在人工智能蓬勃发展的当下,DeepSeek V2作为一款备受瞩目的模型,其高效使用技巧对于充分发挥其潜力至关重要。无论是研究人员深入挖掘其功能,还是普通用户希望更好地借助其能力,掌握这些技巧都能带来极大的便利。本文将全方位解析DeepSeek V2的高效使用技巧,为大家开启更顺畅的使用之旅。
文章导航
一、DeepSeek V2简介
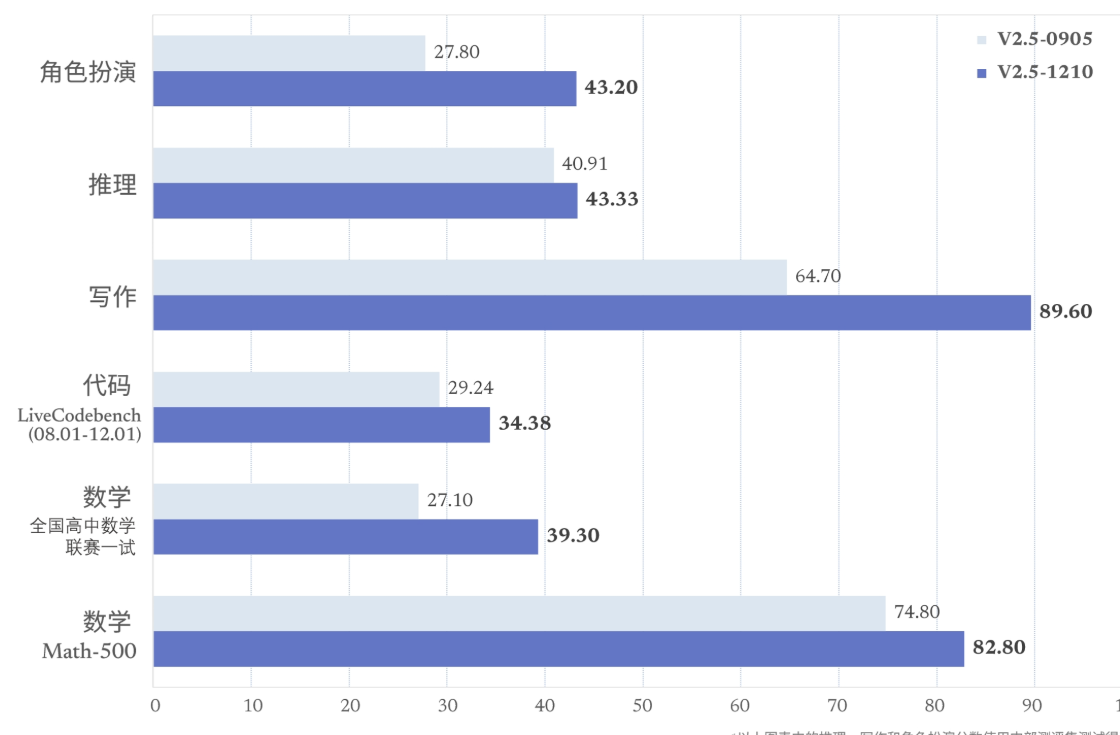
DeepSeek V2是幻方公司推出的MoE模型,它通过fine grained专家和共享专家技术,以及Device Limited Routing和MLA,实现了高效的计算和性能提升。这款模型在主流的大模型能力测试集上表现不俗,特别是在知识、数学、推理、编程方面能力处于前列,并且成本相对较低。

二、基础使用技巧
(一)模型加载
1. 命令行工具的使用
DeepSeek V2提供了多种便捷的操作方法,其中通过使用命令行工具,可以快速地加载模型。这就像是给模型开启了一条快速通道,能有效节省时间。例如,在特定的命令行指令下,模型能够迅速完成初始化,准备好进行后续的任务。
2. 了解硬件需求
在加载模型之前,要确保硬件满足要求。不同的任务可能对硬件有不同的需求,比如在处理大规模数据时,可能需要更高的内存和计算能力。对于DeepSeek V2来说,虽然它在性能优化方面做了很多努力,但如果硬件资源不足,也会影响其加载和运行的效率。
(二)数据处理
1. 数据格式的适配
在使用DeepSeek V2时,要确保输入的数据格式是模型能够识别的。这就需要对数据进行预处理,将其转换为合适的格式。例如,如果模型要求的数据是特定的编码格式,那么在输入之前就要进行相应的转换,否则可能会导致模型无法正确处理数据。
2. 数据量的控制
数据量过大可能会导致模型处理时间过长,甚至出现内存溢出等问题。因此,要根据实际需求合理控制数据量。可以采用数据采样等方法,在保证数据代表性的前提下,减少不必要的数据输入,提高模型处理的效率。
三、提高效率的高级技巧
(一)快捷操作方法
1. 快捷键的使用
就像在很多软件中一样,DeepSeek V2也可能存在一些快捷键,可以帮助用户更快速地执行某些操作。例如,在进行模型推理时,某个快捷键可能可以直接触发特定的功能,而不需要通过复杂的菜单操作。
2. 利用预训练模型
DeepSeek V2可能提供了一些预训练模型,这些模型已经在大量的数据上进行了训练,可以直接用于一些常见的任务。利用预训练模型可以节省大量的训练时间,并且在很多情况下能够取得较好的效果。用户可以根据自己的任务需求,选择合适的预训练模型进行微调或者直接使用。
(二)优化模型参数
1. 调整超参数
超参数的选择对模型的性能有着重要的影响。对于DeepSeek V2,用户可以根据具体的任务和数据特点,调整超参数的值。例如,学习率、批大小等超参数的合理调整,可以使模型更快地收敛,提高训练效率。
2. 模型剪枝
模型剪枝是一种减少模型复杂度的方法。通过去除模型中一些不重要的连接或者神经元,可以降低模型的计算量,同时保持模型的性能。对于DeepSeek V2这样的大型模型,模型剪枝可以有效地提高其推理效率。
四、与DeepSeek V2的交互技巧
(一)编写有效的提示词
1. 明确任务目标
在与DeepSeek V2交互时,编写的提示词要明确表达任务的目标。例如,如果是要求模型进行文本生成,要明确指出生成的主题、风格、字数等要求。清晰的提示词能够让模型更好地理解用户的需求,从而给出更符合期望的结果。
2. 参考成功案例
可以参考一些已经成功使用DeepSeek V2的案例中的提示词写法。这些案例中的提示词往往经过了实践的检验,能够有效地与模型进行交互。通过学习和借鉴,可以提高自己编写提示词的能力。
(二)处理模型的输出
1. 结果的筛选和评估
DeepSeek V2的输出可能包含多个结果或者存在一定的不确定性。用户需要对模型的输出进行筛选和评估,选择最符合需求的结果。可以根据一些评估指标,如准确性、合理性等,来判断结果的质量。
2. 反馈机制的利用
如果模型的输出不符合预期,用户可以利用反馈机制向模型提供反馈。这样模型可以根据反馈信息进行调整,提高下一次输出的质量。
掌握DeepSeek V2的高效使用技巧需要从多个方面入手,包括基础使用、高级技巧以及交互技巧等。通过不断地学习和实践,用户能够更好地发挥DeepSeek V2的潜力,让其在各种任务中发挥出更大的价值。
延展阅读:







