在当今人工智能领域的激烈竞争中,DeepSeek R1的出现犹如一颗重磅炸弹,引起了广泛的关注。当我们深入拆解其架构时,就如同打开了一个装满宝藏的盒子,里面的一些设计堪称“核弹级”,这些设计正在重新定义大模型竞争的规则,让我们看到了人工智能模型架构创新的无限潜力,它们不仅仅是技术上的突破,更可能是引领未来人工智能发展方向的关键因素。
文章导航
一、核弹级设计剖析
(一)创新的多头潜在注意力机制(MLA)
1. 高效处理长序列数据
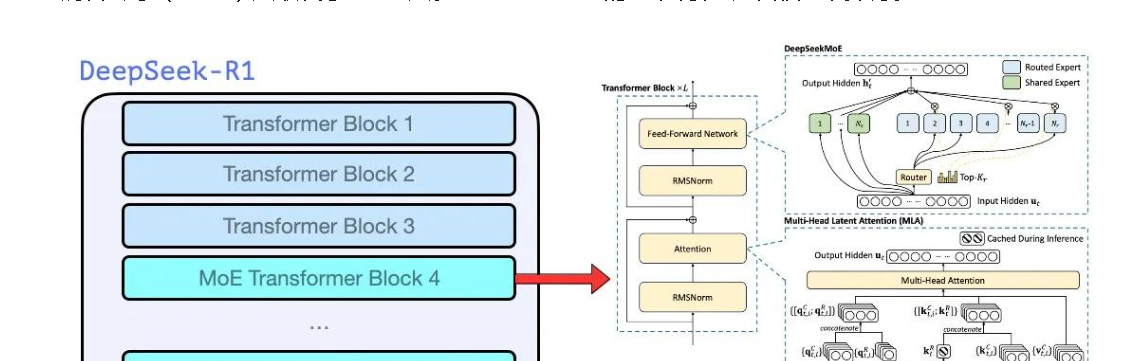
DeepSeek R1采用的多头潜在注意力机制(MLA)是其架构中的一大亮点。在处理长序列数据时,传统的模型往往会面临效率低下的问题。
而MLA能够巧妙地提炼冗长数据的关键要素,就像是一个经验丰富的编辑,从长篇大论中迅速抓取核心内容。例如在处理一篇很长的文档或者复杂的代码序列时,MLA可以快速识别出其中的关键信息,这对于提升模型性能有着至关重要的作用。

2. 降低计算资源消耗
除了高效处理长序列数据外,MLA还能降低计算资源的消耗。在人工智能模型的运行过程中,计算资源的消耗是一个不可忽视的成本。MLA通过其独特的机制,在提升模型性能的同时,避免了不必要的计算资源浪费。这意味着在相同的硬件条件下,采用MLA的DeepSeek R1能够处理更多的任务,或者在处理相同任务时能够更快地得出结果。
(二)专家模型混合架构(MoE)
1. 任务分配给不同“专家”模块
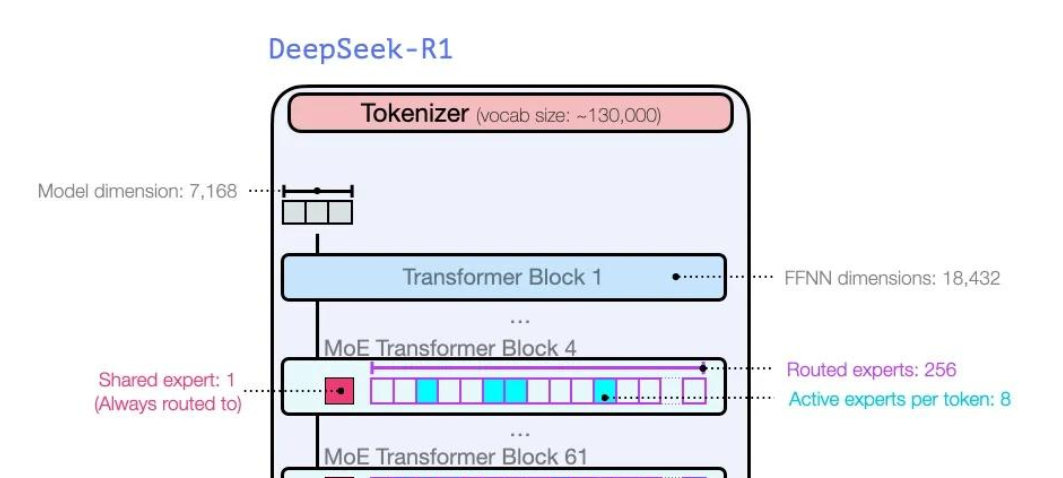
专家模型混合架构(MoE)也是DeepSeek R1架构中的核弹级设计。MoE将任务分配给不同的“专家”模块,这些专家模块就像是各个领域的专业人才。例如,在DeepSeek R1架构中包含16个专家网络,每个专家专注于数学、代码、逻辑等不同领域。
当模型接收到一个任务时,会根据任务的类型将其分配到最适合的专家模块进行处理。这种分工协作的方式,避免了重复计算,大大提高了模型的运行效率。
2. 动态激活机制实现高效推理
每个专家模块通过动态激活机制,每个token激活37B参数,从而实现高效的推理能力。
这种动态激活机制就像是一个智能的调度系统,根据任务的具体需求,精准地激活相应的参数,使得模型在推理过程中能够快速准确地得出结果。
(三)独特的训练方式,完全依赖强化学习(RL)
1. 自主发现推理模式
DeepSeek R1的核心创新在于其训练方式,它完全依赖强化学习(Reinforcement Learning, RL)来提升模型的推理能力,而不使用任何监督微调(Supervised Fine Tuning, SFT)数据。
这种训练方式使得模型能够像一个自我探索的学习者,自主发现推理模式,而不是依赖人工策划的示例。这是一种非常大胆且具有前瞻性的训练方式,在人工智能模型训练领域开辟了一条新的道路。
2. 在不同任务中的卓越表现
这种独特的训练方式让DeepSeek R1在数学、代码和自然语言推理等任务上取得了卓越的表现。
例如在数学计算任务中,模型能够通过不断的自我强化学习,准确地计算出复杂的数学公式;在代码编写任务中,能够根据任务需求生成高效准确的代码;在自然语言处理任务中,能够更好地理解语义并生成合理的回复。
二、结论
DeepSeek R1架构中的这些核弹级设计,无论是多头潜在注意力机制(MLA)、专家模型混合架构(MoE)还是独特的强化学习(RL)训练方式,都为人工智能模型的发展提供了新的思路和方向。
这些设计在提升模型性能、提高运行效率以及拓展应用场景等方面都有着不可忽视的作用。随着技术的不断发展,我们有理由相信DeepSeek R1将在人工智能领域发挥更加重要的作用,并且会激发更多的研究人员在模型架构创新方面进行探索。
延展阅读:
DeepSeek官方App无响应,有哪些应对方法?不要慌!教你逐步排查和解决问题!







