文章导航
一、量化评测集
复杂推理类
GSM8k
GSM8K 是OpenAI 2021年创建的8.5K 高质量小学数学应用题数据集。数据集分为7.5K 训练问题和1K 测试问题。这些问题需要2 到8 个步骤来解决,解决方案主要涉及使用基本算术运算(+ − ×÷) 执行一系列基本计算以得出最终答案。一个聪明的中学生应该能够解决所有问题。


- 官网:https://github.com/openai/grade-school-math
- 论文:https://arxiv.org/abs/2110.14168
GSM8k的评测又分成有和没有计算器两类。
代码位置分别为:
- 无计算器:Experiments\llm_gsm8k
- 有计算器:Experiments\llm_gsm8k_use_calculator
HumanEval
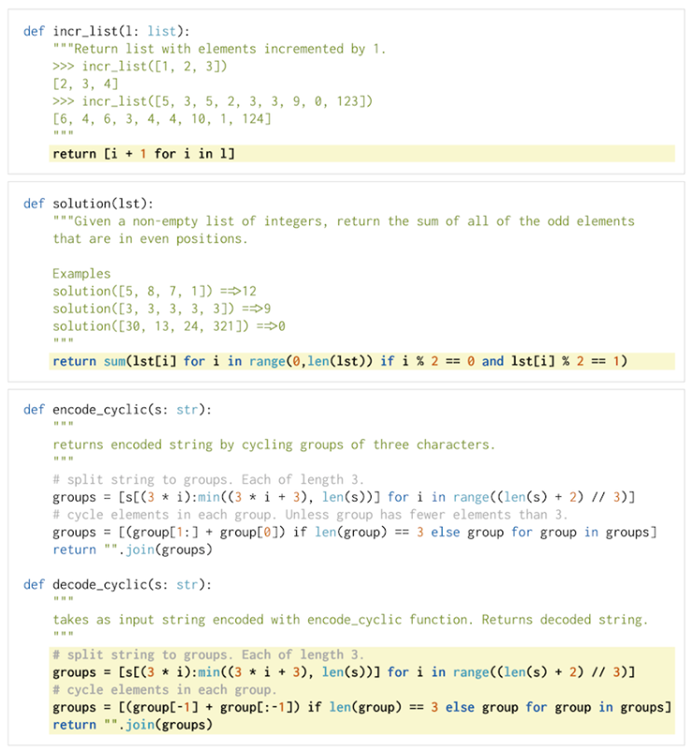
HumanEval是一个用于评估代码生成模型性能的数据集,由OpenAI在2021年推出。 这个数据集包含164个手工编写的编程问题,每个问题都包括一个函数签名、文档字符串(docstring)、函数体以及几个单元测试。这些问题涵盖了语言理解、推理、算法和简单数学等方面。
ToM
心智理论 (ToM) 是我们推理他人思想中正在发生的事情的独特能力,包括他们想要什么(欲望)、他们知道什么(知识)以及他们根据之前的经验(信念)认为正确的事情).
我们每天都在使用我们的“读心术”能力,例如当我们玩捉迷藏时,在下棋时猜测对手的下一步行动,或者弄清楚朋友为什么难过。重要的是,“读心术”并不意味着我们总能准确地读懂他们的思想;相反,我们使用我们对人们的想法和感受的直觉理解来推断他们的想法。
“错误信念任务(false-belief task)”经常被用来探索儿童心智理论的发展。在 Wimmer 和 Perner (1983) 对幼儿的这种能力进行首次测试后,许多版本的错误信念任务已用于学龄前儿童(现在有用于婴儿的这些任务的非语言版本!)。这是错误信念任务的示例:
作为成年人,我们知道约翰对巧克力棒的位置有错误的看法——他认为它在桌子上,尽管它已经不在了。然而,如果你给一个 3 岁的孩子展示同样的情况,他或她可能会告诉你约翰会认为巧克力在抽屉里。
这是因为年幼的孩子通常难以持有两种截然不同的观点——即“我认为巧克力在抽屉里,因为我刚刚看到安娜把它放在那里”和“约翰认为巧克力在桌子上,因为他把它放在那里并且不知道安娜来过”——同时在他们的脑海中,尤其是当他们知道世界的真实状况时。

Theory of Mind(ToM)是对大模型进行心智能力测试的评估集,共有40个题目。
补充:个人观点这个心智能力就是“共情”的能力。辜鸿铭说《中国人的精神》是“温良”,就是说共情的能力高:“老吾老以及人之老,幼吾幼以及人之幼”,不愿意轻易伤害别人。
MATH
MATH 是一个包含 12,500 个具有挑战性的数学竞赛问题的新数据集。 MATH 中的每个问题都有一个完整的逐步解决方案,可用于教模型生成答案推导和解释。

官网:https://github.com/hendrycks/math
论文:https://arxiv.org/abs/2103.03874
代码:Experiments\llm_math
注释:MATH 数据集用LaTex表述公式,评测时用Sympy对公式做了归一化。
MMLU
MMLU(大规模多任务语言理解)旨在通过仅在零样本和少样本设置中评估模型来衡量预训练期间获取的知识。该基准涵盖 STEM、人文、社会科学等领域的 57 个学科。它的难度从初级到专业高级,既考验世界知识,又考验解决问题的能力。

- 官网:https://github.com/hendrycks/test
- 论文:https://arxiv.org/abs/2009.03300
- 代码:Experiments\llm_mmlu
BBH
BIG-Bench 是一个多样化的评估套件,专注于被认为超出当前语言模型能力的任务。Google 研究人员基于 BIG-Bench 挑选出 23项具有挑战性的 BIG-Bench 任务,称为 BIG-Bench Hard (BBH)。对于这些任务,先前的语言模型评估结果低于优于人类平均水平。

- 官网:https://github.com/suzgunmirac/BIG-Bench-Hard
- 论文:https://arxiv.org/abs/2210.09261
- 代码:Experiments\llm_bbh
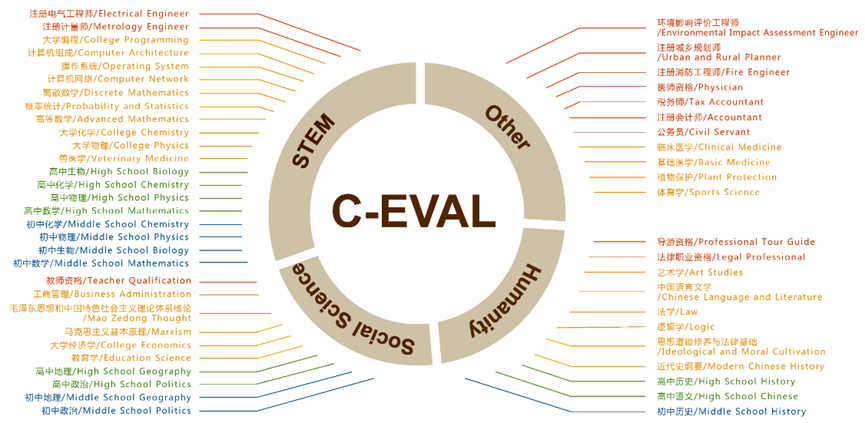
C-EVAL
C-Eval是一个针对基础模型的综合中文评估套件。它由 13948 道多项选择题组成,涵盖 52 个不同学科和四个难度级别。
- 官网:https://cevalbenchmark.com/
- 论文:https://arxiv.org/abs/2305.08322
- 代码:Experiments\llm_ceval
多模态类
VQAv2
VQA是一个视觉问答数据集,包含有关图像的开放式问题。这些问题需要对视觉、语言和常识知识的理解才能回答。

- 官网:https://visualqa.org/
- 论文:https://arxiv.org/pdf/1612.00837.pdf
- 代码:Experiments\llm_vqav2
OK-VQA
OK-VQA是更难的视觉问答数据集,它需要利用外部知识来回答关于图像的问题。

- 官网:https://okvqa.allenai.org/
- 论文:https://arxiv.org/pdf/1906.00067.pdf
- 代码:Experiments\llm_ok_vqa
TextVQA
TextVQA 要求模型能够读取和推理图像中的文本,以回答有关问题。具体来说,模型需要结合图像中存在的文本并对其进行推理以回答问题。

what brand liquor is on the right?
- 官网:https://textvqa.org/
- 论文:https://arxiv.org/abs/1904.08920
- 代码:Experiments\llm_textvqa
ChartQA
图表在分析数据时非常流行。在探索图表时,人们经常会提出各种复杂的推理问题,其中涉及多种逻辑和算术运算。
- 官网:https://github.com/vis-nlp/ChartQA
- 论文:https://arxiv.org/pdf/2203.10244v1.pdf
- 代码:cv_research\Experiments\llm_chartqa
DocVQA
DocVQA 是一个关于文档图像信息提取的开放式问答数据集。该数据集需要对文档进行理解和推理才能正确回答。
- 官网:https://www.docvqa.org/
- 论文:涉及论文多篇,在这里:https://www.docvqa.org/publications
- 代码:Experiments\llm_docvqa
Agent 能力类
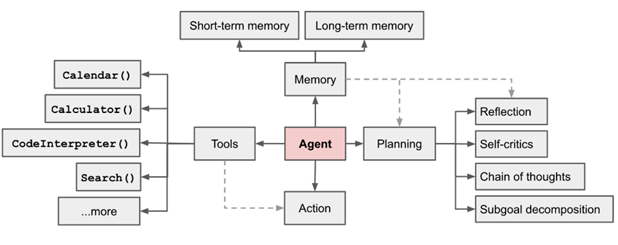
参考文章:https://lilianweng.github.io/posts/2023-06-23-agent/
参考架构图:
HotpotQA
HotpotQA 是一个问答数据集,以自然、多跳(multi-hop)问题为特色,对支持事实进行强有力的监督,以实现更可解释的问答系统。

- 官网:https://hotpotqa.github.io/
- 论文:https://arxiv.org/abs/1809.09600
- 代码:Experiments\llm_react
Fever
FEVER(事实提取和验证)由 185,445 条语句组成,这些语句是通过更改从维基百科提取的句子而生成的,随后在不知道它们来源的情况下进行了验证。这些声明被分类为“Supported”、“Refuted”或“NotEnoughInfo”。对于前两类,标注者还记录了句子,为判断提供了必要的证据。
- 官网:https://fever.ai/dataset/fever.html
- 论文:https://arxiv.org/abs/1803.05355
- 代码:Experiments\llm_react
ALFWorld
ALFWorld 包含交互式 TextWorld 环境,与 ALFRED 数据集中的具体世界并行。一致的环境允许智能体在通过底层驱动解决具体任务之前在抽象空间中推理和学习高级策略。

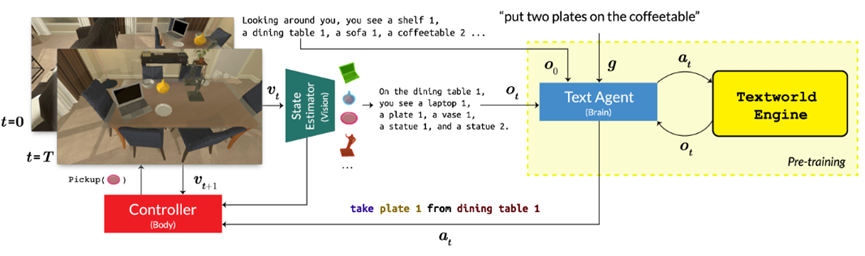
- 官网:https://alfworld.github.io/
- 官网:https://github.com/alfworld/alfworld
- 论文:https://arxiv.org/abs/2010.03768
- 代码:Experiments\llm_react
WebShop
WebShop是一个模拟的电子商务网站环境,拥有118万种真实产品和12,087条众包文本指令。在这种环境中,智能体需要在多种类型的网页之间导航并发出不同的操作,以根据指令查找、定制和购买产品。
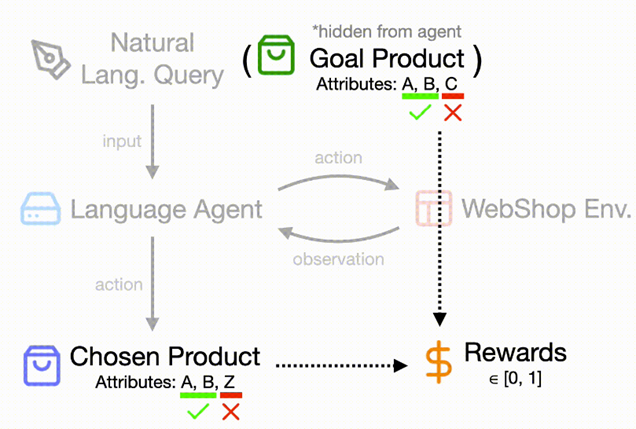
官网:https://github.com/princeton-nlp/WebShop
代码:Experiments\llm_react
Mind2Web
Mind2Web 是第一个用于开发和评估网络通用智能体的数据集,它可以遵循语言指令在任何网站上完成复杂的任务。
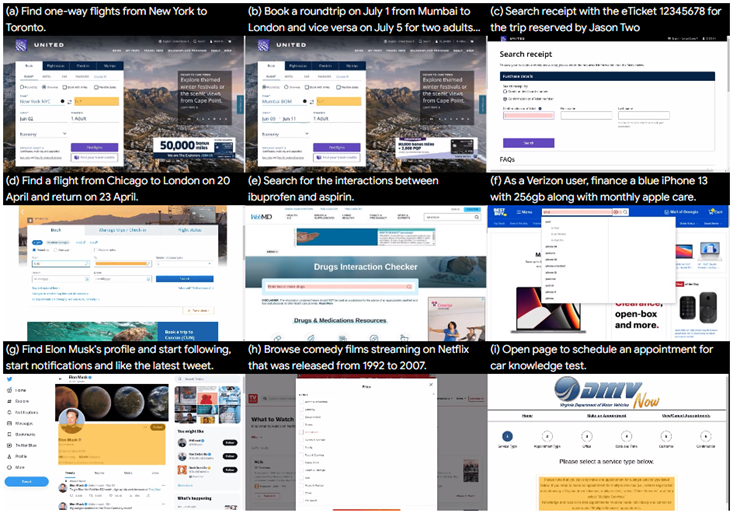
- 官网:https://github.com/OSU-NLP-Group/Mind2Web
- 论文:https://arxiv.org/abs/2306.06070
- 代码:Experiments\llm_mind2web
如果您想了解更多关于大模型复杂推理测评集之下相关程序运用,可以点击这里查看更多信息。







