随着人工智能技术的不断发展,DeepSeek模型以其强大的功能受到众多开发者和用户的关注。在Linux系统上部署DeepSeek模型,能够让用户充分利用Linux系统的稳定性和开放性等优势,挖掘DeepSeek模型的潜力。
然而,这个过程并非一帆风顺,需要考虑到环境要求、安装步骤以及后续的优化等多个方面。本文将详细介绍如何在Linux系统上部署DeepSeek模型,帮助用户顺利开启使用DeepSeek模型之旅。
文章导航
一、环境要求
1.操作系统
Linux系统是部署DeepSeek模型的推荐系统(当然也支持Windows系统)。不同的Linux发行版在操作步骤上可能会有细微差异,但整体的部署原理是相同的。
2.Python版本
需要确保系统中安装了Python 3.7及以上版本。Python是运行DeepSeek模型的重要基础,许多相关的库和工具都是基于Python开发的。
3.依赖包
要安装PyTorch(>=1.7.1)、Transformers(>=4.0),以及其他相关的库,如NumPy、pandas、scikit learn等。这些依赖包为DeepSeek模型的运行提供了必要的支持,例如PyTorch用于深度学习计算,Transformers有助于处理自然语言处理相关的任务等。
4.Ollama
还需要安装Ollama,这是运行DeepSeek模型的底层软件。它在模型的运行过程中起着关键的作用,就像是模型运行的“引擎”。
二、安装步骤
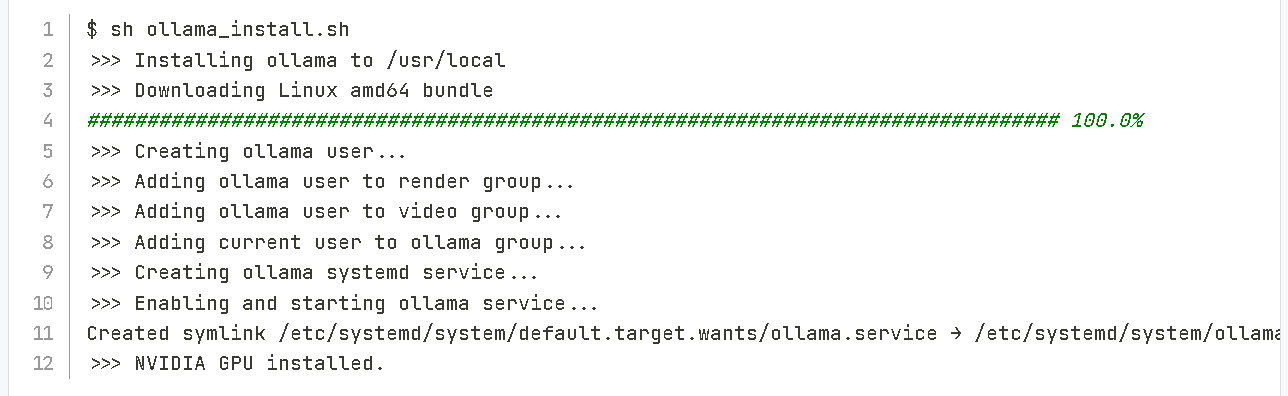
1.下载并安装Ollama
访问Ollama官网,选择适合自己Linux系统版本的Ollama进行下载。例如在Ubuntu系统下,可以通过命令行工具或者图形界面下载工具进行下载。下载完成后,按照安装向导进行安装。如果在安装过程中遇到权限问题,可以使用管理员权限(如在命令前加上sudo)进行安装。

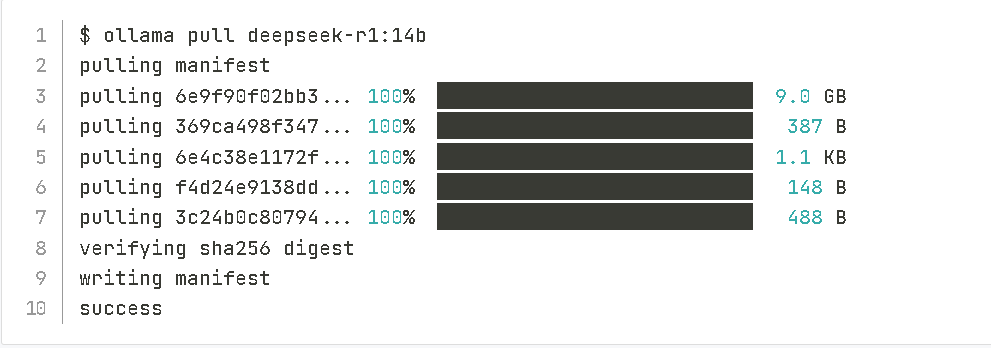
2.获取DeepSeek模型
根据具体的需求和硬件资源情况,选择合适的DeepSeek模型版本。可以从官方指定的渠道或者相关的开源社区获取模型文件。在获取模型文件后,需要将其放置在合适的目录下,方便后续的运行操作。
3.运行DeepSeek模型
在安装好Ollama并且获取到DeepSeek模型后,就可以通过命令行来运行模型了。例如,使用命令“ollama run [模型名称]”来启动DeepSeek模型。在模型运行过程中,要注意观察命令行输出的信息,查看是否有报错或者警告信息。如果出现问题,可以根据提示信息进行排查。
三、模型推理、压缩与优化
如果不需要对DeepSeek模型进行训练,只需要执行前向传播过程(即模型推理),基于深度学习特有性质进行高效的模型部署推理是除训练外很重要的系统问题。
模型推理相比训练有更低的延迟要求,更严苛的资源供给,不需要求解梯度和训练,有更低的精度要求等。可以通过模型压缩(如量化等手段)来精简计算量与内存消耗,加速模型的部署。这有助于提高模型在Linux系统上的运行效率,尤其是在资源有限的情况下。
四、测试与监控
在部署完成后,需要对系统进行测试和监控。可以使用一些性能测试工具来评估模型的运行效率,例如查看模型的响应时间、资源占用率等指标。
同时,要定期监控系统的运行状态,及时发现可能出现的问题,如内存泄漏、模型崩溃等。如果发现问题,可以根据具体情况进行调整,如优化模型参数、调整系统资源分配等。
通过以上步骤,就可以在Linux系统上成功部署DeepSeek模型,并且能够确保模型稳定、高效地运行,从而为用户的各种应用场景提供有力的支持。
延展阅读:







