在当今人工智能领域,DeepSeek R1和OpenAI o1都是备受瞩目的模型。随着技术的发展,人们越来越关注它们在性能上的表现。那么,DeepSeek R1与OpenAI o1在性能上究竟有哪些深度对比呢?
这是许多业内人士和使用者都十分关心的问题,因为这不仅关系到模型的优劣,也影响着在不同场景下的应用选择。
文章导航
一、训练方式与推理能力
在功能特性方面,DeepSeek R1采用了创新的训练方式,完全通过强化学习进行训练。这种训练方式激励模型自主开发高级推理能力,例如自我验证、反思和思维链推理。而OpenAI o1则可能采用了不同的训练策略和技术架构。这使得DeepSeek R1在推理能力的发展上有着独特的优势。
在仅有极少标注数据的情况下,DeepSeek R1通过后训练阶段大规模使用强化学习技术,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能已经能够比肩OpenAI o1正式版。
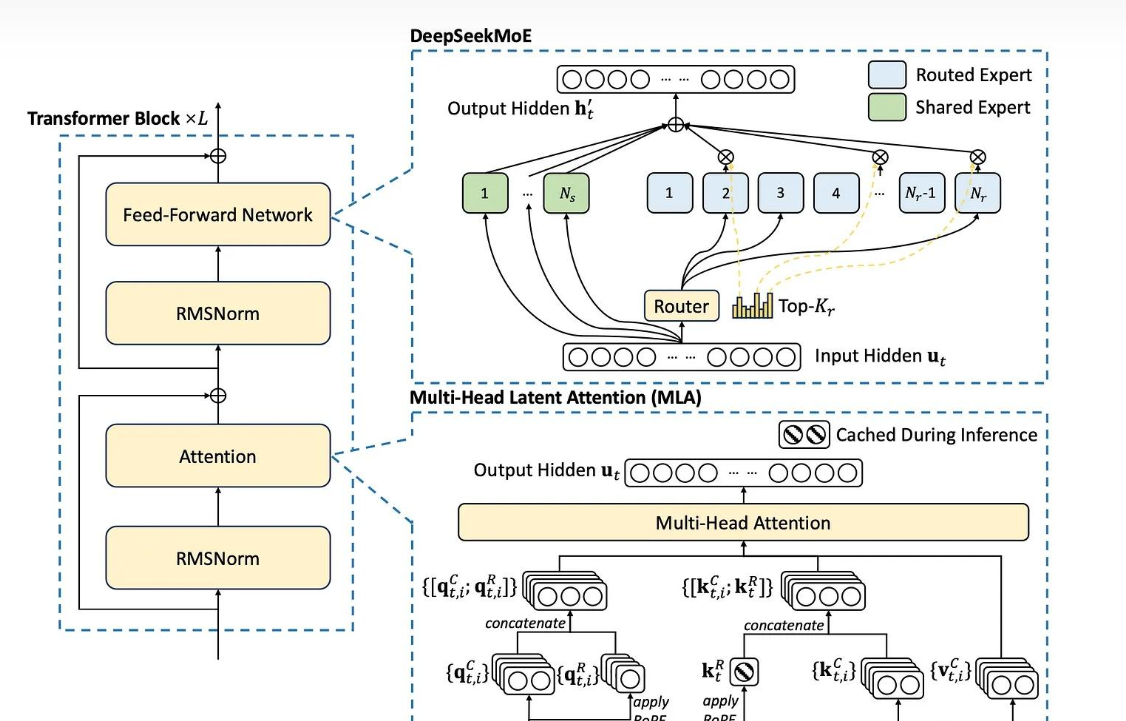

二、上下文长度支持
DeepSeek R1支持高达128k的上下文长度。这一特性在处理长文本时具有明显的优势,它能够更好地理解上下文信息,从而给出更准确、更连贯的回答。
相比之下,OpenAI o1在上下文长度支持方面可能存在一定的限制。不过,在超长文本处理上,DeepSeek R1虽然有128K的上下文窗口能满足大多数任务需求,但仍逊色于OpenAI o1。
三、特定任务中的准确率
在MMLU Pro任务中,DeepSeek R1的准确率达到84.0%,成功超越OpenAI o1 1217。这表明DeepSeek R1在自然语言推理的特定任务上,具备更强的处理能力。这一数据也证明了DeepSeek R1在特定领域的性能优势。
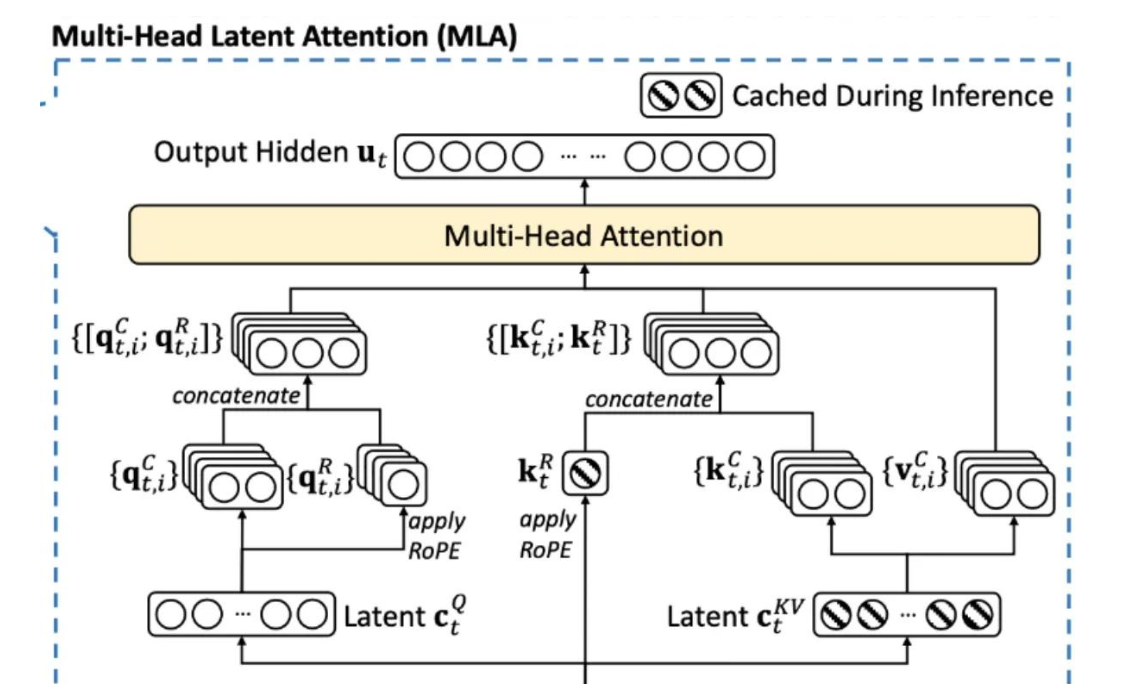
四、使用成本
DeepSeek R1还有一个显著的优势就是使用成本。DeepSeek R1极大降低了使用成本,比OpenAI o1低90%至95%。这对于许多需要考虑成本效益的企业和开发者来说是一个非常重要的因素。低成本意味着可以在更多的场景中应用,也能够让更多的用户有机会使用到这样的人工智能模型。
五、总结
总的来说,DeepSeek R1和OpenAI o1各有优劣。DeepSeek R1在训练方式带来的推理能力提升、特定任务的准确率以及使用成本方面表现出色,而OpenAI o1可能在超长文本处理等方面有自己的优势。
随着技术的不断发展,两者可能都会持续改进和优化,未来的性能对比也可能会发生新的变化。无论是企业还是个人用户,在选择使用哪个模型时,需要根据自身的需求,综合考虑这些性能方面的差异,从而做出最合适的决策。
延展阅读:
DeepSeek的响应速度,是否真的能达到每秒15-16 tokens?能但不是所有情况都能。







