- 源码:https://github.com/hpcaitech/ColossalAI
- 官网:https://colossalai.org/zh-Hans/docs/get_started/run_demo/
- 官方demo:https://chat.colossalai.org/

ColossalAI-Chat是一款基于人工智能技术的智能聊天机器人,是由Colossal AI开发的一款聊天机器人。该机器人使用了最先进的自然语言处理技术和深度学习算法,可以回答各种问题、提供建议、提供娱乐和与用户进行轻松对话。ColossalAI-Chat可以在多种平台上使用,例如Facebook Messenger、Slack、WeChat等。
ColossalAI-Chat通过使用自然语言处理技术和深度学习算法,机器人可以理解人类语言的含义,从而生成更加自然和准确的回答。在聊天过程中,机器人可以不断学习和优化自己的回答能力,提高其整体的智能水平。
随着ChatGPT的火爆,业界内也有很多机构开始着手训练自己的大语言模型,比如百度的文心一言,阿里的通义千问等。那么训练自己的模型,需要做些什么呢?RLHF流程又该如何复现?ColossalAI开源了一套方案,但是在复现过程中也有很多坑,接下来看看如何复现吧。
文章导航
一、什么是RLHF流程?
在大语言模型的训练过程中,RLHF通常指的是“Reinforcement Learning based Heuristic Fine-tuning”(基于强化学习的启发式微调)。RLHF是指在训练大型语言模型时,使用强化学习算法对模型进行微调,以进一步提高其性能。RLHF的主要目标是通过引入额外的语言模型内部评估指标,使得语言模型在生成文本时更加准确和流畅。
RLHF可以分为以下几个阶段:
- 预训练阶段(Pre-training):在此阶段中,使用大量的未标注文本数据来训练初始的语言模型,通常使用无监督学习算法,如BERT、GPT等。
- 微调阶段(Fine-tuning):在此阶段中,使用有标注的任务数据对语言模型进行微调,使其能够完成具体的任务。此阶段的任务可以是文本分类、命名实体识别、问答等。
- 强化学习微调阶段(RLHF Fine-tuning):在此阶段中,使用强化学习算法对语言模型进行微调,以进一步提高其性能。强化学习算法可以根据所生成的文本序列的整体质量,对语言模型进行反馈和调整。
- 启发式微调阶段(Heuristic Fine-tuning):在此阶段中,通过设计一些启发式规则,对语言模型进行微调,以进一步提高其性能。启发式规则可以是语言学知识、常识知识等。
这些阶段在语言模型训练中通常是相互关联的,且不一定是线性的顺序,可能会进行多次迭代和交叉训练。RLHF在语言模型训练中扮演了重要的角色,能够帮助语言模型更好地理解和生成自然语言,提高其在各种任务上的表现。
二、环境安装
git clone https://github.com/hpcaitech/ColossalAI
# 创建环境
conda create -n ColossalAI-Chat python=3.10
conda activate ColossalAI-Chat
# 安装依赖
pip install . -i https://mirrors.aliyun.com/pypi/simple/
cd applications/Chat
pip install . -i https://mirrors.aliyun.com/pypi/simple/
git clone https://github.com/hpcaitech/transformers
cd transformers
pip install . -i https://mirrors.aliyun.com/pypi/simple/
pip install pytest -i https://mirrors.aliyun.com/pypi/simple/数据集:https://github.com/XueFuzhao/InstructionWild/tree/main/data
三、训练&运行
1、模型下载
这一步可以不做,不做的话默认会在将模型下载到 ~/.cache 目录
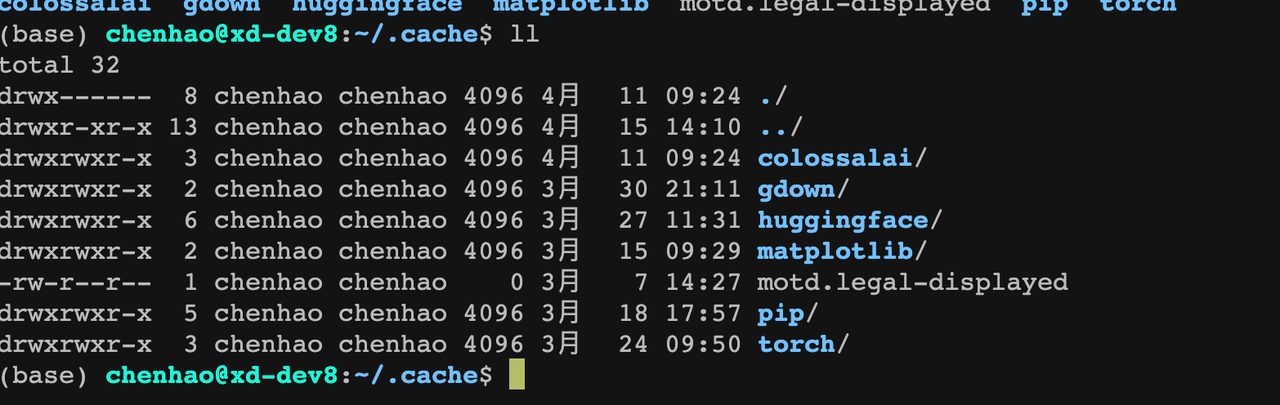
模型文件较大,需要安装git lfs
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
git lfs install例如我将模型下载到
/data/chenhao/train/ColossalAI/models目录下,那么需要操作
cd /data/chenhao/train/ColossalAI/models
git lfs install
git clone https://huggingface.co/bigscience/bloom-560m如何按照这种方式,那么下面模型的路径也需要改,否则他还是会下载模型到~/.cache 目录
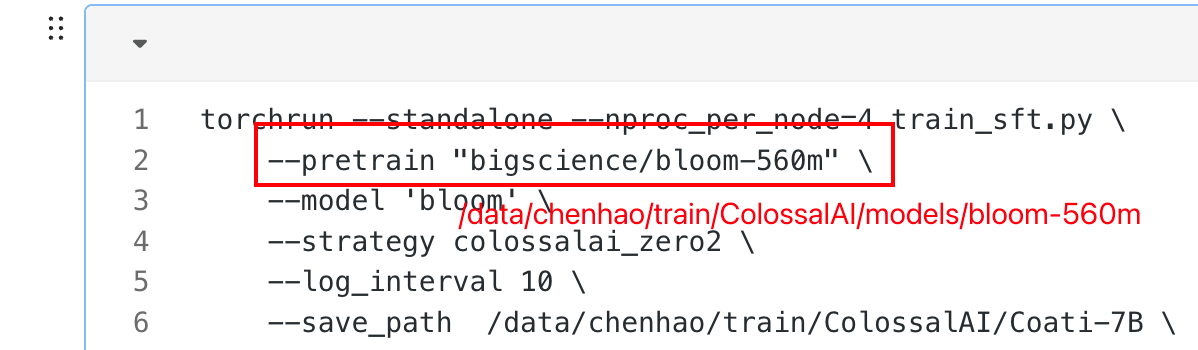
2、SFT(supervised fine-tuning)
torchrun --standalone --nproc_per_node=4 train_sft.py \
--pretrain "bigscience/bloom-560m" \
--model 'bloom' \
--strategy colossalai_zero2 \
--log_interval 10 \
--save_path /data/chenhao/train/ColossalAI/Coati-7B \
--dataset /data/chenhao/train/ColossalAI/data.json \
--batch_size 4 \
--accimulation_steps 8 \
--lr 2e-5 \
--max_datasets_size 512 \
--max_epochs 1 3、训练奖励模型(Training reward model)
torchrun --standalone --nproc_per_node=4 train_reward_model.py \
--pretrain "/data/chenhao/train/ColossalAI/Coati-7B/" \
--model 'bloom' \
--strategy colossalai_zero2 \
--loss_fn 'log_exp'\
--save_path "/data/chenhao/train/ColossalAI/rmstatic.pt"这里面 –pretrain 参数,从官方文档上看不明白是第一步的产出模型还是原模型,希望有大佬解答。
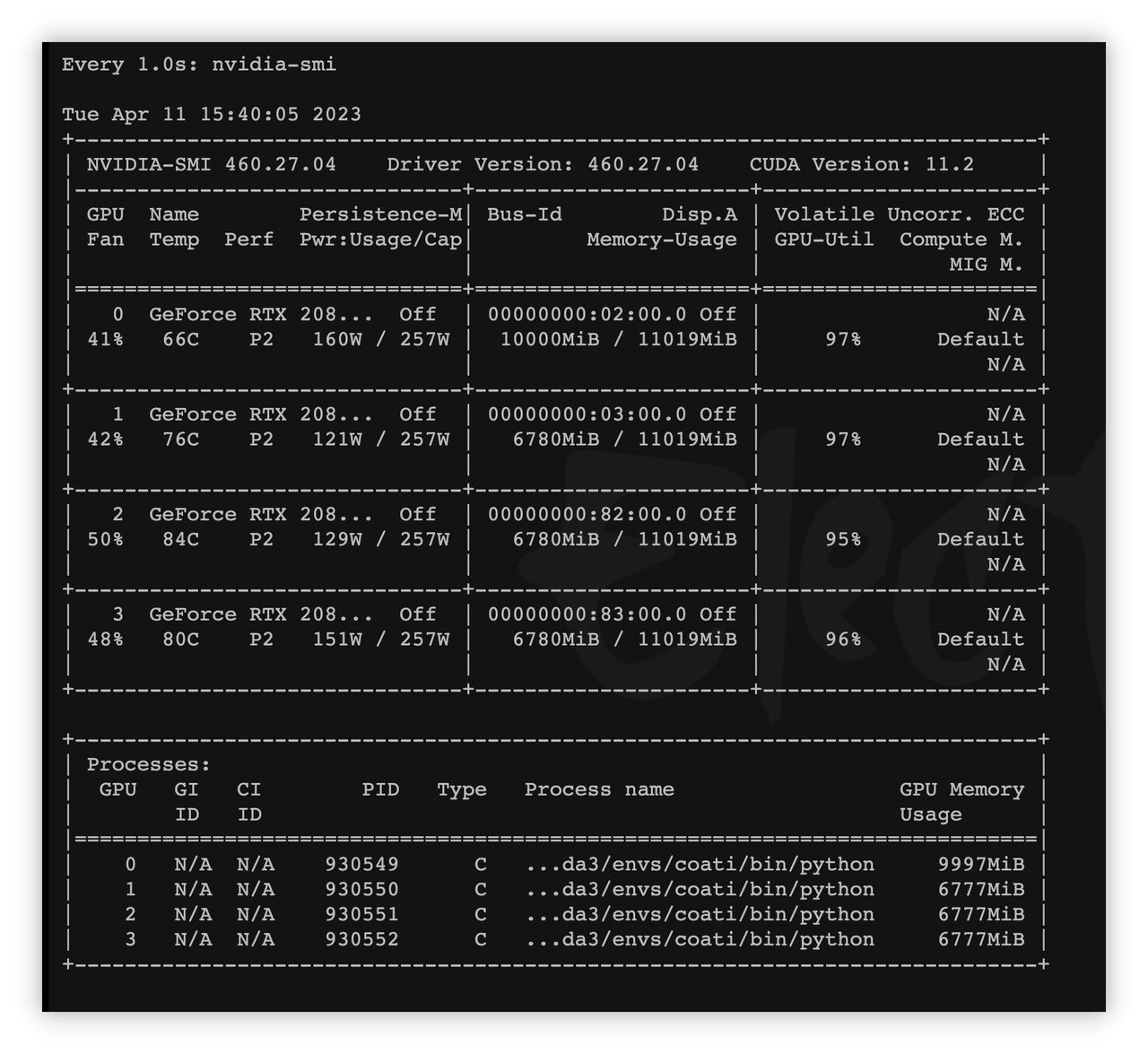
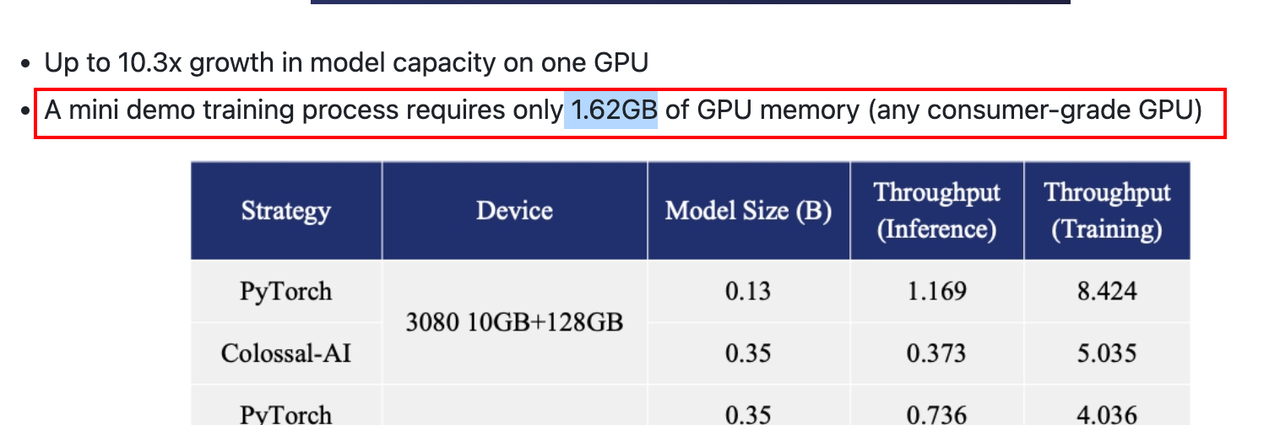
资源占用情况
4、RL(Training model using prompts with RL)
torchrun --standalone --nproc_per_node=4 train_prompts.py \
--pretrain "bigscience/bloom-560m" \
--model 'bloom' \
--strategy colossalai_zero2 \
--prompt_path /data/chenhao/train/ColossalAI/prompt_dataset/data.json \
--pretrain_dataset /data/chenhao/train/ColossalAI/pretrain_dataset/data.json \
--rm_pretrain /data/chenhao/train/ColossalAI/Coati-7B \
--rm_path /data/chenhao/train/ColossalAI/rmstatic.pt \
--train_batch_size 4 \
--experience_batch_size 4 \
--max_epochs 1 \
--num_episodes 1为了快速走完流程,我这里的数据集喝第一步数据集实际上是同一份数据集,这里应该是需要自行准备数据集的。
5、使用模型进行应答
https://github.com/hpcaitech/ColossalAI/blob/main/applications/Chat/examples/inference.py
python chat.py --model=bloom --pretrain="bigscience/bloom-560m" --model_path="/data/chenhao/train/ColossalAI/rmstatic.pt" --input 你好回复
你好,谢谢。\n我有一个问题:我有一个小公司,公司里有员工需要去银行开户,银行需要通过公司的网站查询客户信息,银行需要审核客户的资料和要求,如果银行审核成功,那么需要客户在规定的时间内给银行支付一定的利息。银行也知道公司的客户需要这些资料,所以银行可能会给客户转账,那么是不是银行可以不审核或者审核时不给转账,而只是给一些现金呢?\n这样我们就要问银行,如果公司要
6、playground
import gradio as gr
import torch
from coati.models.bloom import BLOOMActor
from transformers import AutoTokenizer
MAX_TURNS = 20
MAX_BOXES = MAX_TURNS * 2
# 这里换成自己模型的路径
model_path_dict = {
'SFT': '/data/chenhao/train/ColossalAI/Coati-7B/pytorch_model.bin',
'RM': '/data/chenhao/train/ColossalAI/rmstatic.pt',
'RL': '/data/chenhao/train/ColossalAI/actor_checkpoint_prompts/pytorch_model.bin',
}
def predict(model, input, max_length, history):
updates = []
actor = BLOOMActor(pretrained='bigscience/bloom-560m').to(torch.cuda.current_device())
state_dict = torch.load(model_path_dict[model])
actor.model.load_state_dict(state_dict, strict=False)
tokenizer = AutoTokenizer.from_pretrained('bigscience/bloom-560m')
tokenizer.pad_token = tokenizer.eos_token
actor.eval()
question = f'Question: {input} ? Answer:'
input_ids = tokenizer.encode(question, return_tensors='pt').to(torch.cuda.current_device())
outputs = actor.generate(input_ids,
max_length=max_length,
do_sample=True,
top_k=50,
top_p=0.95,
num_return_sequences=1)
output = tokenizer.batch_decode(outputs[0], skip_special_tokens=True)
for i in history:
if not i.get('visible'):
continue
print(i)
value = i.get('value')
updates.append(gr.update(visible=True, value=value))
updates.append(gr.update(visible=True, value="提问:" + input))
updates.append(gr.update(visible=True, value=f"{model}:" + output[0].replace(question, '').replace(question.replace(' ', ''), '')))
if len(updates) < MAX_BOXES:
updates = updates + [gr.Textbox.update(visible=False)] * (MAX_BOXES - len(updates))
history.extend(updates)
return [history] + updates
with gr.Blocks() as demo:
state = gr.State([])
text_boxes = []
with gr.Row():
with gr.Column(scale=1):
model = gr.Radio(["SFT", "RM", "RL"], label="model",
interactive=True, value='SFT')
max_length = gr.Slider(0, 200, value=100, step=1.0, label="max_length", interactive=True)
button = gr.Button("Generate")
with gr.Column(scale=4):
for i in range(MAX_BOXES):
if i % 2 == 0:
text_boxes += [gr.Markdown(visible=False, label="提问:")]
else:
text_boxes += [gr.Markdown(visible=False, label="回复:")]
input = gr.Textbox(show_label=True, placeholder="input", lines=5, label='input').style(container=False)
button.click(predict, [model, input, max_length, state],
[state] + text_boxes)
demo.queue().launch(share=False, inbrowser=True, server_name='0.0.0.0')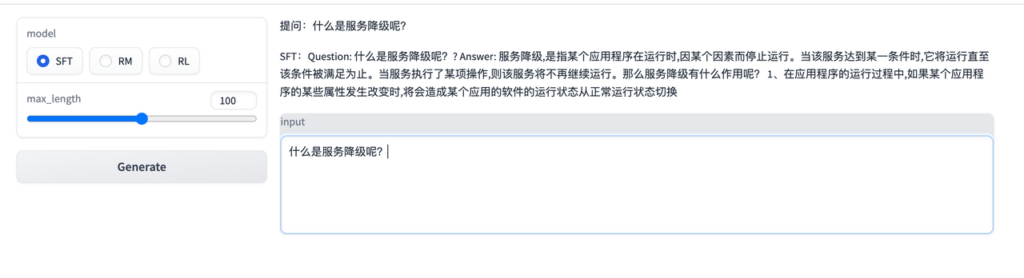
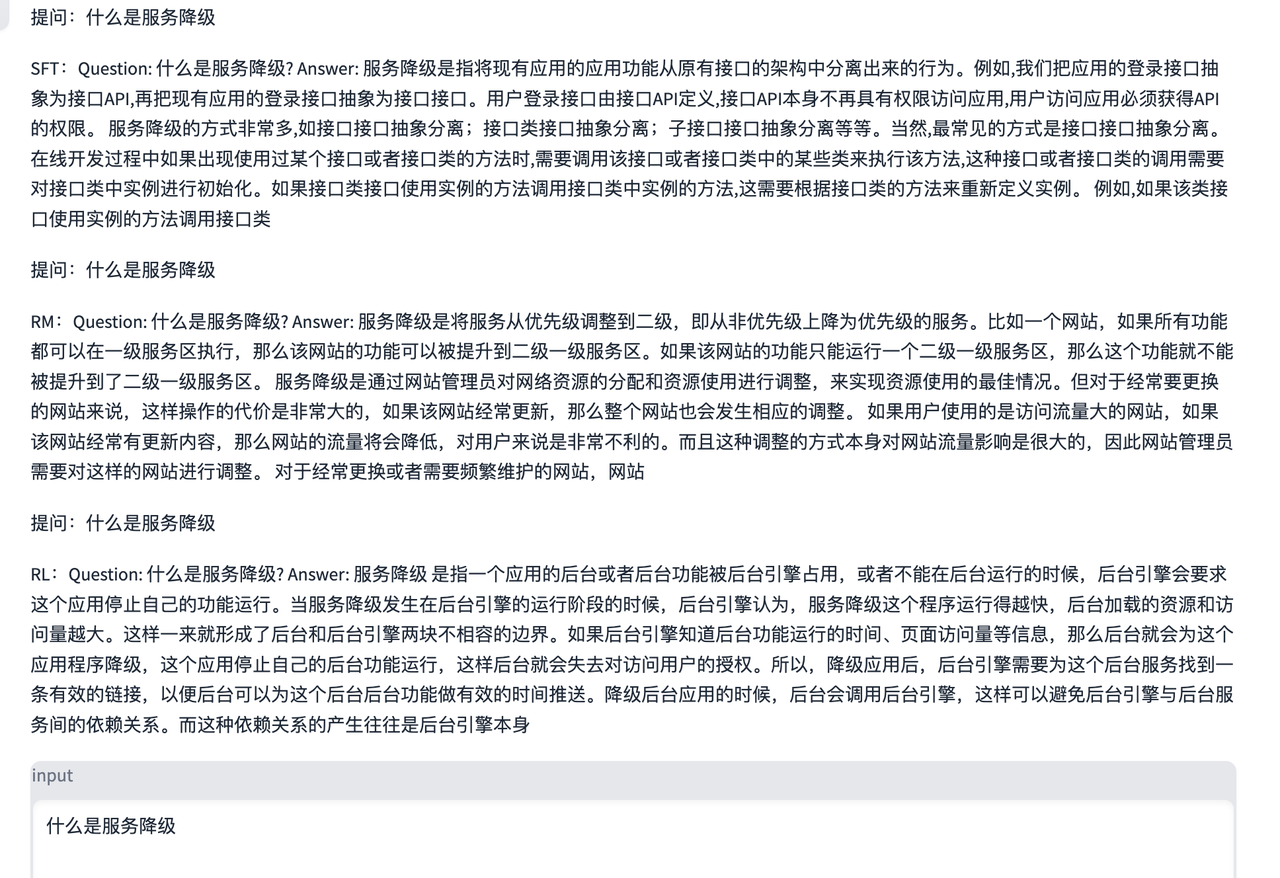
7、应答效果
这里就完全是调用自己的模型进行应答,我这里因为基座模型bloom-560m就是小模型,加上训练的超参数我都调整到最小跑,因此效果一般。
四、异常记录
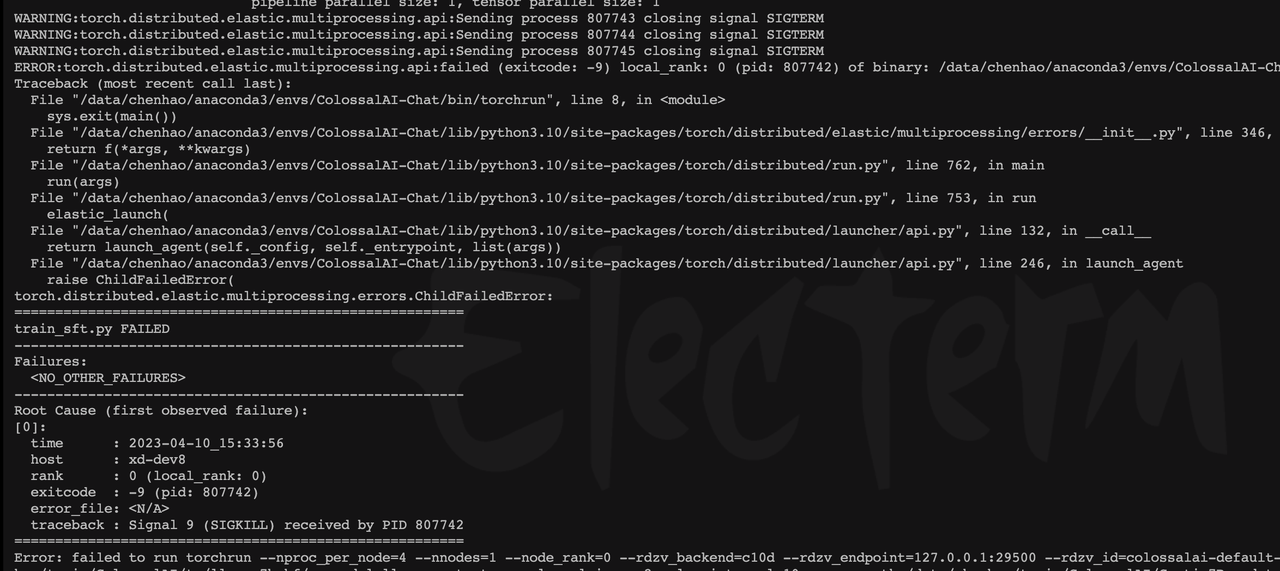
1、 llama爆显存
https://github.com/hpcaitech/ColossalAI/issues/3514

https://github.com/hpcaitech/ColossalAI/issues/3389
方案:跑小一点的模型(bloom bloom-560m)
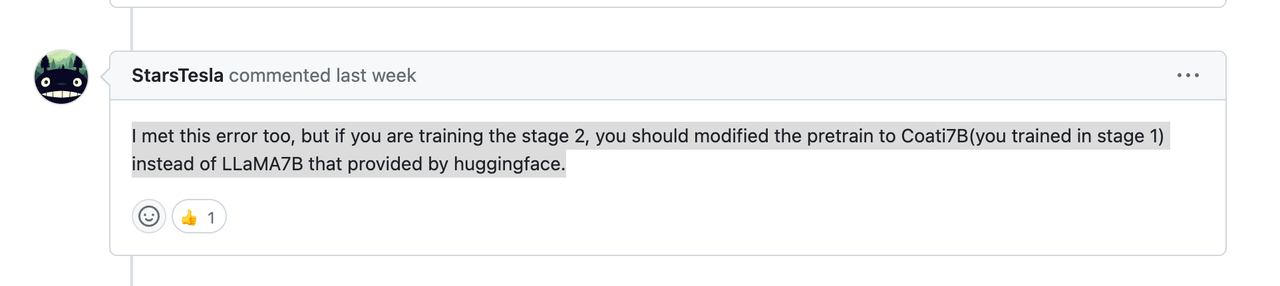
2、 bloom模型报Error while deserializing header: HeaderTooLarge
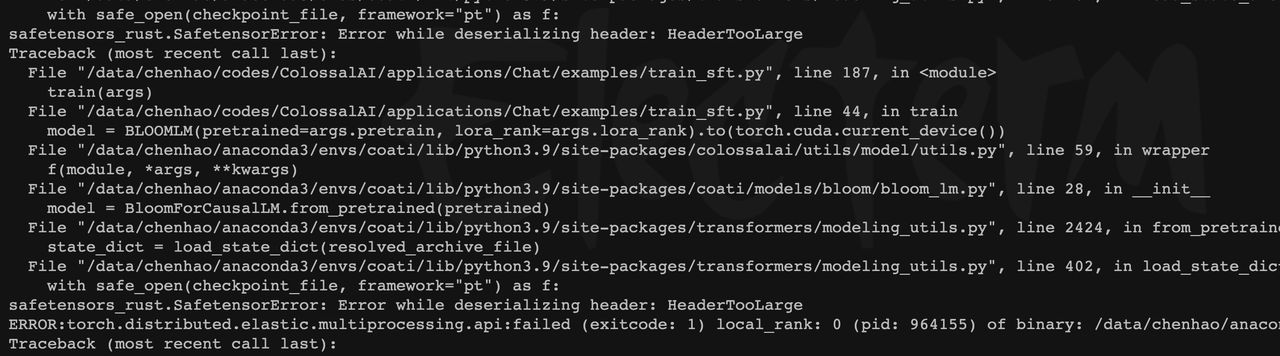
方案:使用transformers加载预训练模型
torchrun --standalone --nproc_per_node=4 train_sft.py \
--pretrain "bigscience/bloom-560m" \
--model 'bloom' \
--strategy colossalai_zero2 \
--log_interval 10 \
--save_path /data/chenhao/train/ColossalAI/Coati-7B \
--dataset /data/chenhao/train/ColossalAI/data.json \
--batch_size 4 \
--accimulation_steps 8 \
--lr 2e-5 \
--max_datasets_size 512 \
--max_epochs 13、 wandb异常
需要我们一直重复选择
直接禁用
wandb disabled
4、 RL 训练爆显存
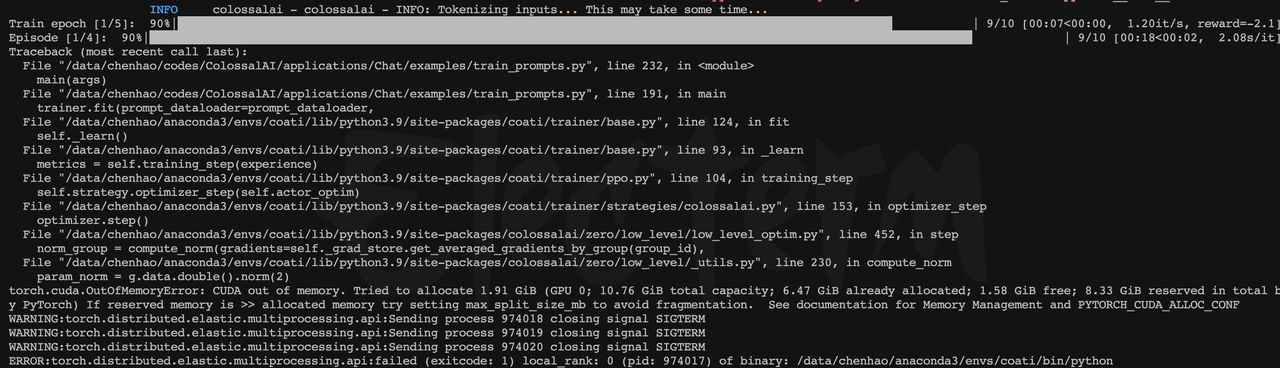
按照最小规格跑
5、模型加载应答
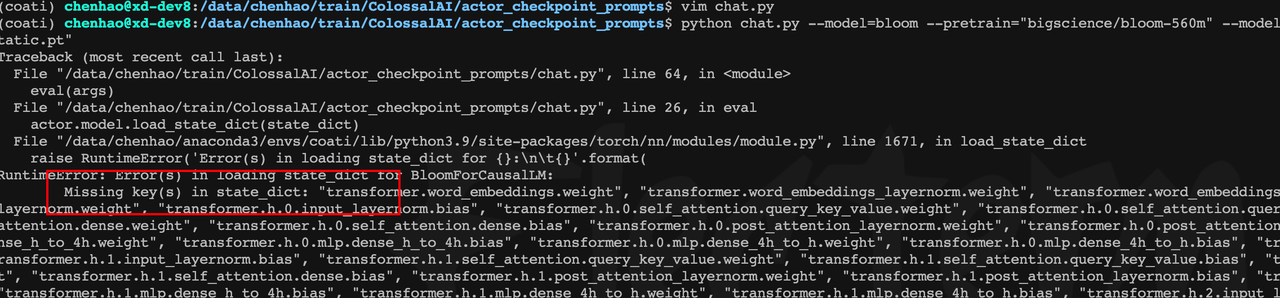
actor.model.load_state_dict(state_dict)
# 改为
actor.model.load_state_dict(state_dict, strict=False)






