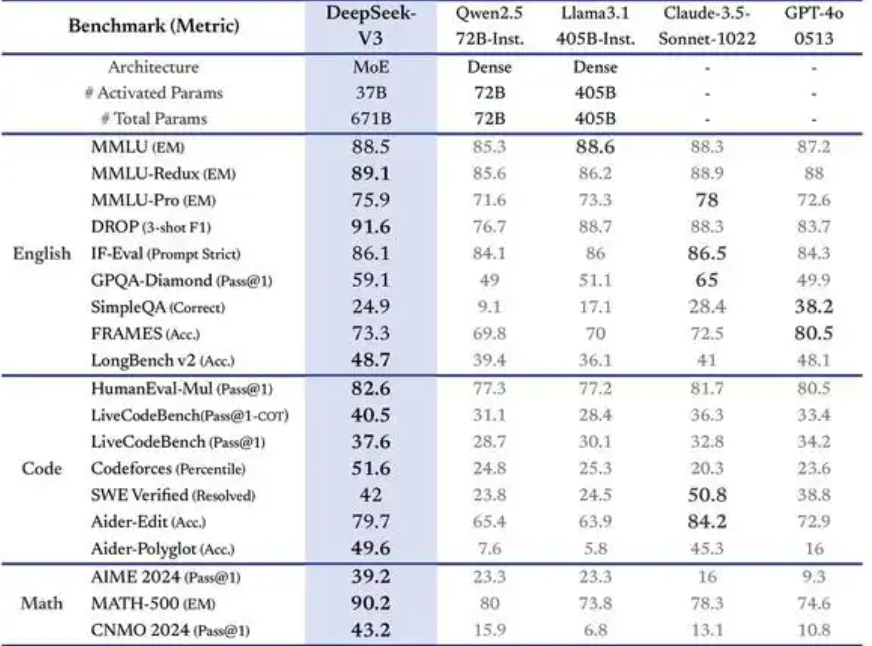
(一)在多项测评中达到开源SOTA
在多项测评上,DeepSeek-V3达到了开源SOTA(State of the Art,最先进水平),超越Llama 3.1等开源模型。例如,在教育基准测试(如MMLU、MMLU Pro和GPQA)上,它超越了所有其他开源模型,并表现出与领先封闭源代码模型(如GPT 4o和Claude Sonnet 3.5)相当的性能。这表明DeepSeek V3在知识理解和运用方面具有很高的水平。
(二)在不同任务类型中的优异表现
1. 知识类任务
在知识类任务(MMLU, MMLU Pro, GPQA, SimpleQA)上的水平相比前代DeepSeek V2.5显著提升,接近当前表现最好的模型Claude 3.5 Sonnet 1022。这意味着它在回答各种知识相关问题时,能够提供更加准确和全面的答案。
2. 长文本测评
在长文本测评中,DROP、FRAMES和LongBench v2上,DeepSeek-V3平均表现超越其他模型。这显示出它在处理长文本内容时具有独特的优势,无论是对长文本的理解、分析还是生成相关内容,都能够有出色的表现。
3. 代码能力
DeepSeek-V3在算法类代码场景(Codeforces),远远领先于其他模型。这对于开发者来说是一个非常有吸引力的特点,它可以为代码编写、代码优化等工作提供有力的支持。
三、推理速度与适用性方面的特点
(一)推理速度快
Deepseek-V3每秒的吞吐量可达60 tokens,这一较快的推理速度使得它在处理各种任务时能够快速给出结果。无论是在实时交互场景,如智能对话、在线问答等,还是在处理批量任务时,都能够高效地完成任务,减少用户等待时间。
(二)适用范围较广
相比GPT 4o,DeepSeek-V3更适合用于解答开放式问题。对于较为具体的细节问题,两者各有优势,GPT 4o更保守且更可靠,DeepSeek-V3广度和维度更高。这表明DeepSeek-V3在应对不同类型的问题时,有自己独特的优势领域,能够满足用户在不同场景下的需求。
四、成本效益方面的特点
(一)训练成本低
DeepSeek-V3的训练成本仅为557万美元,远低于行业平均水平,成为开源模型中的“性价比之王”。这一低成本的优势,使得更多的开发者和企业能够使用和研究该模型,降低了人工智能技术应用的门槛,也为国产大模型在市场竞争中赢得了一席之地。
五、总结
DeepSeek-V3作为国产大模型,在模型架构、性能表现、推理速度与适用性以及成本效益等方面都展现出了诸多令人瞩目的特点。它的出现不仅为用户提供了一个优秀的AI工具,也为国产人工智能产业的发展注入了新的活力。随着技术的不断发展和完善,我们有理由相信DeepSeek-V3将在未来发挥更大的作用,推动国产大模型走向更广阔的天地。同时,也期待更多的国产大模型能够不断创新和突破,在全球人工智能领域中占据重要的地位。
延展阅读:
DeepSeek-V3开源后,开发者如何受益呢?其编程能力超越Claude了吗?







