文章导航
背景
对于一家店铺(如石头科技),建立动态可增减的标准Q列表。对于一个输入消费者Q,需要快速识别,将其分类到一个现成的标准Q。
思考
这个任务跟人脸识别有相似性(对象分类但类别列表动态可变),考虑可否借鉴人脸识别领域的主流算法 ArcFace。
| 行业细分问题 | 人脸识别问题 | |
| 识别对象 | 消费者Q | 人脸照片 |
| 识别目标 | 标准Q | 注册人脸 |
| 嵌入(embedding)维度 | 768、1024、1536等 | 512 |
| 相似度度量 | 余弦相似度 | 余弦相似度 |
| 预训练模型 | BERT、Roformer等 | ImageNet 预训练 |
| 训练数据 | 同行业跨公司的语料数据 | 百万级照片起步 |
假设:只看单句。
形式化
基本思路是将消费者Q 和 标准 Q 通过 embedding 模型映射到特征空间,通过计算两两 embedding 的余弦相似度来度量语义距离。核心是下面虚线框中的 embedder 模型,假设从预训练的语言模型开始,如何用有限的数据进行微调,以使得 embedder 模型在对消费者 Q 进行嵌入和分类时得到更好的表现:
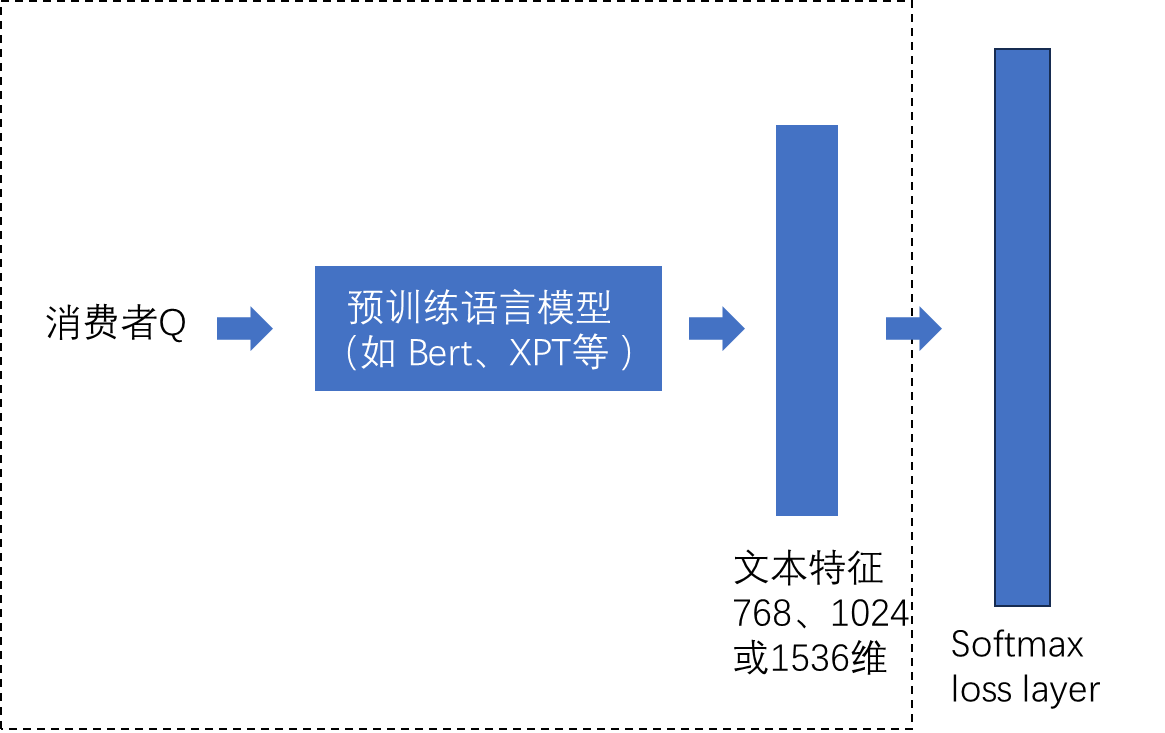

数据准备
假设我们有 N(如 53)个标准Q,同时使用数据增强的方式(例如使用ChatGPT)为每个标准Q扩增100个语义相似的文本。
标准Q的扩增,例如去掉实体主语(扫地机洗地机),给ChatGPT API下达指令,由ChatGPT进行数据增强:

Loss
那么我们可以使用 softmax / cross-entropy loss 对模型进行训练。Softmax能使不同类的特征分开,但不会分开太多:
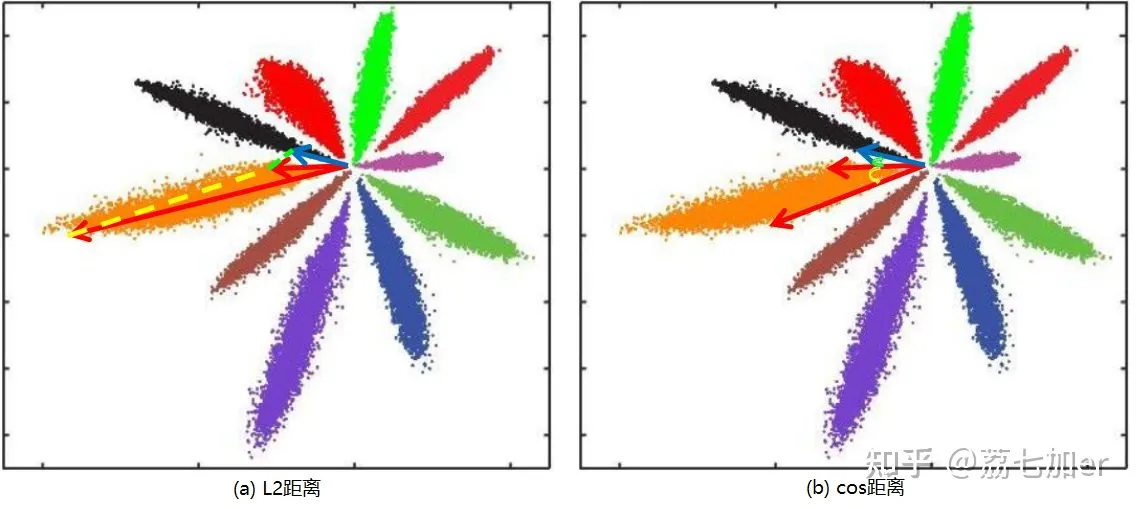
Softmax仅要求分类正确,不要求类内紧凑和类间距离,这一点不适合标准Q识别任务,标准Q识别的关键是得到泛化能力强的feature,与分类能力不是完全等价的。
总结来说:
- Softmax训练的深度特征,会把整个超空间或者超球,按照分类个数进行划分,保证类别是可分的,这一点对多分类任务如MNIST和ImageNet非常合适,因为测试类别必定在训练类别中。
- 但Softmax并不要求类内紧凑和类间分离,这一点不适合行业细分任务,因为训练集的样本,相对测试集来说,非常微不足道,而我们不可能拿到所有消费者Q的训练样本。
- 所以需要改造Softmax,除了保证可分性外,还要做到特征向量类内尽可能紧凑,类间尽可能分离。
细看 Softmax
文本特征到Softmax之间的线性层,如果忽略偏差,则 Loss 如下式:
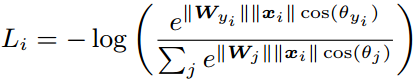
SphereFace — 把特征限制在超球上:
特征归一化
- 从最新方法来看,权值W和特征f(或x)归一化已经成为了标配,而且都给归一化特征乘以尺度因子s进行放大,目前主流都采用固定尺度因子s的方法;
- 权值和特征归一化使得CNN更加集中在优化夹角上,得到的深度人脸特征更加分离;
- 特征归一化后,特征向量都固定映射到半径为1的超球上,便于理解和优化;但这样也会压缩特征表达的空间;乘尺度因子s,相当于将超球的半径放大到s,超球变大,特征表达的空间也更大(简单理解:半径越大球的表面积越大);
- 特征归一化后,人脸识别计算特征向量相似度,L2距离和cos距离意义等价,计算量也相同,我们再也不用纠结到底用L2距离还会用cos距离(向量归一化之后,欧式距离与余弦距离意义等价)
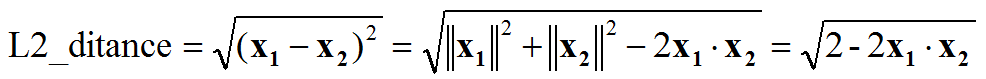
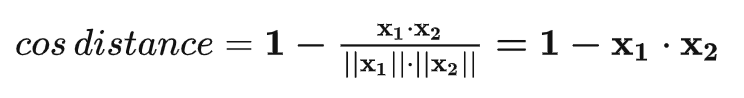
用cos(x1,x2)表示两个向量之间的余弦相似度,余弦距离就是1-余弦相似度,L2距离就是sqrt(2(1-余弦相似度))
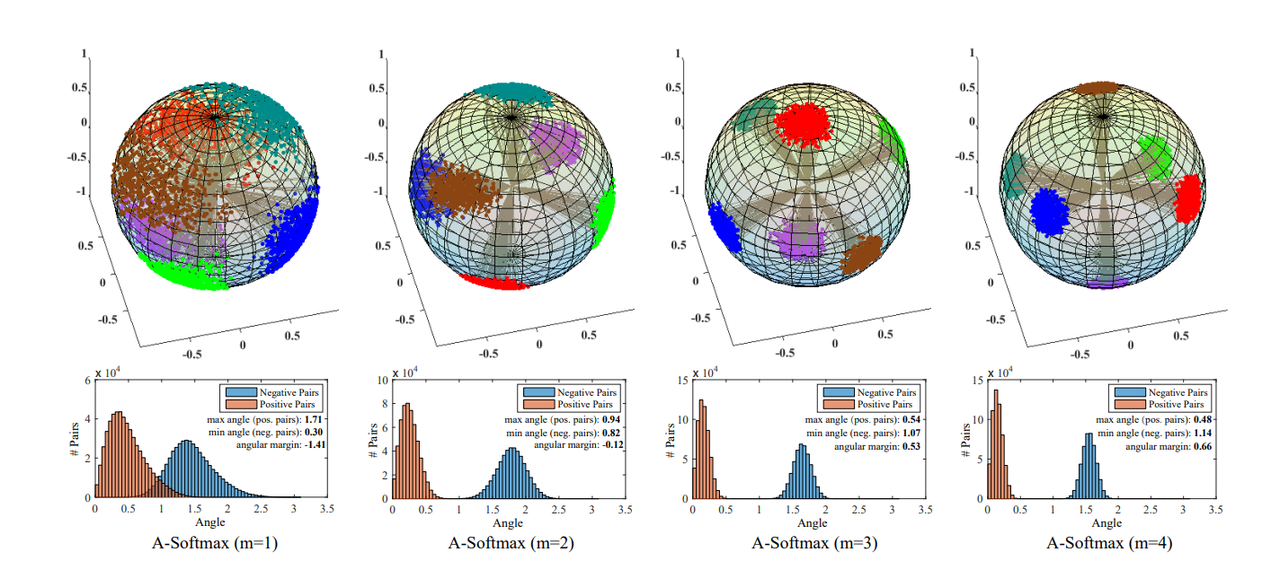
ArcFace 的加性边距

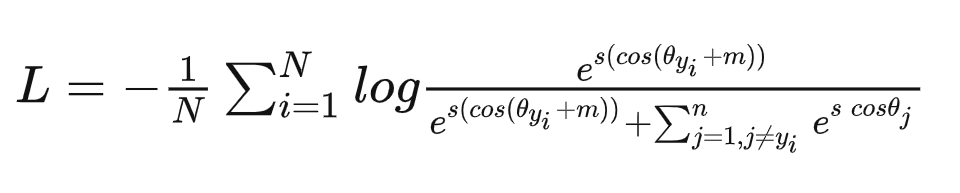
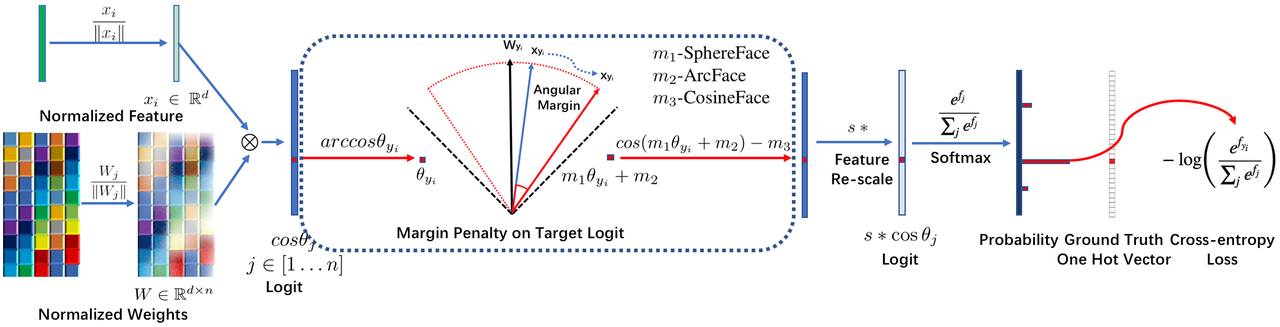
对于margin的理解
假设训练时将到某一固定损失值时,有margin的和无margin的e指数项是相等的,那么有margin的存在,
就相对的变小了,因此有margin的训练就会把类别 i 的输入特征和权重间的夹角
缩小了,margin把同类挤的更聚集了,和其它类间自然就更分离了。
参考文档
- ArcFace(https://arxiv.org/abs/1801.07698)
- 参考实现:https://github.com/foamliu/InsightFace-PyTorch。
- 人脸识别loss总结:https://zhuanlan.zhihu.com/p/488760708
- 人脸识别的LOSS(上):https://zhuanlan.zhihu.com/p/34404607
- 人脸识别的LOSS(下):https://zhuanlan.zhihu.com/p/34436551







