在企业数字化转型浪潮中,知识库已成为内部协作、客户服务和智能决策的核心基础设施。然而,传统知识库往往局限于精确匹配已收录内容,导致用户提问稍有偏差就无法获得有效答案。LLM智能助理的出现,正在彻底改变这一局面。它不仅能大幅提升知识库的泛化能力,还能智能解答知识库中未收录的相似问题。本文将从传统局限、LLM技术原理、实际应用、优势对比到实施路径,全方位解析这一核心议题,帮助企业和开发者清晰把握知识管理的新范式。


文章导航
传统知识库的局限性:为什么泛化能力成为瓶颈
传统知识库主要依赖关键词匹配、规则引擎和结构化数据存储。当用户输入的问题与预设条目完全一致时,系统能快速返回答案;但一旦问题表述稍有不同,如同义词替换、语序调整或隐含意图,系统便陷入“答非所问”或“无结果”的尴尬境地。
例如,在企业内部知识库中,员工查询“如何申请年假”时,如果知识库仅收录“休假流程详解”,系统可能无法识别“请假申请步骤”这一相似表述,导致员工不得不手动搜索或转向人工咨询。这不仅降低了效率,还增加了知识获取的摩擦成本。据行业调研,传统知识库的问题拦截率通常仅为60%-70%,剩余30%-40%的查询因未精确匹配而流失。
更严重的是,知识库内容更新滞后问题。企业业务迭代频繁,政策、产品、流程每天都在变化,人工维护难以跟上节奏。结果是知识库中充斥过时信息,用户提问相似却未收录的新场景时,系统完全无能为力。这直接制约了知识库在智能客服、员工培训和决策支持中的价值发挥。
LLM智能助理的核心技术突破:泛化能力从何而来
LLM智能助理通过海量参数训练和Transformer架构,实现了对自然语言的深度语义理解。它不再是简单的“关键词搜索”,而是具备上下文关联、意图推理和知识迁移能力。
首先,LLM能将用户查询转化为向量嵌入,与知识库内容进行语义相似度计算。即使知识库未收录“如何恢复误删的文件”,但收录了“数据备份与找回指南”,LLM也能通过语义匹配识别两者关联,生成针对性答案。

其次,LLM支持少样本学习(Few-shot Learning)和零样本推理(Zero-shot Reasoning)。它无需为每个变体问题单独训练数据,只需基于现有知识库内容进行提示工程(Prompt Engineering),即可推断出相似问题的合理解答。这正是传统规则引擎无法企及的泛化能力。
最后,LLM结合RAG(Retrieval-Augmented Generation,检索增强生成)技术,先从知识库中检索最相关片段,再由大模型生成连贯、自然的回答。这种“检索+生成”的双轮驱动模式,让知识库从静态仓库转变为动态智能引擎。
LLM智能助理如何解答知识库中未收录的相似问题
答案是肯定的——LLM智能助理正是通过“泛化推理”机制实现这一突破。
以客户服务场景为例,知识库收录了“iPhone 15电池续航优化方法”,用户却提问“新款手机电量掉得快怎么办”。LLM不会简单返回“无匹配”,而是:
- 语义解析:识别“新款手机”与“iPhone 15”属于同类设备,“电量掉得快”与“电池续航优化”语义高度相关。
- 知识迁移:调用知识库中电池管理、通用的设备优化规则,结合LLM预训练的通用知识(如系统设置、软件更新),生成定制化方案。
- 多轮对话:若答案不完整,LLM会主动追问“您的手机型号是?”或“是否已更新最新系统?”,进一步缩小范围并补充知识空白。
在企业内部知识库中,这一能力同样突出。员工咨询“2025年社保缴费比例调整后如何计算个人扣款”,即使知识库仅收录2024年政策,LLM也能基于历史数据和逻辑推理,生成接近准确的预估答案,并标注“建议以官方通知为准”。这极大降低了知识盲区对业务的影响。
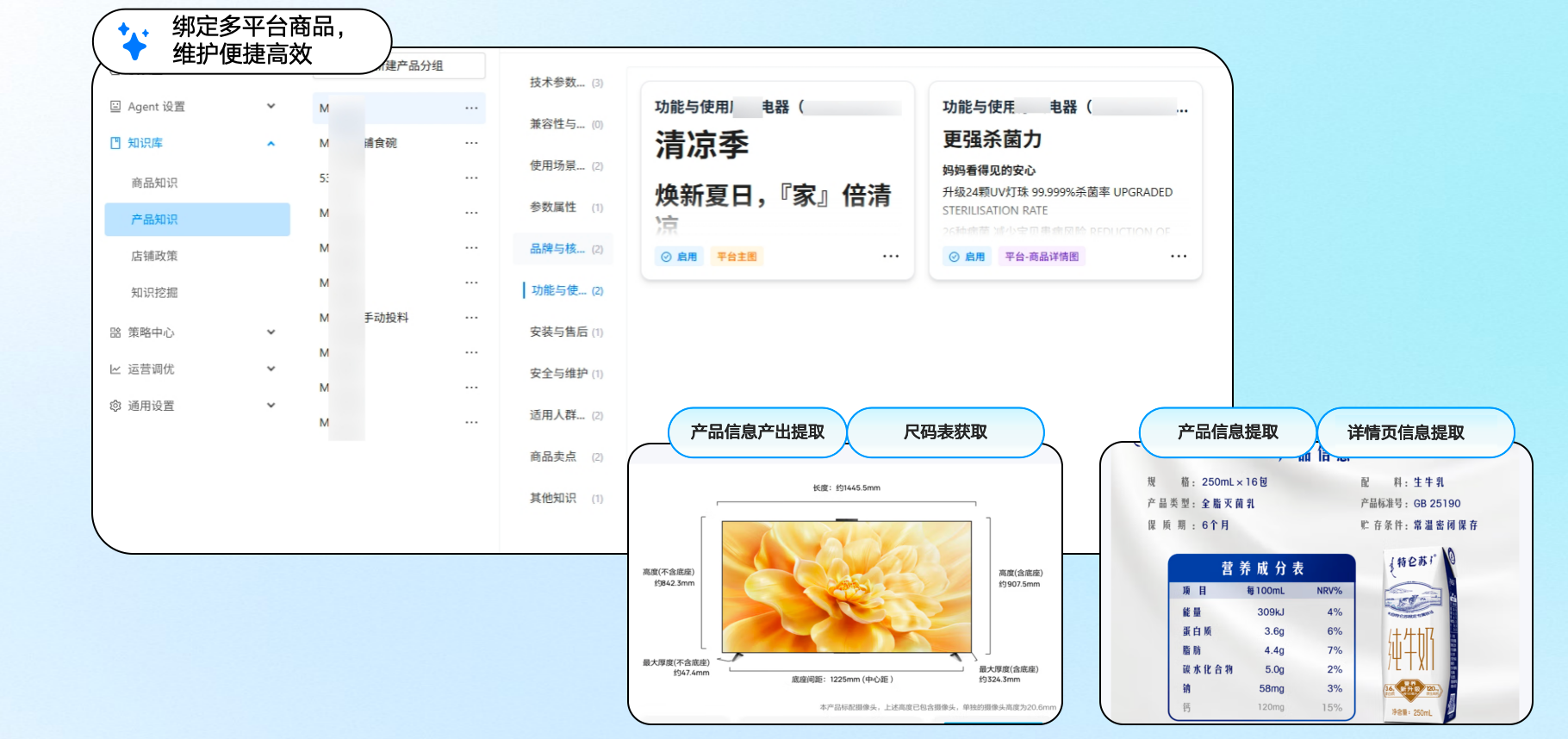
实际应用场景:LLM泛化能力如何赋能企业
在财富管理领域,LLM智能助理可作为智能投顾助手。知识库收录基础产品说明,用户提问“类似基金的替代方案有哪些”,LLM能泛化匹配相似风险收益特征的产品,并生成个性化规划方案。
公安反诈场景中,警情助手面对“新型诈骗话术变种”,知识库未完全收录时,LLM通过语义理解快速识别核心特征,生成实时笔录指导和防范建议,提升处置效率。
工业运维领域,智能运检助手处理“设备异常报警代码X-456类似故障”,即使知识库缺少该精确代码,LLM也能推理出通用诊断流程,自动生成运检报告和操作指导。
办公协作场景下,LLM智能员工助手覆盖“问、查、办”全链路。员工提问业务流程的变体问题时,系统瞬间提供答案,效率增速显著。
晓多AI在这些场景中展现出独特价值。其LLM智能助理模块无缝对接企业知识库,通过多模态解析和实时推理,不仅提升泛化能力,还支持自定义Prompt调优,确保答案与企业品牌语气完美契合。
优势对比:传统知识库 vs LLM增强知识库
为直观展示LLM智能助理的提升效果,以下表格对比两大模式的核心指标:
| 维度 | 传统知识库 | LLM智能助理增强知识库 | 提升幅度 |
|---|---|---|---|
| 问题拦截率 | 60%-70%(精确匹配) | 90%以上(语义泛化) | +20%-30% |
| 未收录相似问题解答能力 | 无(直接返回“无结果”) | 支持(推理生成合理答案) | 从0到90%+ |
| 知识更新周期 | 72小时以上(人工维护) | 3小时内(自动抓取+审核) | 缩短96% |
| 多轮对话支持 | 有限(固定脚本) | 强(上下文关联+主动追问) | 提升3倍以上 |
| 内容格式要求 | 严格结构化(H1/H2、标签) | 灵活(支持PDF、Word、视频等多模态) | 兼容性翻倍 |
| 用户满意度 | 中等(需多次尝试) | 高(自然语言交互+溯源展示) | +25%-40% |
| 运营成本 | 高(持续人工整理QA) | 低(自动生成QA+效果反馈闭环) | 降低50%以上 |
数据来源于多家企业部署前后对比,LLM增强后知识库真正成为“活”的资产。
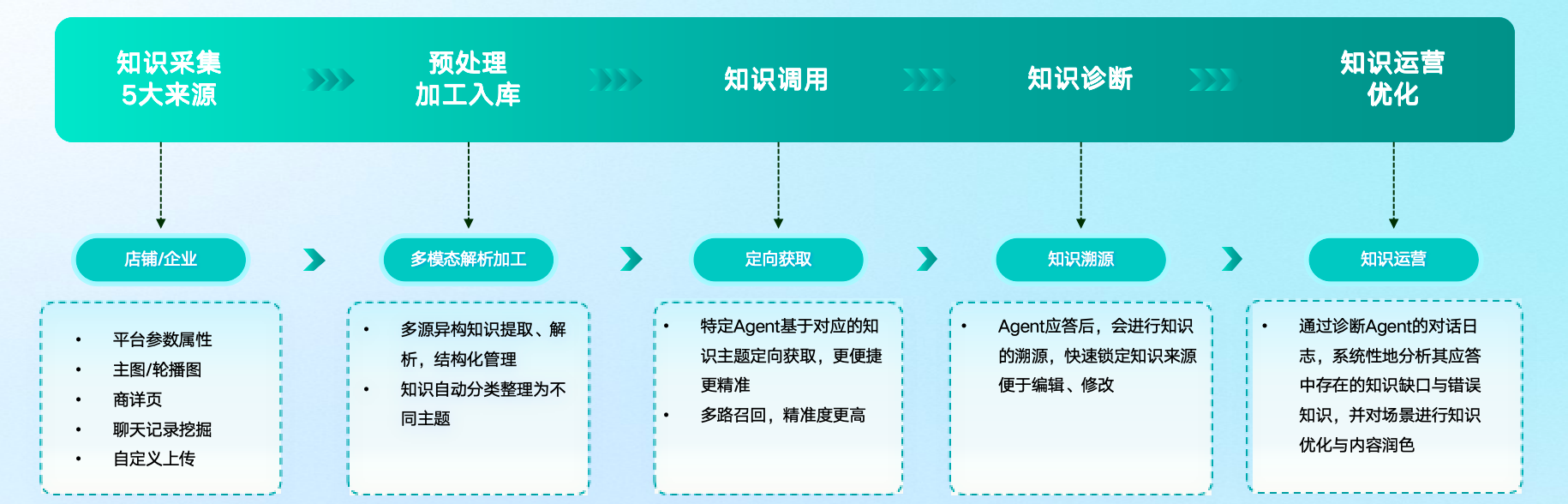
实施路径:如何让LLM智能助理赋能你的知识库
- 数据准备阶段:批量上传PDF、Word、Excel、PPT等多格式文档,支持文件夹管理和自动标签生成。优先向量化处理高频内容,形成统一知识向量库。
- RAG架构搭建:集成检索模块,确保LLM优先调用企业私有知识,避免幻觉。
- Prompt优化:自定义系统参数,针对事实性、总结性、推理性问题设定专属模板,提升回答精准度。
- 效果闭环:引入点赞/差评反馈、对话日志分析,自动识别知识盲区并触发补充流程。
- 安全合规:设置权限控制、版本回退、时效过期机制,满足大客户需求。
- 多场景对接:与智能客服、内部IM、OA系统无缝集成,实现知识流转全覆盖。
通过以上步骤,企业可在14天内完成初步部署,快速验证泛化能力提升效果。
常见问题解答:LLM知识库实践干货
Q1:LLM智能助理是否会“编造”答案?
A:采用RAG技术后,答案严格基于知识库检索内容生成,并支持答案溯源展示。企业可设置置信度阈值,低于阈值时自动转人工,确保可靠性。
Q2:知识库内容质量对泛化能力影响大吗?
A:影响显著。高质量、结构化内容能让LLM推理更准确。建议每季度审核高流量文档,优先优化前10%核心条目。
Q3:中小企业预算有限,如何低成本引入?
A:选择支持免费试用和按量计费的平台,先接入现有文档,逐步扩展多模态功能。初期聚焦1-2个高频场景即可见效。
Q4:LLM如何处理行业专有术语?
A:通过领域微调或知识图谱注入,LLM能快速掌握专有名词。结合企业专属Prompt,准确率可达95%以上。
Q5:未来知识库将向何处发展?
A:向AI自学习、多模态融合、预测性服务演进。LLM智能助理将成为知识进化的核心引擎,实现从被动查询到主动推荐的跃升。
结语:拥抱LLM,让知识库真正“聪明”起来
LLM智能助理不仅能提升知识库的泛化能力,更能轻松解答未收录的相似问题,将知识从静态存储转变为动态生产力。在智能客服、内部协作和决策支持等领域,这一技术已帮助无数企业实现效率跃升和成本优化。
无论是财富投顾助手、公安反诈工具,还是工业运检管家,LLM驱动的知识库都在重塑服务范式。企业唯有主动拥抱这一变革,才能在数字化竞争中占据先机。
立即行动起来,构建属于自己的智能知识生态,开启知识管理的新时代!

延展阅读:







