文章导航
一、Sora技术概述
Sora 的本质是 「世界的模拟器」。
OpenAI 技术报告中透露,Sora 能够深刻地「理解」运动中的物理世界,堪称为真正的世界模型。
OpenAI 在其技术报告中只字未提与模型架构、数据规模、训练成本等相关的细节,但其标题赫然指出 Sora 这类视频生成模型是「世界的模拟器」。OpenAI 想强调,Sora 不是单纯的视频生成模型,不只是视频行业颠覆者,而是「世界的模拟器」——它打开了一条通往模拟物理世界的有效路径。
二、Sora技术工作原理
1、ChatGPT 是文本接口的世界模型。它的输入和输出皆为文本,但要正确的预测下一个token,模型内部必须建立世界模型。
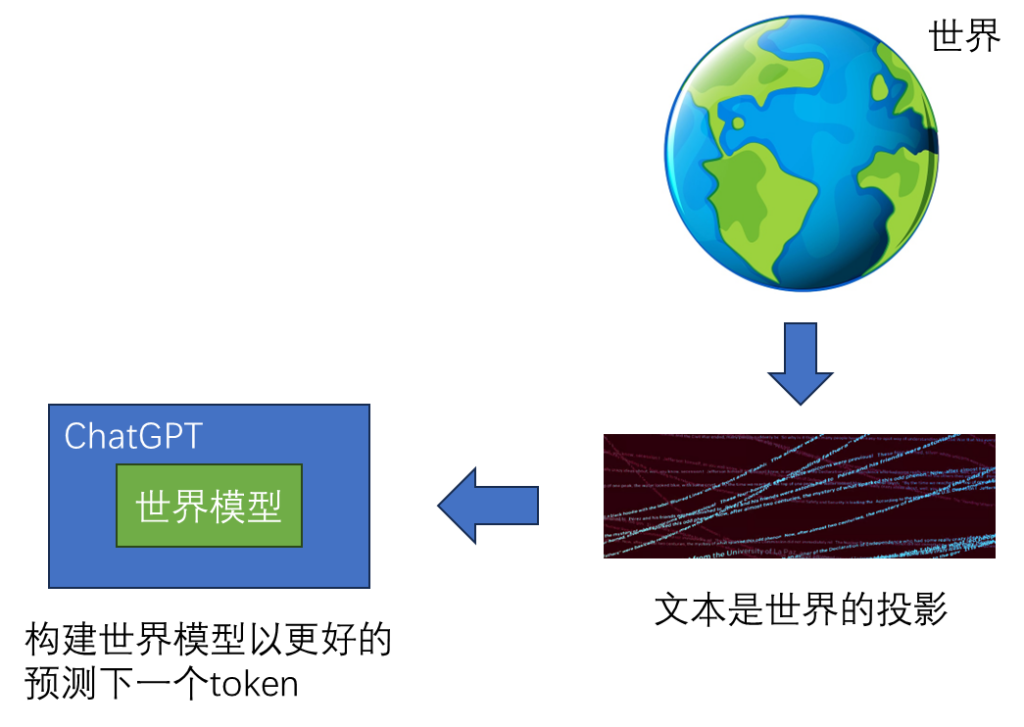

Transformer 的核心是 Self-Attention,即自注意力机制。在处理文本时,一个句子会先被分词,形成一个个Token。然后每个Token会被向量化,这个过程称为 Embedding 嵌入。
2、Sora 是多模接口的世界模型。它的输入是视频和文本,输出是下一帧,要正确的预测下一帧,必须建立世界模型。
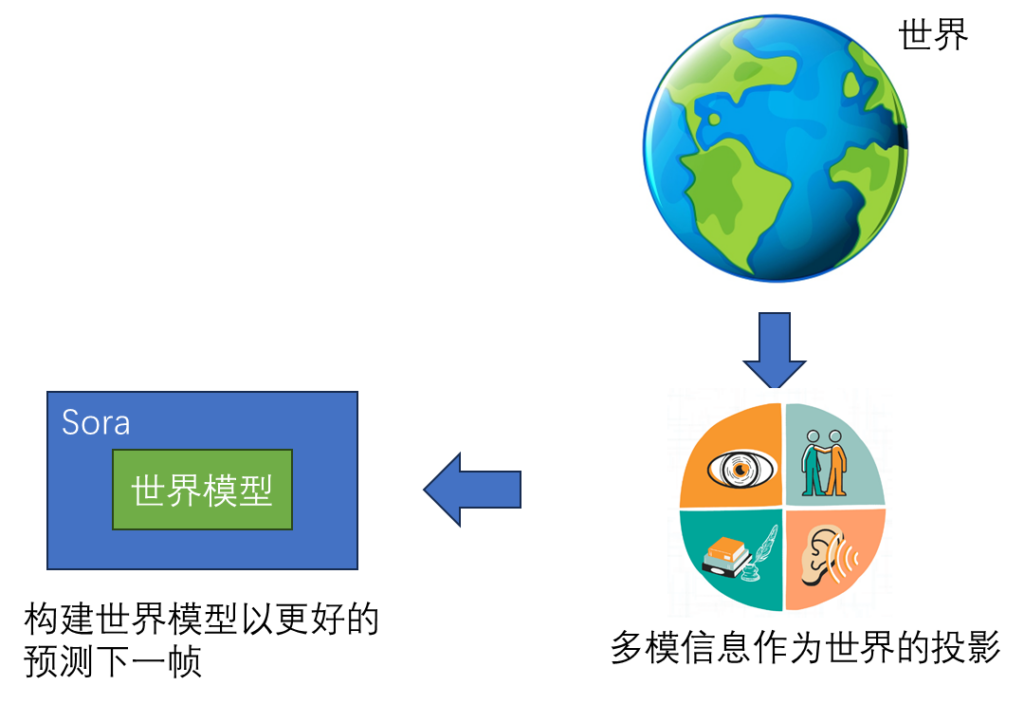
3、Patch:Diffusion 是个绘图模型,Stable Diffusion 和 Midjourney 采用的就是这个模型。这里系统会先把视频切块,也就是把每一帧画面给拆分成 Patch。这个 Patch 就相当于文本 Transformer 需要处理的每个 Token。

每个 Patch 会被压缩成向量,用于后续的注意力计算。只不过这里需要计算的是空间注意力和时间注意力。Transformer 的能力在于捕获长距离依赖关系。这个能力在视频领域就是发现但
- 单帧画面中各个元素的空间关联性,以及
- 连续帧的画面中各个元素的时间关联性。
Patch是视觉数据模型的有效表示。因为 Sora 使用了 Patch,从而可以让它生成的图片拥有相对自由的比例和分辨率。比例和分辨率改变后只需改变视频到 Patch 之间的 Projector (比较小),基础模型不用动。
4、语言理解:当你给 Sora 输入一个文字提示的时候,它有一个专门的算法来丰富你的描述。然后基于这个丰富后的描述,Sora 就会结合 Diffusion 和 Transformer 各自在画面推演和时空连续性方面的能力来创建一个动态的,看上去合理的画面。
下面是顾剑锋教授对这个过程的描述:
首先,Soar的训练样本是(文本,视频)对,有些视频对应的标题过于简短,字幕缺少,Sora采用了Dall-E的重新标题技术。
Sora的训练集包含一些优质的样本,(高度描述性字幕,短视频),由此训练了短视频数据流形(包括时空令牌流形),每个流形用其字幕(标题)来标识。对于缺乏标题或者字幕含混的劣质短视频,Sora将其编码到隐空间,在隐空间中寻找临近优质视频的隐特征向量,然后将优质视频的字幕(标题)拷贝给劣质视频。用这种方法,Sora可以为所有的训练视频数据添加高度描述性的字幕,从而提高了训练集的质量,进一步提升系统性能。
同时大语言模型可以将用户输入的提示进行扩充,变得更加精准,更加具有描述性,从而使得生成视频与用户需求更好契合。这使得Sora如虎添翼。但是Soar依然存在着很多缺陷,我们可以通过如下例子进行分析。
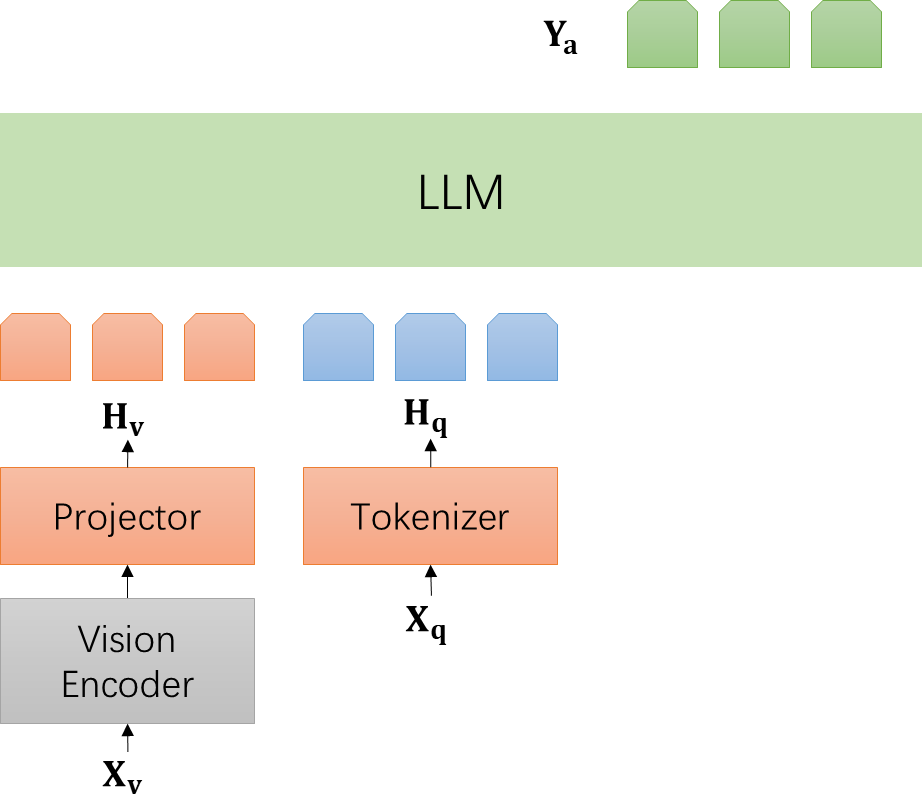
5、世界模型:LLM 中的世界模型是 “world simulator” 的核心。我猜测 Sora 的架构类似当前主流的LMM。
- 输入:LLM 下面的部分是输入。是对世界的观察,可以包括文本、图像、视频、声音各种模态;
- 输出:LLM 上面的部分是输出。是对世界的预测,同样可以包括各种模态。输出 Ya 的 token 用 DiT 解码,转化成1分钟清晰的长视频。而世界模型,在 LLM 里。
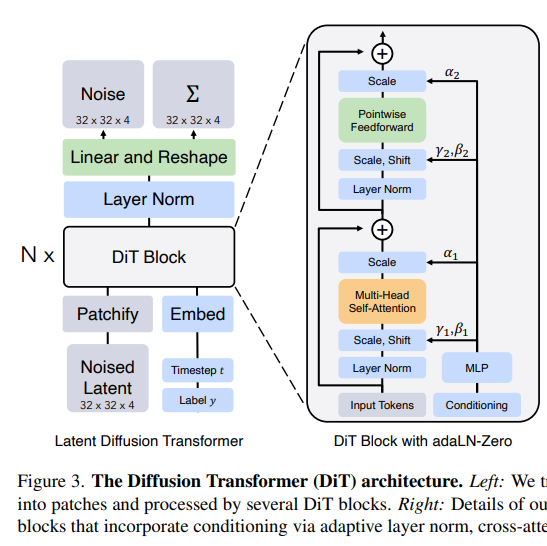
6、Diffusion Transformer (DiT):Sora 采用了一个 Diffusion Transformer 这样的扩散模型。也就是以 Transformer 为主干的 Diffusion 架构。Diffusion 模型擅长图片生成,而 Transformer 模型擅长长序列的上下文关联。Sora 将这两种技术融合在一起,构成一个视频版的 ChatGPT。
给定输入噪声 Patch(以及文本提示等调节信息),它被训练来预测原始的“干净” Patch。Sora 是个 Diffusion Transformer,而 Transformer 具备卓越的扩展(Scaling)特性。

We train latent diffusion models of images, replacing the commonly-used U-Net backbone with a transformer that operates on latent patches.
7、Sora 涌现出的模拟能力:
- 3D 连续性:无论镜头怎么运动,它所描绘的三维场景中的物体是连续存在或者运动的。
- 长距离关联和物体永存性:前景的游客走过,在短时间内挡住了斑点狗。但是狗是一直趴在窗户上的。
- 世界交互性:这个人在吃汉堡,吃过的汉堡明显有缺失的一块。
三、Sora技术讨论
1、Sora 到底是在操控2D层面的像素,还是成为了一个3D层面的物理引擎呢?
思考:就像光的“波粒二象性”,两种说法都有一定道理。因为你给到 Sora 的训练数据只是 2D 的平面内容。是不存在深度信息的。所以它整个的计算,都是发生在一个二维空间内的。只不过把二维像素转化为向量进行计算,再影射回像素空间。所以说它是“2D层面的像素操控戏法”也有道理。但同时,在训练过程中,Sora很有可能已经建立了对透视的理解,这就意味着即便它在操控像素,它也能读懂画面中看上去平面的物体,实则是有一定深度信息的。这个深度信息是通过训练过程,以隐变量形式存在的。从而可能具备对于3D的理解能力。
2、LeCun 则一贯酸溜溜地认为 Sora 不能理解物理世界,在他看来,「仅根据文字提示生成逼真的视频,并不代表模型理解了物理世界。生成视频的过程与基于世界模型的因果预测完全不同」。
思考:那么 GPT-3 的文本预测(续写)算不算世界模拟器(到文本的投影)?如果GPT-3算,那Sora当然算,而且扩展了1-2个维度。以物理模拟作为对比,模拟器理解物理世界的运行规律。因此输入初始状态,它可以预测(或模拟)后续每个时间点的状态。关键是如何定义“理解”,按照杰夫·霍金斯的观点:“能预测就是理解”。列出公式并求解并非必须。
如果您想了解更多关于Sora 技术洞察之下相关运用,可以点击这里查看更多信息。
四、参考文献
- Sora的官网技术报告:https://openai.com/research/video-generation-models-as-world-simulators
- 关于“文本是世界的投影”,即 “投影说” 请参阅维特根斯坦的《逻辑哲学论》。
- Dosovitskiy, Alexey, et al. “An image is worth 16×16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
- Peebles, William, and Saining Xie. “Scalable diffusion models with transformers.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
- Ha, David, and Jürgen Schmidhuber. “World models.” arXiv preprint arXiv:1803.10122 (2018).
- Dehghani, Mostafa, et al. “Patch n’Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution.” arXiv preprint arXiv:2307.06304 (2023).
- Blattmann, Andreas, et al. “Align your latents: High-resolution video synthesis with latent diffusion models.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
- Chen, Mark, et al. “Generative pretraining from pixels.” International conference on machine learning. PMLR, 2020.
- Ramesh, Aditya, et al. “Hierarchical text-conditional image generation with clip latents.” arXiv preprint arXiv:2204.06125 1.2 (2022): 3.
- Yu, Jiahui, et al. “Scaling autoregressive models for content-rich text-to-image generation.” arXiv preprint arXiv:2206.10789 2.3 (2022): 5.
- Betker, James, et al. “Improving image generation with better captions.” Computer Science. https://cdn.openai.com/papers/dall-e-3. pdf 2.3 (2023): 8
延展阅读:
2024双11淘宝3000亿国家补贴怎么领?成都家电以旧换新线上线下使用入口在哪里?







