随着人工智能技术的不断发展,大模型的训练方法也在持续创新。Deepseek-V3一经发布便引起了广泛关注,其采用的FP8训练更是成为焦点话题。
在众多大模型还在探索传统精度训练方法的时候,Deepseek-V3的FP8训练究竟有何独特之处?这种训练方式是如何在保证模型性能的同时,实现效率提升、成本降低等优势的呢?这一系列问题都值得我们深入探究。
文章导航
一、FP8训练在Deepseek-V3中的独特性
1.细粒度量化策略应对动态范围局限
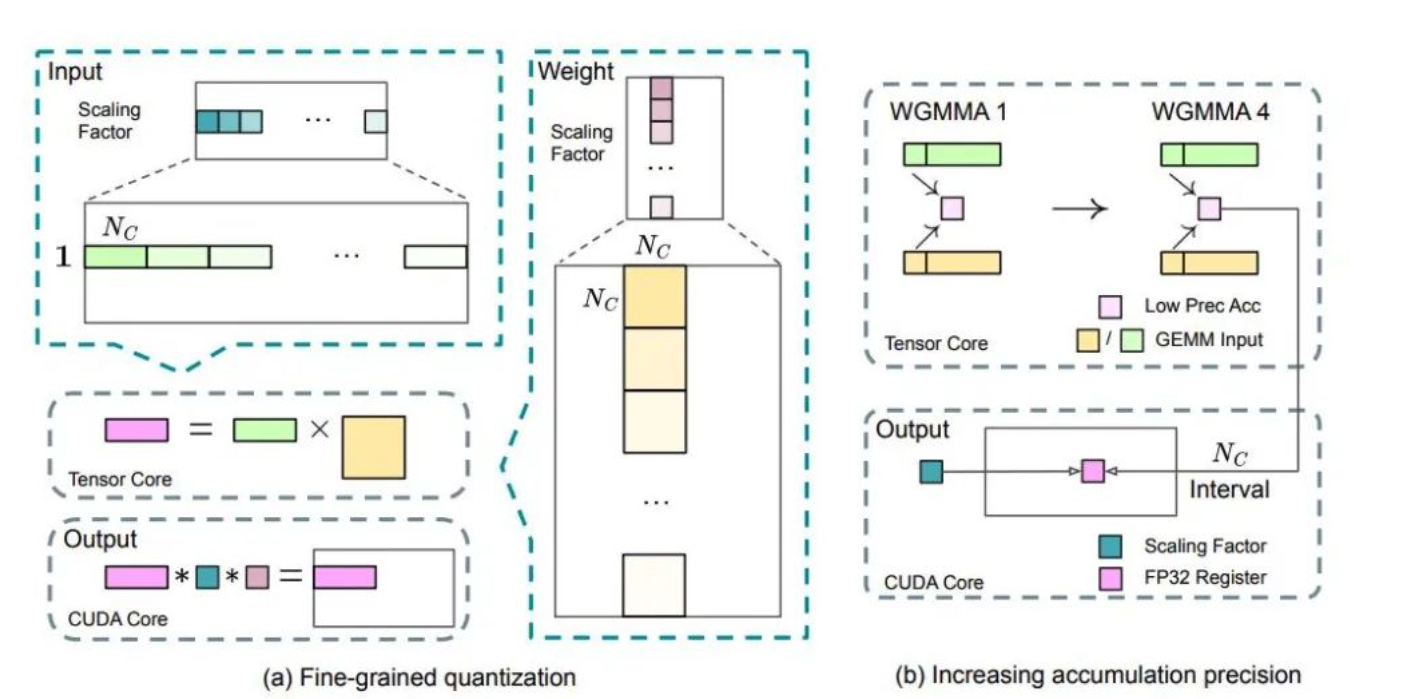
Deepseek V3验证了FP8混合精度训练的有效性。FP8格式存在动态范围局限的问题,而Deepseek-V3采用了元素条状和块状分组的细粒度量化策略。这种策略能够更精准地对数据进行量化处理。与其他简单的量化方式不同,它像是一把精准的手术刀,将数据进行细致的分组量化,从而更好地适应FP8格式的特点。
通过这种方式,可以有效缓解量化误差,使得模型在训练过程中能够保持较高的精度。例如,在与相近规模模型的对比验证中,FP8训练的相对损失误差控制在极小范围,这有力地证明了这种细粒度量化策略的可行性和有效性。
2.高精度累积技术的应用
除了细粒度量化策略,Deepseek-V3还结合了高精度累积技术。在FP8训练过程中,以𝑁𝐶 = 128个元素MMA的间隔转移到CUDA Cores进行高精度累加。这一技术就像是一个精准的校准器,在量化处理的基础上,进一步确保数据的准确性。
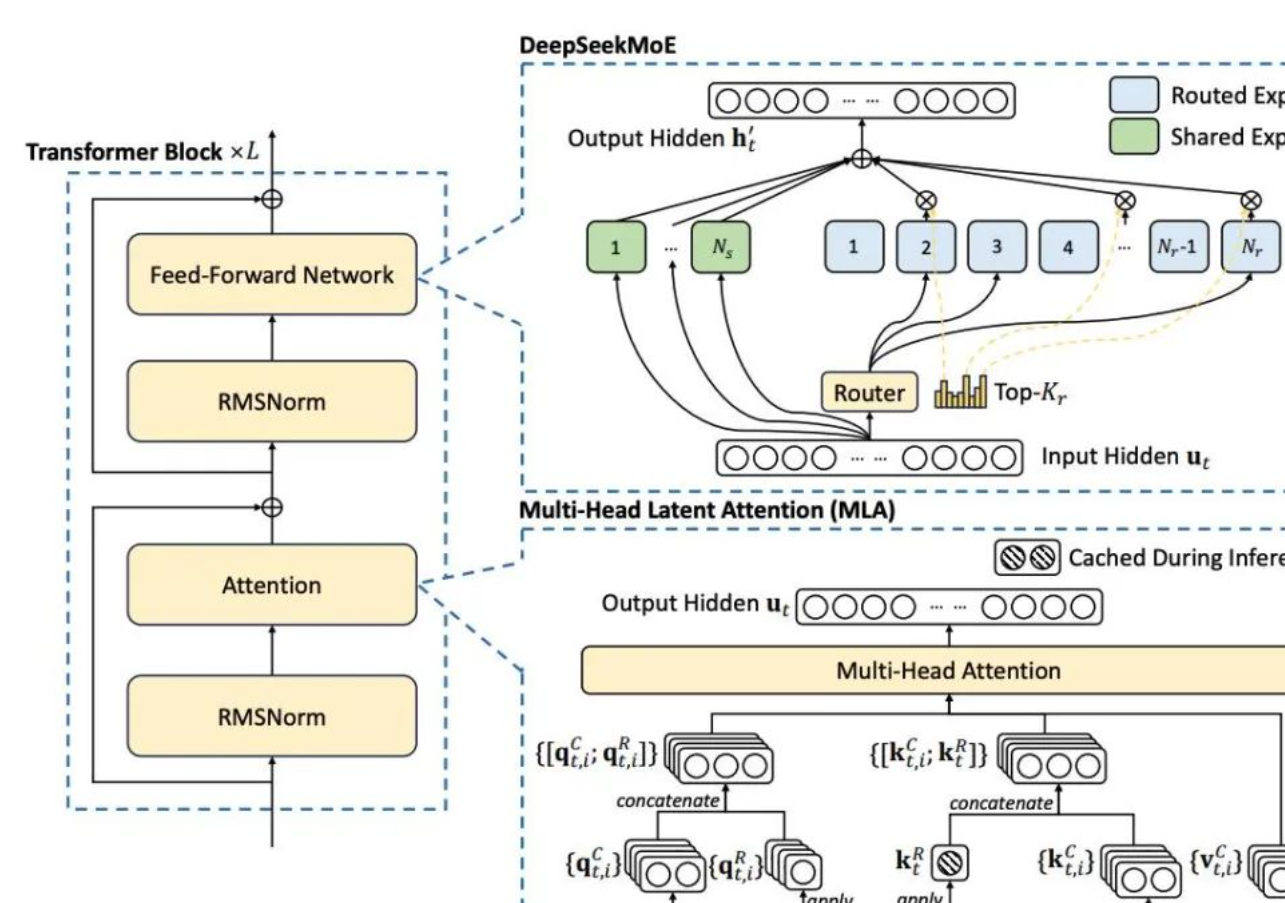

在模型训练中,每一个数据的准确性都至关重要,高精度累积技术能够避免因为低精度计算而导致的误差累积,从而提升整个训练过程的精度。
3.实现精度与效率的平衡
FP8是一种使用8位浮点数表示的格式,相比于传统的16位(FP16)和32位(FP32)浮点数,它是一种新兴的低精度训练方法。Deepseek-V3通过FP8混合精度训练,在保证模型精度的同时,大幅降低显存占用并提升训练速度。
在大模型训练中,显存占用一直是一个关键问题,过高的显存占用会限制模型的规模和训练效率。而Deepseek-V3的FP8训练能够有效解决这个问题,使得模型可以在更合理的显存占用下进行高效训练。同时,训练速度的提升也意味着可以更快地得到训练结果,缩短模型开发周期。
4.在超大规模模型上的可行性验证
研发团队设计了FP8混合精度训练框架,并首次在超大规模模型(如Deepseek-V3这个拥有671B(6710亿)总参数、37B(370亿)激活参数的混合专家(MoE)语言模型)上验证了FP8训练的可行性和有效性。
这一验证的成功为大模型训练开辟了新的道路。以往很多训练方法可能在小规模模型上表现良好,但在超大规模模型上会面临各种挑战,而FP8训练在Deepseek-V3上的成功应用,证明了它能够适应超大规模模型的复杂训练需求。
5.对硬件资源的优化利用
AMD Instinct GPU助力Deepseek V3的FP8精度训练,使其性能飞跃提升。FP8训练对硬件资源的利用有着独特的优势,它能够有效解决内存瓶颈和高延迟等问题。
例如,AMD ROCm平台对FP8的支持极大优化了计算过程,特别是推理性能的提升尤为显著。这意味着在硬件限制内可以运行更大模型或批次,提高了硬件资源的整体利用率,降低了训练成本。
二、结论
Deepseek V3的FP8训练在多个方面展现出独特之处。从细粒度量化策略到高精度累积技术,从精度与效率的平衡到超大规模模型上的可行性验证,再到对硬件资源的优化利用,这些独特之处共同构成了Deepseek V3在FP8训练方面的优势。
这种训练方式不仅提升了模型的性能,还在降低训练成本、提高训练效率等方面有着显著的成果。随着技术的不断发展,相信Deepseek V3的FP8训练经验也将为未来大模型训练提供更多的借鉴和启示。
延展阅读:
DeepSeek-V3开源后,开发者如何受益呢?其编程能力超越Claude了吗?







