文章导航
什么是Xmodel-LM?
Xmodel-LM是一种由晓多的科学家和工程师团队精心开发的电脑程序,能够理解和生成自然语言。尽管程序本身体积不大,但其性能却极为出色。
训练Xmodel-LM的过程
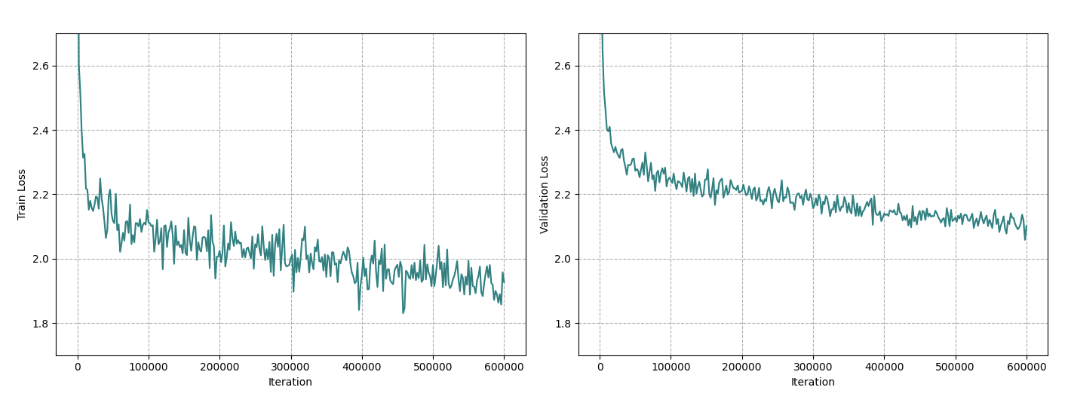
为了让Xmodel-LM变得更加聪明,晓多的科学家们使用了大量数据进行训练,总计约2万亿个单词,涵盖了中文和英文等多种语言,这些训练数据来源也很广泛,包括书籍、网络文章、学术论文等等。
为了确保训练的高效性,晓多的科学家们还对这些数据进行了严格的筛选和质量控制。通过使用叫“分词器”的工具,将数据被转换成了计算机能够理解的格式,这个过程就像是将一本书籍细致地分解成易于学习的小片段。此外,在训练Xmodel-LM的过程中,科学家们动用了强大的计算设备,模型在训练中可以不断调整自己的参数,这一过程可以类比于学生在备考中不断优化答题技巧。经过这样严谨和深入的训练,Xmodel-LM最终在众多任务中展现出色的表现,无论是回答问题还是撰写文章,它都能够处理得游刃有余。

Xmodel-LM的优势
通过观察Xmodel-LM在各类测试中的表现,我们可以清晰地看到其在自然语言处理(NLP)领域的众多优势。以下是Xmodel-LM在技术和应用性能方面的主要优势亮点:
- 紧凑且高效:Xmodel-LM 是一个紧凑高效的1.1B语言模型,训练数据量大约为2万亿个tokens,尽管模型规模较小,但其性能具有竞争力。
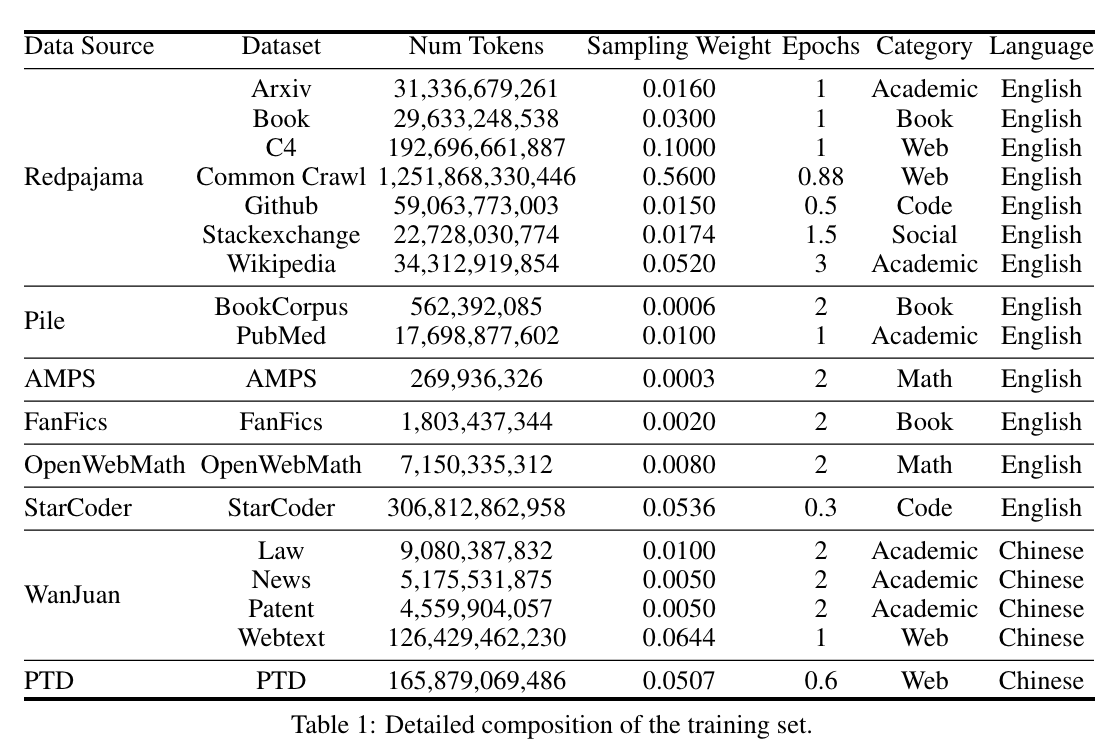
- 双语平衡语料库:模型预训练使用自建的Xdata数据集,该数据集平衡了中文和英文语料。这种平衡的预训练方法确保了模型在两种语言上的出色表现,使其在多语言应用中非常有优势。
- 多任务高性能:
- 问题解决能力:在问题解决任务中表现出色,特别是在BIG-Bench Hard (BBH)基准测试中表现优异,整体上与其他同规模模型相比竞争力强。
- 常识推理:在常识推理任务中超越了多个基线模型,展示了其理解和执行复杂指令的能力。
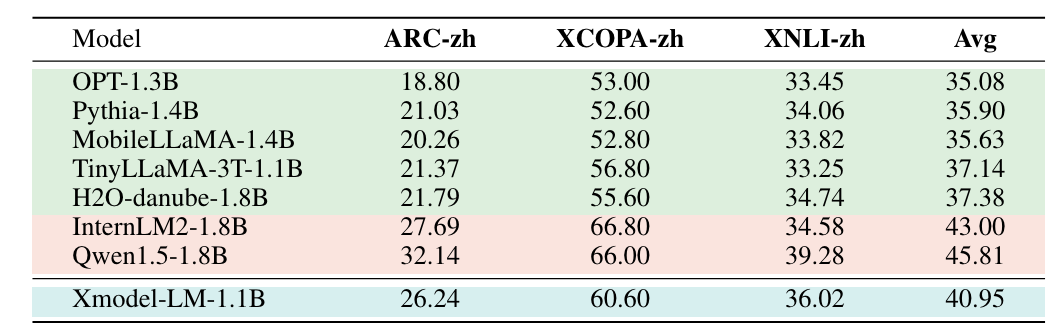
- 中文处理能力:在中文任务中的表现优于多个其他模型,证明了其理解和生成中文文本的能力。
- 先进的模型架构:Xmodel-LM 的架构包括旋转位置嵌入(RoPE)、RMSNorm(提高稳定性)、SwiGLU激活函数和分组查询注意力等特性,这些优化了模型的性能和效率。
- 从记忆到泛化:在训练过程中,模型从记忆过渡到泛化,这通过参数的L2范数变化反映出来。这表明模型能够有效地从训练数据中进行泛化。
这些优势使得Xmodel-LM在各种自然语言处理任务中表现出色,能够在多种语言之间平衡性能,并在问题解决和常识推理方面展示出强大的能力。
总结
Xmodel-LM作为一款体积小巧却性能卓越的语言模型,为智能客服机器人等产品提供了理想的基座。它的出现使得晓多能够以更低的成本,训练出性能出色的智能系统。这种成本效益的优化让晓多能够更加专注于深入理解商家的需求,从而定制开发出真正属于客户的专属模型,使得机器人在回复中更加准确、个性化以及拟人化。此外,Xmodel-LM的多语言处理能力,也能帮助商家跨越语言障碍,实现更大范围内的客户服务。







