在当今的人工智能领域,DeepSeek-V3技术报告引起了广泛的关注。随着技术的不断发展,理解这个强大的混合专家(Mixture of Experts, MoE)语言模型背后的技术要点变得至关重要。DeepSeek-V3拥有6710亿个总参数,每个token激活370亿个参数,在架构、训练效率和性能等多方面进行了创新。这些创新不仅影响着模型自身的表现,也对整个行业有着重要的启示意义。那么,DeepSeek-V3技术报告中到底有哪些关键点呢?这篇文章将为您详细解读。
文章导航
一、架构创新
1. 多头部潜在注意力(Multi head Latent Attention, MLA)
DeepSeek-V3采用了MLA架构,这是其架构创新的一大亮点。MLA通过低秩联合压缩注意力键和值,减少了推理过程中的Key Value (KV)缓存,从而提高了推理效率。在实际应用中,这意味着模型在处理任务时能够更快地给出结果。并且,MLA在保持与标准多头注意力(MHA)相当性能的同时,显著减少了内存占用。这一特性使得模型在资源利用上更加高效,无论是在小型设备还是大型服务器上运行,都能够更好地平衡性能和资源消耗。
2. DeepSeekMoE架构
除了MLA架构,DeepSeek-V3还采用了DeepSeekMoE架构。这一架构在DeepSeek-V2中已经得到了充分的验证。DeepSeekMoE通过细粒度的专家分配和共享专家机制,进一步优化了模型的性能。它能够根据输入的不同特征,更加精准地分配计算资源,使得每个专家在处理特定类型的任务时能够发挥最大的效能,从而提高整个模型的处理能力。


二、训练效率提升
1. FP8训练技术
FP8训练是DeepSeek-V3提升训练效率的一项关键技术。它是一种降低模型训练精度以提升训练效率的技术。通过合理配置FP8的基础设置,模型能够在保证性能的前提下,大大缩短训练时间。这种技术的应用使得DeepSeek V3的完整训练仅需278.8万H800 GPU小时,相较于其他模型,在训练成本上有了显著的降低。
2. 无辅助损失的负载均衡策略
DeepSeek-V3首创了一种无辅助损失的负载均衡策略。在模型的训练过程中,负载均衡是非常重要的。传统的负载均衡策略可能会因为辅助损失的存在而影响模型的最终性能。而DeepSeek-V3的这一创新策略避免了这种情况的发生,使得模型在训练过程中能够更加稳定地进行负载均衡,从而提高训练效率,并且有助于提升模型的整体性能。
三、性能表现
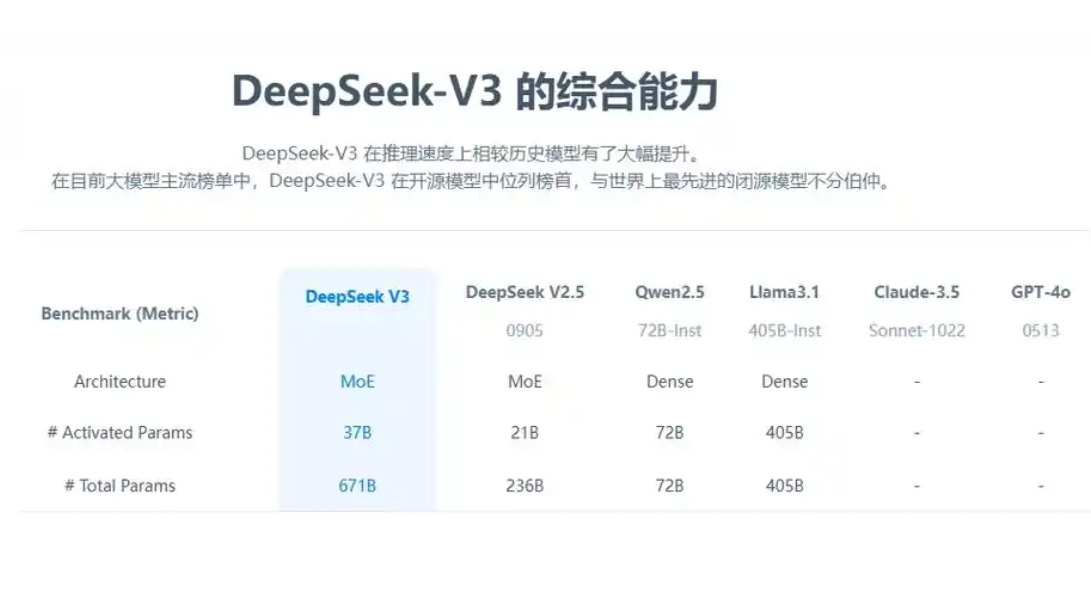
1. 在多个评估基准上的优异表现
DeepSeek-V3在多个标准和开放评估基准上进行了评估,涵盖知识、代码、数学和推理等领域。评估结果表明,DeepSeek-V3在性能上超越了其他开源模型,并能够与主流闭源模型相媲美。在代码和数学领域,DeepSeek V3的表现尤为突出。这意味着在实际应用中,无论是处理代码相关的任务,如代码生成、代码补全,还是解决数学问题,DeepSeek-V3都能够提供高质量的结果。
2. 高性价比的训练成本
DeepSeek-V3的训练成本仅为557.6万美金,远低于行业平均水平。这一低训练成本的实现得益于其在架构和训练技术上的创新。它仅用2000张卡就成功对标OpenAI几亿烧出来的大模型,成为开源模型中的“性价比之王”。这使得更多的研究机构和企业能够在有限的预算下使用高性能的语言模型,推动了人工智能技术的广泛应用。
四、总结
DeepSeek-V3技术报告中的这些关键点,从架构创新到训练效率提升,再到卓越的性能表现,都展示了该模型在人工智能领域的先进性。这些创新不仅为DeepSeek-V3自身带来了优异的性能,也为整个行业在语言模型的研发和应用方面提供了宝贵的经验。随着技术的不断发展,我们期待看到DeepSeek-V3以及类似的先进模型在更多领域发挥重要的作用。
延展阅读:
DeepSeek-V3开源后,开发者如何受益呢?其编程能力超越Claude了吗?







