在当今人工智能领域,DeepSeek-R1模型作为DeepSeek团队推出的一款重要大语言模型,正逐渐崭露头角。它旨在通过强化学习提升大型语言模型的推理能力,这一特性使其在众多模型中独具特色。然而,要充分发挥DeepSeek-R1模型的优势,我们不仅需要深入解读它的模型架构和特点,还需要掌握其微调技巧。无论是对于科研人员探索模型的更多潜力,还是开发者将其应用于实际项目中,了解DeepSeek-R1模型的解读与微调技巧都至关重要。
文章导航
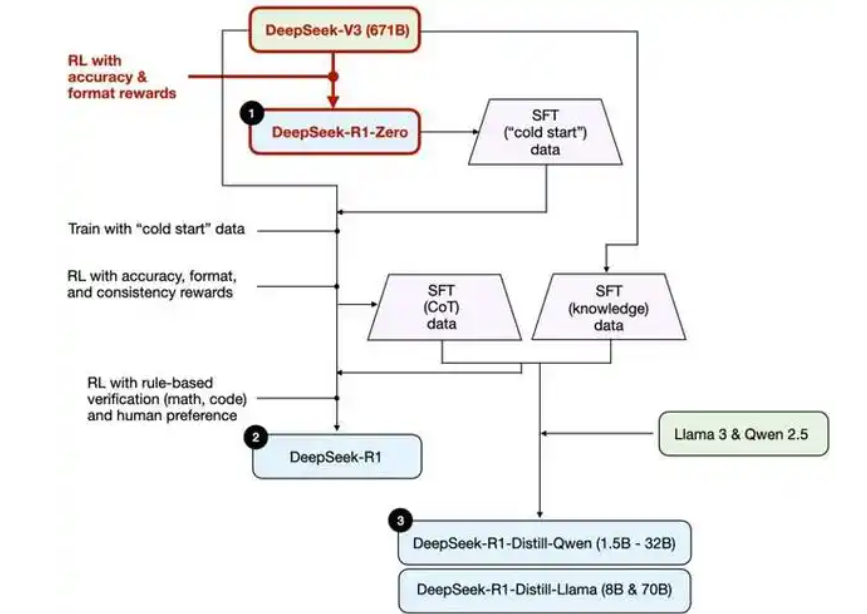
一、DeepSeek-R1模型架构解读
1. DeepSeek-R1-Zero
DeepSeek-R1-Zero是DeepSeek团队推出的第一代推理模型。它完全依靠强化学习(RL)训练,不依赖任何监督微调(SFT)数据。这种独特的训练方式使其展现出强大的推理能力,例如自我验证和长链推理。但是,这种纯强化学习训练的模型也存在一些问题,如可读性差和语言混杂等。
2. 多阶段训练流程
DeepSeek-R1为了解决上述问题,引入了多阶段训练流程。使用冷启动数据对基础模型进行微调。然后,结合推理导向的强化学习(RL)和监督微调(SFT)。这种混合的训练方式有助于提高模型在不同任务上的性能。


二、DeepSeek-R1模型的使用技巧
1. 适应思维逻辑
有不少用户反映使用DeepSeek-R1时,不太习惯它的思维逻辑。这可能是因为其独特的训练方式和架构。对于使用者来说,需要花费一定的时间去理解和适应模型的输出方式,多进行交互和测试,以便更好地利用它的推理能力。
2. 特定任务上的调参策略
(1)选择适当的预训练模型
在开始特定任务之前,选择一个适合的预训练模型作为基础是非常关键的。预训练模型的选择可以考虑该模型在相关领域的性能、规模大小、训练数据集的相似性等因素。
例如,如果是进行自然语言处理中的文本分类任务,就可以选择在大规模文本分类数据集上预训练过的DeepSeek-R1模型版本,这样能够提高模型在该任务上的初始性能。
(2)冻结部分层进行微调
对于大型预训练模型,如DeepSeek-R1,可以冻结部分层(通常是底层或中间层)的参数,只微调模型的顶层或添加的新层。这样做的好处是可以减少计算量,同时避免过度调整已经在大规模数据上预训练好的底层特征,防止模型过拟合。
例如,在图像识别任务中,底层的卷积层往往学习到的是通用的图像特征,如边缘、纹理等,这些特征在不同的图像识别任务中具有通用性,所以可以冻结底层卷积层,只对上层的全连接层进行微调,以适应具体的分类任务。
3. 数据收集与微调
在推理导向的强化学习收敛后,可以利用检查点收集监督微调(SFT)数据,增强模型在写作、角色扮演等任务的能力。例如,通过收集约80万条样本对DeepSeek-V3 (这里可能是相关版本)进行微调,可以显著提升模型在特定任务上的表现。
三、总结
DeepSeek-R1模型以其独特的强化学习训练方式和多阶段的训练流程在大语言模型领域占据一席之地。虽然它存在一些如可读性差等问题,但通过合适的使用技巧,如适应其思维逻辑、合理选择预训练模型、冻结部分层进行微调以及有效收集数据进行监督微调等,可以在很大程度上发挥其优势,提高其在各种特定任务上的性能。随着对DeepSeek-R1模型研究的不断深入,相信未来会有更多优化和应用的可能。
延展阅读:







