GPT-4o (“o” 代表 “omni”) 作为Open-AI近期发布的一个端到端的多模态大模型,实现人机交互领域新的突破。该模型支持以任意形式的语音、图像、文本以及视频的输入,并能够生成语音、图像和文本的任意组合的输出。特别的,其对语言输入的响应速度,达到了与人类相差无几的水平。
三个关键词:实时、多模态、推理
文章导航
GPT-4o主要亮点
- GPT-4o可以实时处理语音、视觉和文本信息。它在文本和代码理解上达到了GPT-4 Turbo的水平,而在非英语语言、语音识别和图像理解等方面有显著提升。
- GPT-4o实现了多模态端到端训练,即所有的输入和输出都由同一个神经网络处理。这使得模型可以直接观察语音的语调、背景噪音等细节,输出包含笑声、唱歌等丰富表现力的语音。而之前的语音模式是将语音、文本、语音合成分别用不同模型处理,导致信息丢失。
- 在传统基准测试中,GPT-4o在文本推理和编程能力上达到GPT-4 Turbo水平,而在多语言、语音识别、语音翻译、视觉理解等方面创下新纪录。其语音响应速度与人类对话相当。
- GPT-4o采用全新的tokenizer,大幅提高了对各种语言的编码效率,如古吉拉特语的token数减少了4.4倍。
- 根据OpenAI的安全评估,GPT-4o在网络安全等风险维度上都控制在中等水平以下。但其语音模态带来一些新的安全挑战,需要持续迭代改进。目前向公众开放的是文本和图像输入,以及文本输出。语音输出将限定为预设的声音。(就是说,语音克隆还是有种种限制)。
- GPT-4o已经在ChatGPT上线,免费用户可以访问定制化聊天机器人(以前是不行的)。ChatGPT Plus用户的消息上限提高5倍。Voice Mode的Alpha版将在未来几周上线且API面向开发者开放。
- GPT-4o在API定价上比GPT-4便宜50%,速度提高1倍,调用频率上限提高5倍。语音、视频输入能力将率先对部分可信任的API用户开放。
根据已经发布的信息表明,GPT-4o不再是一个‘text model with a voice or image attachment’, it’s a natively multimodal token in, multimodal token out model,这是一个本质的变化;多模态比单纯的text更能提高智能,或者说,没有多模态,大模型的智能提升瓶颈会更大;gpt-5应该在这个方向上发展。
虽然Open-AI并没有提供相关的技术细节,但或许我们能从现有的技术发展路线中,窥探出其背后的部分技术原理。
1. 模态信息处理
目前已经开源的技术中,一部分多模态模型对多模态信息会训练专门处理语音、图像、视频等小模型,用于后续过程与LLM的文本token兼容。在Open-AI推出GPT-4o之前,在ChatGPT或者GPT-4中的语音模式中,其实现的技术方案与之相似。但目前已有的开源模型,其响应速度很难缩短,而且这个方案存在一个弊端:即不能打断模型的输出。而根据Open-AI公开的信息,他们训练了一个跨越了音频、视觉、文本模态的端到端模型,这表明所有的输入与输出都经过同一个神经网络。这个技术路线与现有的一些开源模型(比如LLAVA、Qwen等多模态模型)不同,但个别的开源路线也与之相似,只不过我所了解的他们各自解决的问题不大相同。


众所周知,Google在23年底公布的Gemini多模态模型,就采用的是这种端到端的方案,并且在当时取得了非常好的效果,不过关于模型的内部以及训练过程,并没有透露相关细节。从相关技术报告中推测,或许他们针对不同的输入,除了类似于文本token化等输入之前的操作外,针对音频、视觉、文本都有一个专业的token标记开头以及结尾,然后按照顺序组合成输入来避免了采用模态融合方法带来的某些信息丢失的缺陷。
或许Open-AI发布的GPT-4o模型在结构上大概率与Gemini相似,但为了有更好的效果以及更快的速度,表明其最终的方案与Gemini又有很大不同。
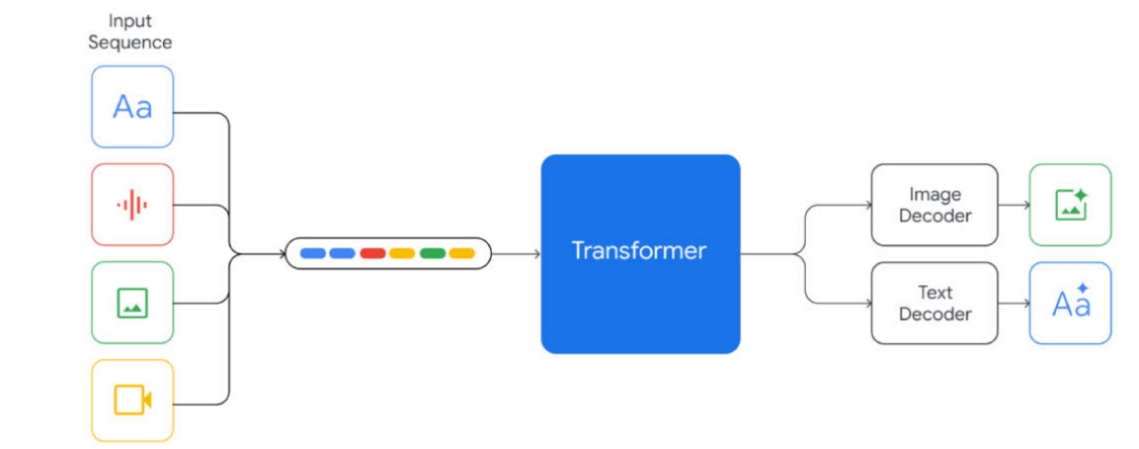
2. Tokenizer
对于文本、视觉、音频信息,若按照LLM的处理思想,也即预测下一个token的路线,那么,需要对各个模态数据tokenizer,这是一种很普遍的思路。若回顾Gemini多模态模型,会发现Google选用了Flagmni作为视觉Tokenizer,USM作为音频tokenizer,然后针对文本也有对应的Tokenizer,最终或许按照大语言模型的训练思路,来训练多模态模型。鉴于Open-AI的技术积累以及资源,他们肯定有针对各个模态的Tokenizer,只不过很大概率他们的模型比现有开源模型效果更强。
此外,还存在着另一种情况,虽然采用的可能性不大,但现有工作已经表明了其可行性。比如微软的BEiT视觉多模态、LayoutLMv3文档多模态等模型,并没有对视觉等模态有复杂的Tokenizer,但从结果上来看,也具有较大的优势。
3. 训练策略
对于LLM技术而言,训练策略往往是挖掘模型潜力的一大关键。较目前的LLM技术,模型的训练过程可以被分为:预训练、微调两大训练过程,并分别对应模型的不同阶段。针对多模态数据的训练,因为也采用了LLM骨架,因而其训练过程应该相同,只不过针对不同的数据或任务,可能有不同的训练策略。
4. LLM骨架
基础的大模型骨架仍然是GPT-4,不过Open-AI应该在原有的基础上做过优化。为了加快LLM模型的速度,那么或许混合专家模型Moe是一个不错的方案,而且Gemini就采用了这个方案。(再者,有人猜测GPT-4就是采用了8个专家模型)因为或许只有这样,才能针对模态信息做速度优化,至少从Open-AI公开的信息来说,若用这种方法或许可以让模型对语音的响应达到人类水平。同时,针对不同的输入,激活不同的模型,那么模型最后的输出或许也不必对token做专门化处理(比如对视觉/语音等模态token进一步编码),而直接可以作为输出。
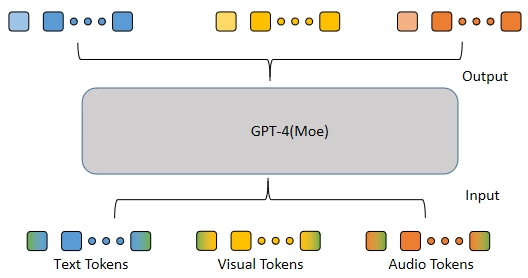
5. 特殊任务的token
针对不同的任务,要求模型能够生成对应的内容。在端到端的模型中,现有的方法是采用特殊的token标记,来区分针对不同任务生成的内容, 进一步用于下游任务。然而,目前并没有更多相关实现的细节。若从LLM训练的角度来看,这种采用特殊token标记的这种技术方案已经有成熟的应用(比如RAG中对工具的调用)。
参考文献
- https://openai.com/index/hello-gpt-4o/
- https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf
附录
多模生成能力

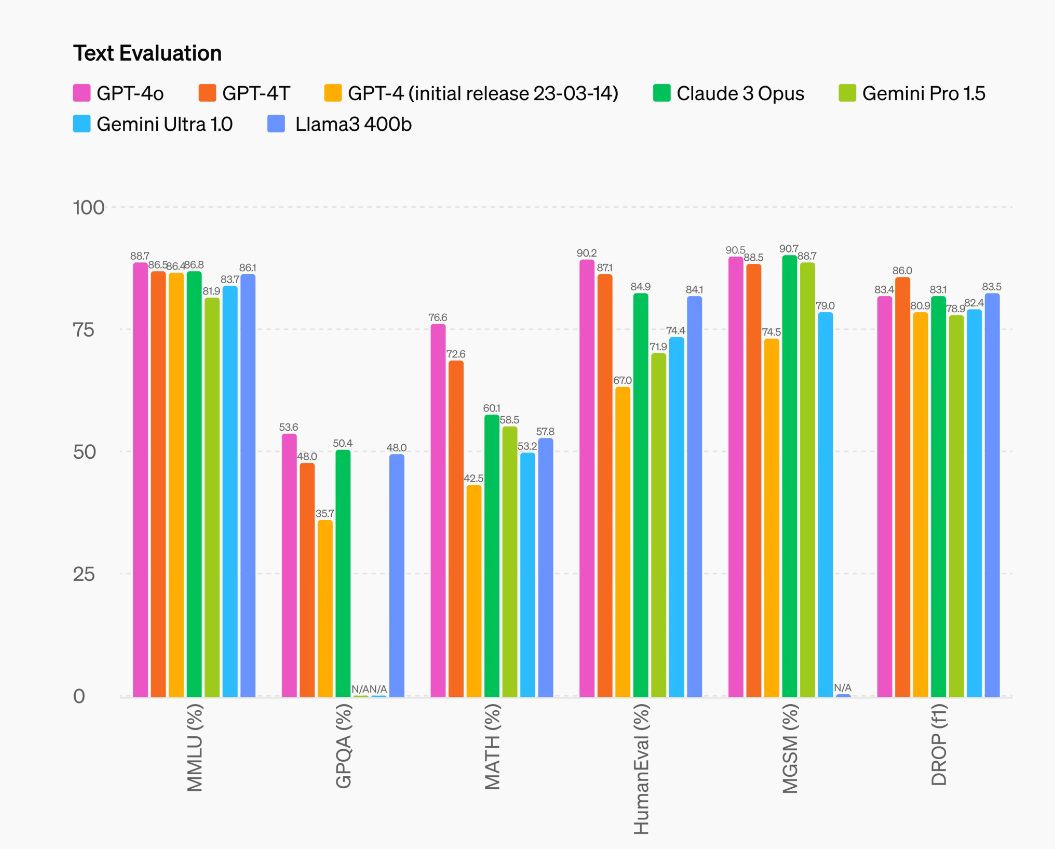
文本理解能力
跟GPT-4家族的其它成员差距不大:
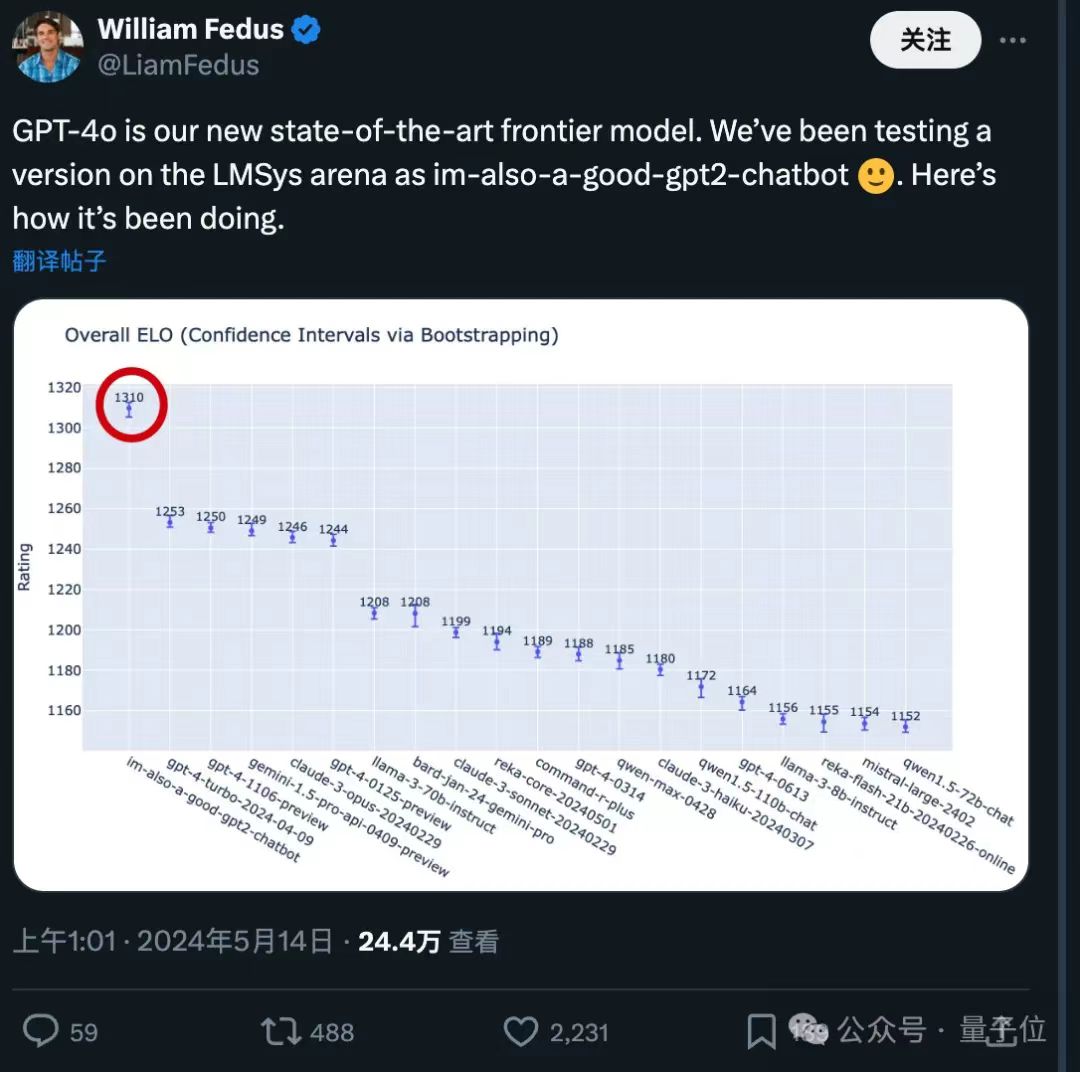
回复质量
超过50elo的代差,说明回复质量上有明显差别:
延展阅读:
openAI最新AI大模型GPT-4o可以如何赋能客服团队?







