在当今的人工智能领域,DeepSeek v3的发布犹如一颗重磅炸弹,仅用十分之一计算量就达到比肩Llama 3 405B的性能。这一惊人的成果背后,是其独特的架构创新在发挥着关键作用。
DeepSeek到底有着怎样的架构创新?这些创新又是如何推动它在AI领域取得如此卓越的成绩的呢?这一系列问题不仅吸引着众多AI研究者的目光,也成为广大AI爱好者关注的焦点。
文章导航
一、DeepSeek的架构创新点
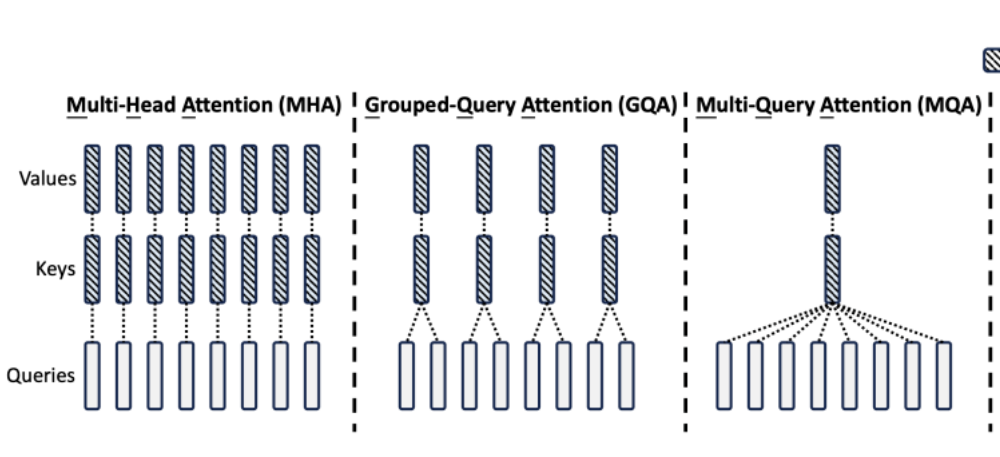
1.多头潜注意力(MLA)机制
DeepSeek首创的多头潜注意力(MLA)机制是其重要的架构创新之一。在处理长文本时,传统的模型往往面临着显存效率瓶颈的问题。而MLA机制的出现,成功攻克了这一难题。它能够大幅降低长文本推理成本,将显存占用降到了过去最常用的MHA架构的5%—13%。
这意味着在处理长文本时,模型能够更高效地利用显存资源,从而提高推理效率。例如,在一些需要对长篇文档进行分析、总结或者问答的场景中,MLA机制使得DeepSeek能够快速准确地处理文本内容,而不会因为显存不足而出现性能下降或者无法处理的情况。
2.混合专家模型(MoE)架构
混合专家模型(MoE)架构是DeepSeek的核心技术之一。在传统的模型中,当采用类似架构时往往会面临路由崩溃的难题。DeepSeek对MoE架构进行了创新,通过革新动态路由算法,成功突破了这一长期存在的专家选择困境。
这种创新使得模型在处理各种任务时能够更加智能地选择合适的专家模块,从而提高模型的性能。例如,在处理不同类型的自然语言处理任务时,如文本分类、机器翻译等,MoE架构能够根据任务的特点灵活地调用不同的专家模块,从而提高任务的处理效率和准确性。
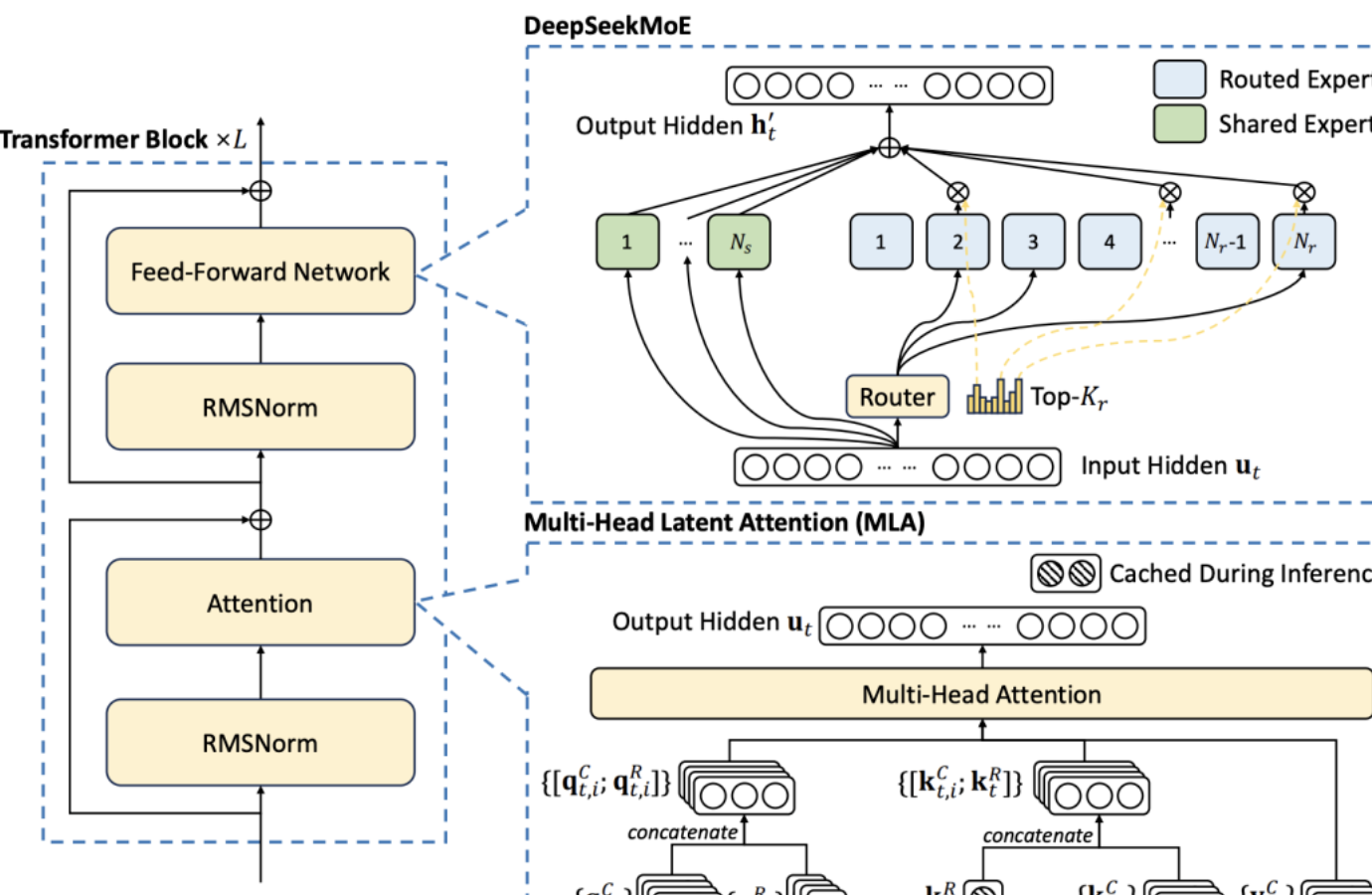

3.多令牌预测
多令牌预测是DeepSeek的另一大架构创新亮点。这一创新显著提升了推理速度。在传统的模型中,令牌预测的方式可能相对单一,导致推理速度受限。而DeepSeek的多令牌预测能够在一次预测中处理多个令牌,大大提高了模型的推理效率。
这就好比在一条生产线上,原本一次只能处理一个产品,现在可以同时处理多个产品,从而提高了整个生产流程的速度。在实际应用中,例如在实时对话系统中,多令牌预测能够让DeepSeek更快地生成回复,提高用户的交互体验。
二、架构创新的意义
DeepSeek的这些架构创新不仅仅是技术上的突破,更有着深远的意义。
从成本效益的角度来看,这些创新使得DeepSeek能够以较低的计算量达到很高的性能。这意味着在模型的训练和推理过程中,可以节省大量的计算资源,降低成本。对于企业和研究机构来说,这无疑是一个巨大的优势,能够让更多的人有机会使用到高性能的AI模型。
在推动AI技术发展方面,DeepSeek的架构创新为其他的AI研究提供了新的思路和方向。它展示了如何通过对传统模型架构的深入理解和创新改进,来提高模型的性能。这将激励更多的研究者在架构创新方面进行探索,推动整个AI领域的技术进步。
最后,从全球AI产业格局来看,DeepSeek的成功也改变了全球AI行业的竞争格局。它以中国的技术力量在国际AI舞台上崭露头角,与国际上的其他AI巨头形成竞争态势。同时,其开源策略也有助于推动AI技术的普及和应用,让更多的国家和地区能够受益于先进的AI技术。
三、总结
DeepSeek背后的架构创新是其取得卓越性能的关键所在。多头潜注意力(MLA)机制、混合专家模型(MoE)架构以及多令牌预测等创新点,从不同方面提升了模型的性能,降低了成本,并且对全球AI产业格局产生了重要影响。随着技术的不断发展,我们期待DeepSeek能够在未来继续创新,为AI领域带来更多的惊喜和突破。
延展阅读:
DeepSeek的技术创新是否能推动AI在更多领域的应用落地?是否能推进AI技术的进一步发展?







