在当今快速发展的人工智能领域,机器学习已成为解决复杂问题的关键技术之一。本文将深入探讨机器学习的基本流程、目标以及如何评估模型的泛化能力。接下来,将逐步详细各个关键环节。
文章导航
一、理论知识介绍
1. 机器学习的一般流程
机器学习的核心在于通过数据训练模型,并不断迭代以减小误差,最终得到一个在真实场景中表现良好的模型。这一过程通常包括三个步骤:
- 数据训练:利用大量与任务相关的数据集来训练模型。
- 模型迭代:通过迭代优化,减小模型在数据集上的误差,以获得更合理的拟合效果。
- 模型应用:将训练好的模型应用于真实场景,以解决实际问题。
2. 机器学习的最终目的
最终目的是在真实场景中的数据上获得较小的预测误差,即希望模型的泛化误差越低越好。
- 机器学习中,泛化「Generalization」是指模型在面对未曾见过的数据时的表现能力。
- 泛化误差:指一个机器学习模型在真实场景中数据上的表现与其在训练数据上的表现之间的差异。
- 很明显,都希望自己的模型在训练数据上表现好,同时在真实场景中也表现很好。
3. 尝试评估模型的泛化能力
对于训练出来的模型,我们需要某种信号来评估模型的泛化能力,以指导创建更具泛化能力的模型。通常最为有效的方法是将数据分为训练集和测试集两部分,用训练集数据来训练模型,然后用测试集上的误差作为最终模型在实际场景中泛化误差的评估,最终用简单的用测试集上的指标表现来代替前面所说的某种信号。
注意了,这肯定对「测试集」是有一定要求的,具体是怎么样的测试集能代表呢?请带着这个问题继续观看和思考!
4. 训练集、验证集、测试集
为什么有这么多的数据集合,具体指的是啥意思呢,什么时候,什么背景下适合什么集合来露脸呢?
具体到一个业务需求,对应的数据集怎样构造,就会大概率有一个表现好的模型呢?
一个比喻:
- 训练集相当于上课学知识
- 验证集相当于课后的的练习题,用来纠正和强化学到的知识;
- 测试集相当于期末考试,用来最终评估学习效果。
一般划分比例:
- 小规模数据集(几千-几万条),常见比例是6:2:2,或7:1.5:1.5
- 大规模数据集(百万规模),只要验证集和测试集的数量足够即可(能代表业务情况),如100w数据,可以留1w条验证集,1w条测试集;1000万数据,同样可以留1w条验证集,1w条测试集。
- 注意,3个数据集合,不要相互包含!!
二、业务需求/问题 VS 业务模型
当我们决定训练一个模型时,通常是为了解决某个业务需求/问题或者是为了验证某个业务需求/问题能否用模型的方式解决。在这种情况下,通常是先明确具体的业务需求,然后再考虑训练模型,并准备相应的业务数据。一些常见包括但不限于以下问题:
- 业务需求/问题:需要把客服、顾客骂人的话都识别出来,以方便进行监控和分析——>可训练一个骂人话术识别模型(分类模型or匹配模型)
- 业务需求/问题:需要把顾客的评论中好评、差评都挑选出来,方便商家做进一步分析——>可训练一个顾客评论识别模型(这种一般是个分类模型)
- 业务需求/问题:需要判别一下这个顾客的成交概率——>可训练一个会话判断成交与否的模型来提供概率参考
- 业务需求/问题:能不能有一个模型,帮我解答顾客的问题——>这个需求就太太笼统了,不够具体,没表达清楚,解答顾客哪方面的问题;
- 业务需求/问题:有个多轮的需求/有个需要解决顾客问题聚类的需求……——>问题较大,聚焦不足,这类粗的朦胧的需求,可以约算法一起先交流,准备几个case,将朦胧的需求拆解为具体的-可实现的需求。
三、业务需求 VS 模型表现
当我们根据业务需求训练模型时,此时又发现新问题,模型在测试集上的表现非常好(都准确率95%+了),但离线端到端测试的时候效果才75%左右呢,为什么呢?直观来看是测试集代表的真实业务场景不足。
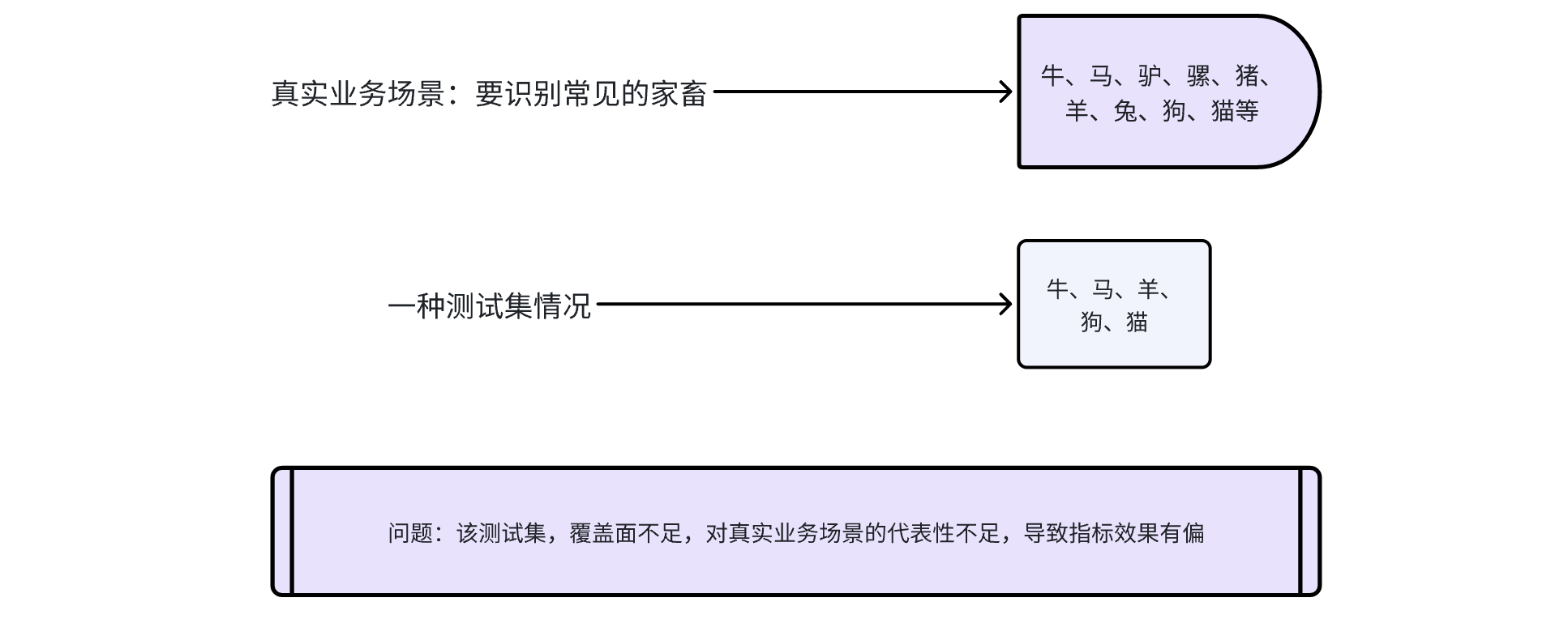

这个时候,我们需要重视测试集,因为测试集是业务场景的代表,它是一段时间内的模型迭代优化北极星方向,
- 还因为一个测试集,就是模型迭代优化前进的方向,当测试集效果达标(如准确率90%)后,模型迭代优化就可以暂缓,考虑模型上线的事情了。
- 但如果测试集不全面,当优化到90%后,准备模型上线端到端测试的时候,发现效果很差如75%;那么又要反过头来排查差异原因,如果是测试集问题则需要重新制定测试集,有需要重新优化模型。
一个操作例子:
比如要针对某行业训练一个顾客骂人识别的分类模型:
——>通过挑选3~7天的顾客消息,我们假定对于大部分的顾客消息情况都覆盖到了,这份测试集是可以用来代表「顾客骂人识别」这个业务需求的一份真实业务场景的数据集;——>那么模型在该测试集上的表现情况,会跟模型上线后的表现情况基本一致,不会出现误差太大的情况。方法1:
- 挑选1个月(2023-05~2023-06)的顾客消息,去重后作为「训练集+验证集+测试集」,标注完成后,用6:2:2,或7:1.5:1.5,或7:2:1的方式划分「训练集、验证集、测试集」
方法2:
- 挑选1个月(2023-05~2023-06)的顾客消息,去重后作为「训练集+验证集」,标注完成后,随机切分10%~20%用以区分训练集、验证集
- 挑选额外如3~7天(避开2023-05~2023-06)的顾客消息,去重后作为「测试集」
四、常见案例介绍
匹配模型案例1:XXXX客服匹配业务
业务描述:XX客服,是客服在接待公司的客户,然后回答客户的问题;

业务需求:
有较多的问题会经常被咨询到,对这类问题,可以通过应答机器人来进行提效;具体来说:
对常见的问题且需求明确,答案是一个单一操作-可用文字描述清楚的问题——》整理成问答知识库。
问答知识库:见上面表格;
通过匹配技术方案(recall+rerank),把客户问题与问答知识库中的<客户问题>进行匹配,挑选最相近的来辅助客服进行应答。
第一次迭代:
匹配-rerank模型方案:要准备「匹配知识库,训练集,测试集」
因不同的匹配模型会对匹配训练集的数据形式有不同要求:
- 常规的一种输入匹配模型:<消费者q,匹配库的Q,0或者1>
- 一种对比学习输入匹配模型: <消费者q,正匹配库的Q,负匹配库的Q>
匹配知识库:业务方整理了约200个如上面表1:整理的问答知识库表
训练集:业务方先准备了与上面表中200个正相关的消费者q,——》可以理解在匹配模型中仅标注了正样本,没有负样本;然后和相关的知识库Q,组织成了正样本,组织成了训练集。

这样导致训练出来的模型,在同分布数据上,效果非常好
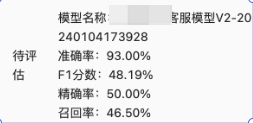
但是在真实业务场景用的时候,就发现跟评估效果比差距很大,如下面case:
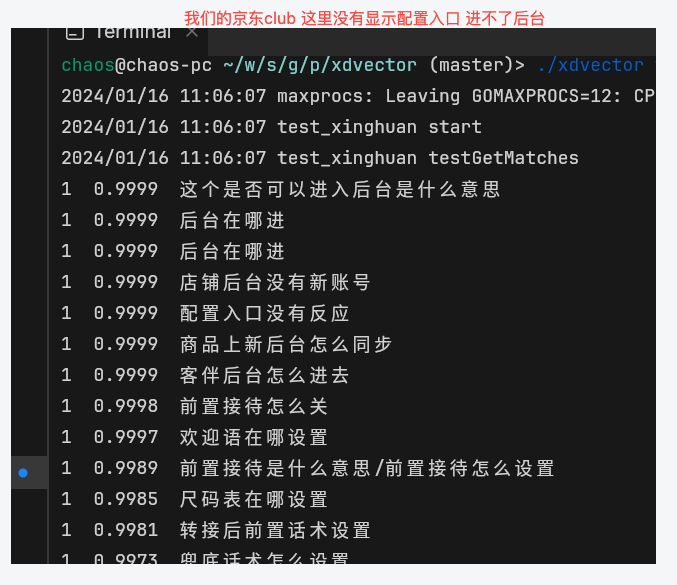
对应的问题分析:
匹配-rerank模型训练:
- 训练集中既要有正样本,也要有负样本,即tag为1,为0的两种
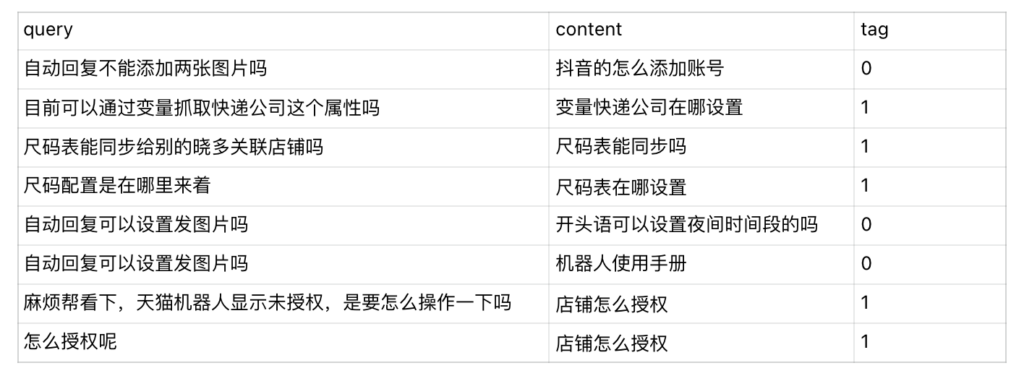
- 训练集要多样性足,覆盖面广——>跟真实应用业务场景的消息分布match——>在上面这里「仅筛选了与知识库中200个正相关的q」——>导致训练的时候仅覆盖了一部分(类比到3-业务需求VS模型表现中,训练集家禽覆盖不足)。
——>因此修正方法就是尽量把线上较多的日志去重后与知识库Q进行组织,成为覆盖面全的训练集。








