在当今的人工智能领域,深度学习模型的发展日新月异。然而,大型模型如Deepseek-R1虽然功能强大,但庞大的规模和较高的计算需求在实际应用中可能带来诸多不便。模型蒸馏技术的出现为解决这一问题提供了有效的途径。通过蒸馏,我们可以将像Deepseek-R1这样大型模型的知识和推理能力转移到较小的模型中,既降低了计算成本,又能在一定程度上保留其优秀的性能。那么,到底如何实现Deepseek-R1的蒸馏过程呢?这是一个值得深入探讨的问题。
文章导航
一、什么是模型蒸馏?
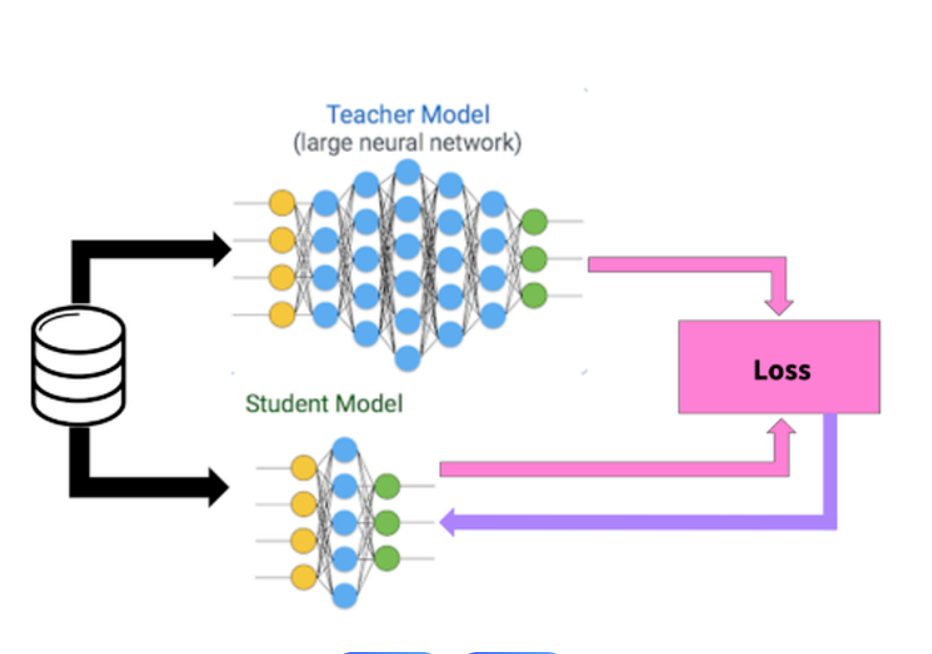
模型蒸馏是一种机器学习技术,其中一个较小的模型(“学生”)被训练来模仿一个较大的预训练模型(“老师”)的行为。其目标是在显著降低计算成本和内存占用的同时,保留大型模型的关键特性。在Deepseek-R1的蒸馏过程中,它也是遵循这样的基本原理。

二、Deepseek-R1蒸馏过程中的关键要素
(一)教师模型与学生模型的选择
1. 教师模型 Deepseek-R1
Deepseek-R1作为教师模型,是一个经过大量数据训练、具有强大推理能力的大型模型。它包含丰富的知识和复杂的结构,能够为蒸馏过程提供可靠的知识源。
2. 学生模型
例如微软的Phi-3-Mini等相对较小的模型可以作为学生模型。在选择学生模型时,要考虑其结构与任务的适配性,以便更好地接受来自Deepseek-R1的知识。
(二)蒸馏技术的应用
1. 使用LoRA(Low Rank Adaptation)技术
LoRA是一种专门用于模型蒸馏等任务的技术。在Deepseek-R1的蒸馏中,它可以帮助调整模型的参数,使得学生模型能够更有效地学习教师模型的行为。通过低秩分解等方法,LoRA能够在不显著增加计算成本的情况下,实现对模型的优化。
2. 基于SFT数据集的蒸馏
一些情况下,会在较大的大模型(如Deepseek-R1)生成的SFT(Supervised Fine Tuning)数据集上对较小的模型进行指令微调。例如在将Deepseek-R1的推理能力迁移到Qwen系列模型时,这种基于SFT数据集的蒸馏方式能够降低模型的规模和运行成本,同时保持较强的推理能力。
三、Deepseek R1蒸馏的具体步骤
(一)准备数据
1. 首先要获取Deepseek-R1生成的相关数据,这些数据将作为学生模型学习的依据。如果是基于SFT数据集进行蒸馏,就需要对该数据集进行整理和预处理,确保数据的质量和格式符合蒸馏的要求。
2. 对于不同的学生模型和任务,可能需要对数据进行筛选和调整,例如去除噪声数据、对数据进行分类等。
(二)设置蒸馏环境
1. 选择合适的计算平台,如百度智能云千帆ModelBuilder等平台可以提供模型蒸馏的相关功能。这些平台能够提供必要的计算资源和工具,方便进行蒸馏操作。
2. 配置相关的参数,包括学习率、蒸馏的比例等。例如,在使用LoRA技术时,要设置合适的低秩参数,以平衡模型的性能和计算成本。
(三)进行蒸馏训练
1. 在设置好的环境下,启动学生模型的训练。学生模型将以Deepseek-R1为目标,通过最小化与Deepseek-R1输出的差异(如使用KL散度等度量)来学习其推理能力。
2. 在训练过程中,要不断监控模型的性能,根据性能指标调整训练的策略。例如,如果发现学生模型在某些任务上的表现不佳,可以调整数据的分布或者增加训练的轮次。
四、蒸馏后的效果与意义
1. 性能表现
经过蒸馏后的模型在多个基准测试中表现优异。例如,蒸馏出的Qwen 32B在推理任务上明显优于直接用RL训练的版本。这表明通过蒸馏技术,成功地将Deepseek R1的推理能力迁移到了较小的模型上,并且在一定程度上提升了小型模型的性能。
2. 实际意义
降低了计算成本和内存占用,使得模型能够在资源受限的环境中部署,如在移动设备或者边缘计算设备上。同时,也为模型的进一步优化和应用提供了新的思路,例如通过冷启动和多阶段训练进一步提升模型性能等。
实现Deepseek-R1的蒸馏过程需要综合考虑多个方面,从模型的选择、技术的应用到具体的蒸馏步骤等。通过不断的探索和优化,模型蒸馏技术将在人工智能的发展中发挥越来越重要的作用。
延展阅读:







