在大数据处理与实时计算领域,Apache Flink凭借其高吞吐量、低延迟以及强大的状态管理能力,成为了众多企业和开发者首选的流处理框架。其中,Flink CheckPoint作为其核心特性之一,扮演着至关重要的角色。Flink CheckPoint不仅是流状态恢复的关键机制,更是实现Flink作业Exactly Once和At Least Once语义的基石。本文将深入探讨Flink CheckPoint实现机制是什么,以及如何通过参数调优来优化CheckPoint的性能,帮助读者更好地理解和应用这一重要特性。
文章导航
一、Flink CheckPoint是什么?
Flink CheckPoint作为流状态恢复机制,保证Flink的Exactly Once和At Least Once语义。
Flink CheckPoint实现机制:
Job Manager端的CheckpointCoordinator组件会周期性的向数据源发送执行cp(后续CheckPoint简称)的请求,从source发送barrier标记数据,数据经过operator,到snik结束。在每个模块收到barrier后会上报JobManager已完成barrier ID,并将当时的内存状态进行磁盘快照保存。
在CheckpointCoordinator收到同一CheckPoint ID的完成消息后,做一次全局快照,说明这次CheckPoint完成,如此反复。如果程序突然终止,可以从最近的一次cp快照中恢复。
详解可以参考网上解释:https://www.jianshu.com/p/7956b2a76277
二、Flink CheckPoint参数如何调优?
每次cp都会将运行时的状态做一份全局快照保存到磁盘上面,方便出问题时,将上次状态从磁盘中恢复到内存,做到无缝重启消费。
开启CheckPoint并配置启动间隔代码:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(60000);1、CheckPoint间隔时间不要太短。如果启动间隔小于Checkpoint过程时间,就相当于程序一直做CheckPoint,保证了安全,消耗了资源。cp的瓶颈是在磁盘IO部分。如果cp完成的速度慢,就会影响整个流的处理速度。
2、Checkpoint根据业务场景选择合适的后端存储方式,生产环境一般选择RocksDBStateBackend作为状态后端存储,并开启增量检查点。
3、RockDB相关调优。
4、应用状态数据量越少越好,减少CheckPoint完成时间。
三、用CheckPoint实现聊天实时QA问题匹配时超时报错怎么办?
根本问题点在于CheckPoint太大,并且每次快照时间间隔太短,导致流处理大部分时间在做CheckPoint,最后CheckPoint超时,报错程序退出。下面是具体的根因介绍:
该方案是实现聊天QA问题匹配,需要在使用keyState存储接收问题时间和其他相关字段,并作用到后续回复问题的字段上,进行打标。随着数据量增加,状态存储的数据量增长,这里设置TTL清理机制,清理掉已经过期的数据,降低数据膨胀。
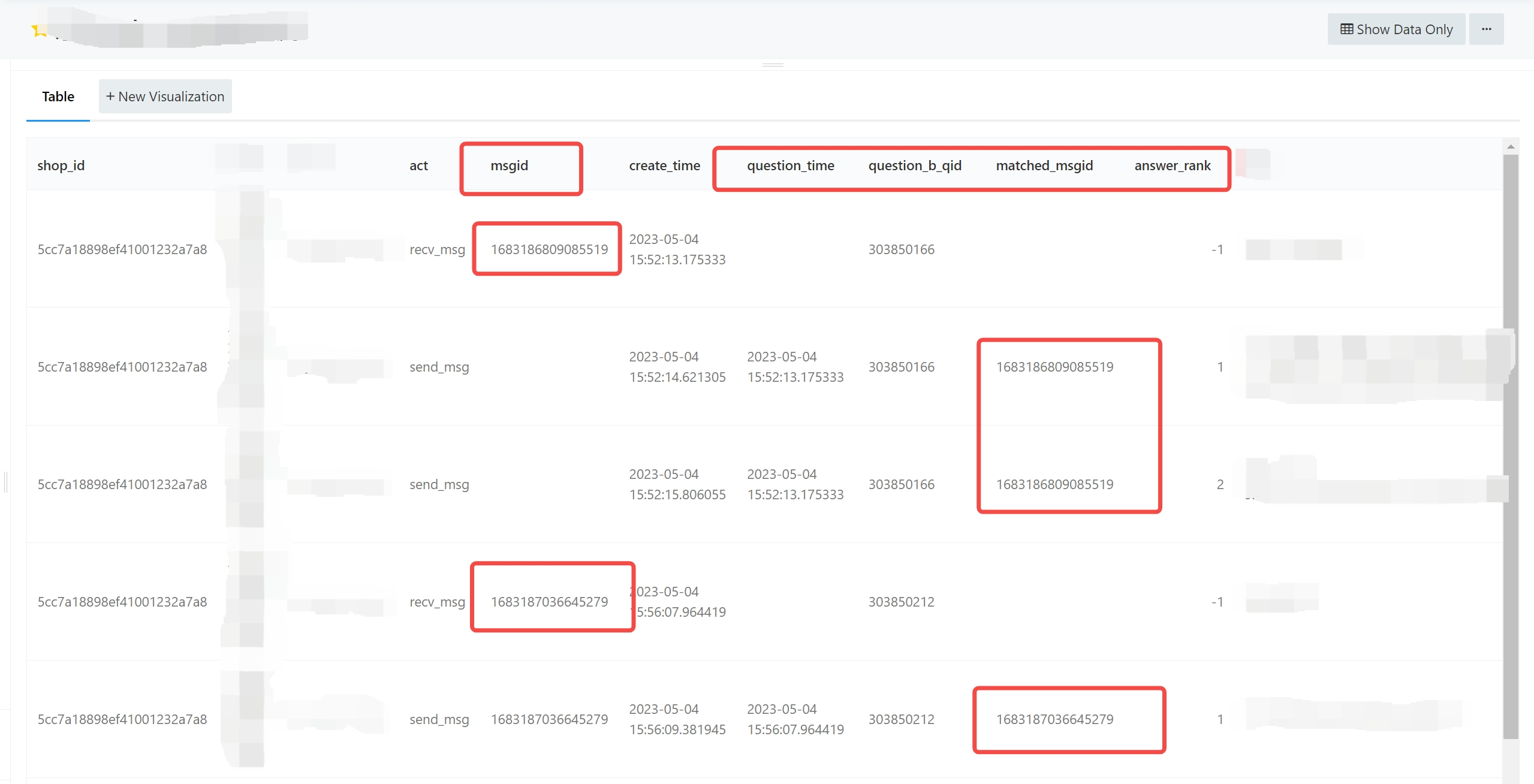

上图为该方案的具体实现方案,其中send消息需要打标上消息ID,问题ID和匹配问题ID的时间。
最开始使用配置为:cp每次的频率是2s,StateBackend为HashMapStateBackend。
问题点:FsStateBackend实现会导致不经常访问的key不能清理,导致KeyedSate会越来越大,每次cp的时间越来越长,反馈到图里面就是消费堆积越来越大。当State超过1GB时,2s内不能完成1GB数据的写入磁盘,最后cp失败,流消费停止。
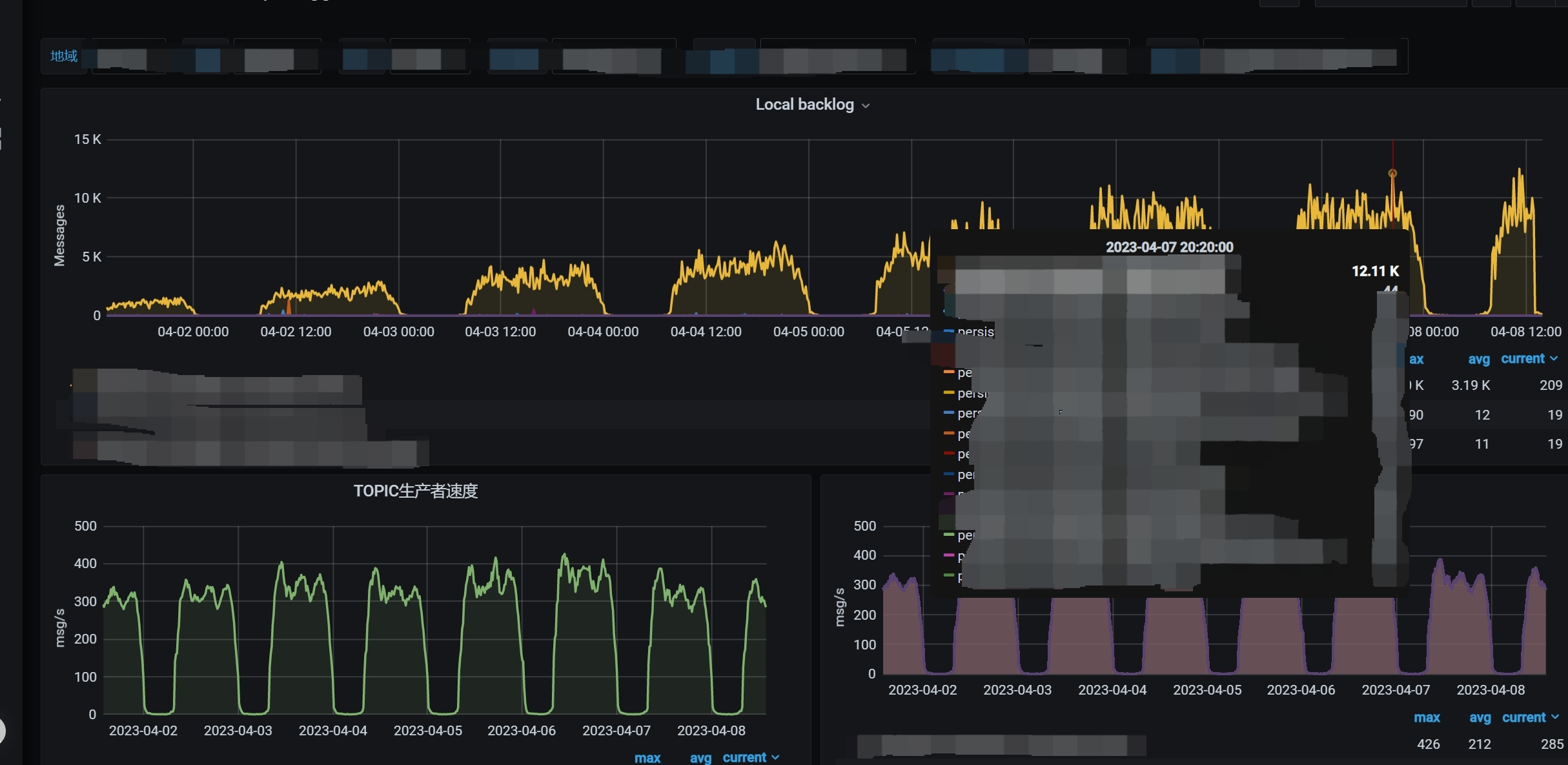
通过磁盘IO速度,消费堆积,内存变化,堆栈分析,源码分析,代码调整的方法中,发现关键点为cp频率太高,故调整从2s到60s做一次cp,并且将StateBackend调整为RocksdbStateBackend,这种rocksdb后端存储可以通过合并的方式,在文件合并的过程时做过期状态清理,解决状态数据膨胀问题。
优化前后效果对比,从3方面进行分析:
- 消费延迟:
从图中可以看出现在的1周的流消费延迟基本和生产者写入的趋势一致,并且每天消费延迟也没有变大,代表没有随着时间推移,消费延迟而增加,可以看出是正常消费。
- 磁盘io方面:
以前的磁盘IO速度会随着时间增加而增加。高峰时间是磁盘57MB/s,现在降低到10Ms/s。环节磁盘IO压力。
- CheckPoint文件大小方面:
由崩溃时1.2G降低到62M。
三、小结
本次分享前半段简单介绍了CheckPoint的概念、实现机制和调优介绍,后半段通过一个具体的聊天QA匹配案例说明了CheckPoint的不当配置,导致消费程序随着时间推移,状态不断增大,CheckPoint超时而报错的问题。其中案例对问题的分析和解决的过程前后经历较长,得到一个宝贵的经验:说明排查程序问题时,观察磁盘IO也是很关键的一点,特别是在大数据场景,读取和写入的数据量越小,一般程序性能会有很大的提升。举一反三,后续线上的代码如果读写太大的数据量,就应该思考是否有优化空间。
延展阅读:







