
文章导航
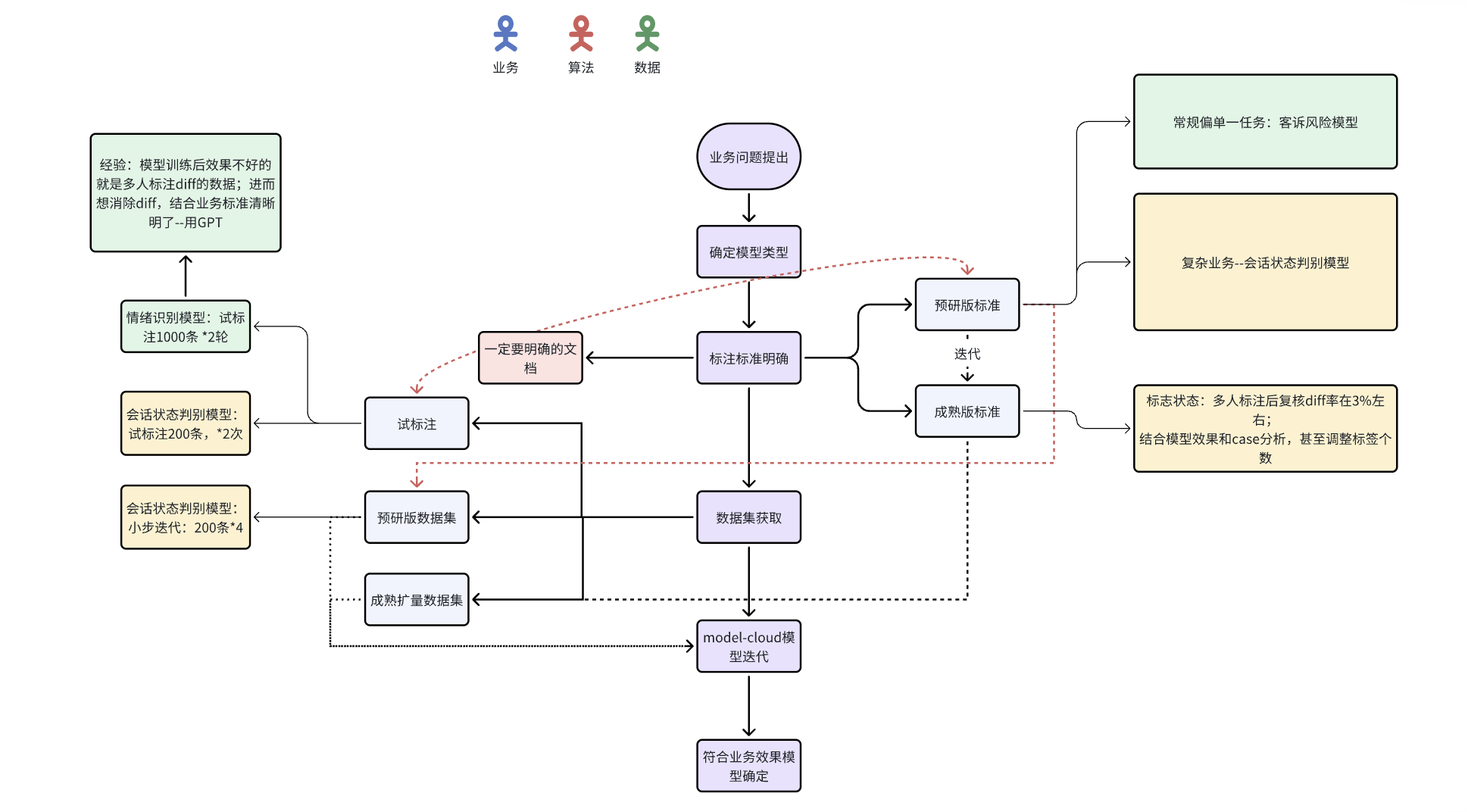
一、业务问题到模型
由业务问题进而确定是要训练什么类型的模型(分类模型、匹配模型、生成模型等)
面对业务问题挑战,我们首先需要确定要训练的模型类型:是分类模型、匹配模型还是生成模型?这一步,业务同学可以独立完成,或与算法团队协作,确保模型类型与业务需求相匹配。
二、标注标准/准则
任何一个模型都离不开对应的数据集,而数据集则需要有对应的标注准则(严格程度根据业务情况不同而变化)
1、预研版标注标准
在初期,标准是模糊的,首先要确定基本的标准:
eg:分类模型:
首先要确定分类的类别,原则上分类的类别之间要相互独立,无交叉包含现象,存在歧义的时候–至少标注阶段先按照细粒度的来进行,该过程:
- 一方面结合业务场景的需要
- 一方面要分析实际的业务数据case
- 还要考虑标注的数据之间是否会有冲突,导致模型学习的数据经验混乱
比如会话状态判别模型,确定4个标注类别:「售前、售后、售前+售后、其他」
原因是:
- 一方面的确存在人来看不好区分销售阶段的case,还有一些服务消息在业务中是不需要区分销售阶段的(线下购买-线上咨询)
- 一通会话可能出现:前半段咨询售前-然后下单-然后再咨询售后;
- 为保险起见(防止这类case对其他售前or售后的数据造成污染-进而导致模型学习规律困难),在标注期间优先按照细粒度标注–单独标识——>后期可以方便灵活的合并到售前or售后or单独一个类别;
标注准则不是一天或者几次讨论就能明确下来的;–准则的复杂度与业务复杂度强相关
这个需要业务+算法同学先有基本概念,然后实际试标真实数据case,然后根据标注碰到的实际问题,然后迭代该准则
数据参考:
复杂业务标注准则:如会话状态判别模型,该过程前前后后花费了:10人天+
简单业务标注准则:情绪识别模型,该过程前前后后花费了:4人天+
一线业务老师宝贵经验:
- 前期多人标注同一份数据,找不同,确定标签和标准的歧义(标签粒度等)
- 单批次数据量要少,多来几轮,哪怕每次的标注数据量仅20条
- 但是要注意业务场景多样性的覆盖度——跨平台,跨店铺,跨类目
- 思考影响模型的因素
- 样本本身的多样性(比如会话状态判别模型:会话的聊天内容中考虑,长短、角色、轮次等)
- 标签不同人diff较大的时候,可以考虑增加标签,标签粒度尽量细,由细到粗
- 标注的时候,最好把证据显示的表示(比如把一个样本中售前售后的判断依据标红),方便复核以及数据处理
- 标注数据文档在同一个目录,以标注的次数或迭代的轮次命名
2、成熟版标注标准
预研版标注标准经过几次迭代后,当业务+算法同学在试标注过程中,发现无更多标注特例(标注中碰到的情况在标注准则中已经都覆盖或能推演出来),则此时——>标注标准进入成熟阶段;
- 成熟版的标准新人能够比较顺畅的上手,同时培训成本低
成熟阶段的标注标准也并非就是一成不变了,仍然会随着:
- 业务需求的变化
- 大量数据标注中碰到的更多意外|特殊情况
- 模型训练中发现的问题
- ……
各种情况来不断的小幅度调整该标准。
成熟后,训练模型所需要的标注数据则可以进入到扩展数量阶段(纯人工、纯GPT、人+GPT结合等等)
三、训练数据
理论介绍
训练一个业务效果可接受模型,一般要有3个数据集:训练集、验证集、测试集;
理想状态下,3个数据集要均要能代表线上业务场景和数据的实际情况,覆盖度要全面;一些介绍理解:
训练集:这是我们用来训练机器学习模型的数据集。在监督学习中,训练集包括样本和对应的标签。我们使用训练集来拟合模型,通过调整模型的参数来最小化模型的损失函数。训练集通常占据整个数据集的大部分,比如70%或80%,因为我们希望模型能充分学习到数据中的规律。同时训练集的数据的多样性也要保障,避免数据多样性单一导致模型过拟合,那这样训练出来的模型对未见过的数据预测效果较差。
验证集:我们用这部分数据来进行模型的选择。具体来说,我们可能有多种不同的模型(或是不同参数的模型),我们用验证集来看哪个模型在未见过的数据上的表现最好。与训练集不同,我们并不使用验证集来更新模型的参数,只是用来评估模型的性能。验证集的数据规模通常比训练集小,例如占总数据集的10%或20%。
测试集:我们使用这部分数据来最终评估已经训练好的模型的性能。测试集保证了在实际应用中,我们对模型效果的估计是准确的。与验证集一样,我们并不使用测试集来更新模型的参数。测试集的数据规模通常和验证集一样,或者更小。
总的来说,训练集、验证集和测试集的划分主要是为了避免过拟合和进行模型选择。从业务效果角度来说,我们希望模型在未见过的数据上也能有好的表现,而只有一个数据集是不足以做到这一点的。通过训练集、验证集和测试集的分割,我们能更好地评估模型在真实世界中的性能。
打个比方来理解:
- 训练集相当于课后的练习题,用于日常的知识巩固
- 验证集相当于周考,用来纠正和强化学到的知识
- 测试集相当于期末考试,用来最终评估学习效果
这部分理论方面的有非常多的资料,大家尽可以在互联网上查阅;
数据获取
数据试标注+预研版数据集:
- 业务数据拉取
- 定业务数据负责人,集体粗标注,复杂业务+算法同学
- 复核(二次、三次……)
- diff数据进行讨论,标准更新
- 重复2-3-4, diff率在3左右,考虑开始扩量
- 测试集要业务老师负责产出(第三方)
一线业务老师宝贵经验:
- 拉取数据,要拉线上真实数据,即便是测服,可能与线上有差距;
- 业务数据拉取的范围:一开始要广-影响因素要足够多–可以看那些因素对结果的影响最大;
- Eg:会话状态判别模型业务
- 维度1:一开始拉取全部轮次聊天,但分析发现,0~2轮的消息不可用,不具有识别价值;
- 随着对业务和模型数据的认知,如果定位到先解决部分行业,则拉取数据要变化;
- 拉取的数据有一些处理的标签,如会话状态判别模型业务:轮次标签,订单状态等目的是为更好的理解数据分析数据用,但这些标签要考虑在数据标注阶段要删除;
数据扩量:
方法1:复杂类业务数据,人工进行:
- 数据扩量
- 标注标准明确文档版本,待标注数据文档
- 每日or双日复核抽检
- 效果+数量达标
方法2:常规类业务数据,GPT即可:
- 整理标准,及标签;
- 调整prompt,GPT帮忙进行打标
- 然后少量人工进行校准
一线业务老师宝贵经验:
- GPT打技巧:层层递进:
- 如果GPT标的不完美,可以修改标签中文描述-让GPT更容易理解
四、模型迭代
模型效果迭代核心的是有一个业务上可靠的测试集,在该测试集上进行效果持续的迭代。
迭代中,可能会发现各类问题,如:
- 标签的标准和粒度问题
- 训练数据内部问题(一致率、样本不均衡等)
- 数据的产出太慢-需加速
- ……
可多个角色一起讨论加速该过程(业务、算法、数据等)
一线业务老师宝贵经验:
- 是否有样本预处理逻辑,如果有,则要统一;
- 有的类别效果差:
- 先check是人工标注错了还是机器识别错了
- 机器错误:则可以增加该类别下的标注样本
- 人工错误:更正该样本标签
直到产出符合业务指标要求的模型,然后则可规划上线应用。
任何一个模型都离不开对应的数据集,而数据集则需要有对应的标注准则(严格程度根据业务情况不同而变化)
1、预研版标注标准
在初期,标准是模糊的,首先要确定基本的标准:
eg:分类模型:
首先要确定分类的类别,原则上分类的类别之间要相互独立,无交叉包含现象,存在歧义的时候–至少标注阶段先按照细粒度的来进行,该过程:
- 一方面结合业务场景的需要
- 一方面要分析实际的业务数据case
- 还要考虑标注的数据之间是否会有冲突,导致模型学习的数据经验混乱
比如会话状态判别模型,确定4个标注类别:「售前、售后、售前+售后、其他」
原因是:
- 一方面的确存在人来看不好区分销售阶段的case,还有一些服务消息在业务中是不需要区分销售阶段的(线下购买-线上咨询)
- 一通会话可能出现:前半段咨询售前-然后下单-然后再咨询售后;
- 为保险起见(防止这类case对其他售前or售后的数据造成污染-进而导致模型学习规律困难),在标注期间优先按照细粒度标注–单独标识——>后期可以方便灵活的合并到售前or售后or单独一个类别;
标注准则不是一天或者几次讨论就能明确下来的;–准则的复杂度与业务复杂度强相关
这个需要业务+算法同学先有基本概念,然后实际试标真实数据case,然后根据标注碰到的实际问题,然后迭代该准则
数据参考:
复杂业务标注准则:如会话状态判别模型,该过程前前后后花费了:10人天+
简单业务标注准则:情绪识别模型,该过程前前后后花费了:4人天+
一线业务老师宝贵经验:
- 前期多人标注同一份数据,找不同,确定标签和标准的歧义(标签粒度等)
- 单批次数据量要少,多来几轮,哪怕每次的标注数据量仅20条
- 但是要注意业务场景多样性的覆盖度——跨平台,跨店铺,跨类目
- 思考影响模型的因素
- 样本本身的多样性(比如会话状态判别模型:会话的聊天内容中考虑,长短、角色、轮次等)
- 标签不同人diff较大的时候,可以考虑增加标签,标签粒度尽量细,由细到粗
- 标注的时候,最好把证据显示的表示(比如把一个样本中售前售后的判断依据标红),方便复核以及数据处理
- 标注数据文档在同一个目录,以标注的次数或迭代的轮次命名
2、成熟版标注标准
预研版标注标准经过几次迭代后,当业务+算法同学在试标注过程中,发现无更多标注特例(标注中碰到的情况在标注准则中已经都覆盖或能推演出来),则此时——>标注标准进入成熟阶段;
- 成熟版的标准新人能够比较顺畅的上手,同时培训成本低
成熟阶段的标注标准也并非就是一成不变了,仍然会随着:
- 业务需求的变化
- 大量数据标注中碰到的更多意外|特殊情况
- 模型训练中发现的问题
- ……
各种情况来不断的小幅度调整该标准。
成熟后,训练模型所需要的标注数据则可以进入到扩展数量阶段(纯人工、纯GPT、人+GPT结合等等)
三、训练数据
理论介绍:
训练一个业务效果可接受模型,一般要有3个数据集:训练集、验证集、测试集;
理想状态下,3个数据集要均要能代表线上业务场景和数据的实际情况,覆盖度要全面;一些介绍理解:
训练集:这是我们用来训练机器学习模型的数据集。在监督学习中,训练集包括样本和对应的标签。我们使用训练集来拟合模型,通过调整模型的参数来最小化模型的损失函数。训练集通常占据整个数据集的大部分,比如70%或80%,因为我们希望模型能充分学习到数据中的规律。同时训练集的数据的多样性也要保障,避免数据多样性单一导致模型过拟合,那这样训练出来的模型对未见过的数据预测效果较差。
验证集:我们用这部分数据来进行模型的选择。具体来说,我们可能有多种不同的模型(或是不同参数的模型),我们用验证集来看哪个模型在未见过的数据上的表现最好。与训练集不同,我们并不使用验证集来更新模型的参数,只是用来评估模型的性能。验证集的数据规模通常比训练集小,例如占总数据集的10%或20%。
测试集:我们使用这部分数据来最终评估已经训练好的模型的性能。测试集保证了在实际应用中,我们对模型效果的估计是准确的。与验证集一样,我们并不使用测试集来更新模型的参数。测试集的数据规模通常和验证集一样,或者更小。
总的来说,训练集、验证集和测试集的划分主要是为了避免过拟合和进行模型选择。从业务效果角度来说,我们希望模型在未见过的数据上也能有好的表现,而只有一个数据集是不足以做到这一点的。通过训练集、验证集和测试集的分割,我们能更好地评估模型在真实世界中的性能。
打个比方来理解:
- 训练集相当于课后的练习题,用于日常的知识巩固
- 验证集相当于周考,用来纠正和强化学到的知识
- 测试集相当于期末考试,用来最终评估学习效果
这部分理论方面的有非常多的资料,大家尽可以在互联网上查阅;
数据获取
数据试标注+预研版数据集:
- 业务数据拉取
- 定业务数据负责人,集体粗标注,复杂业务+算法同学
- 复核(二次、三次……)
- diff数据进行讨论,标准更新
- 重复2-3-4, diff率在3左右,考虑开始扩量
- 测试集要业务老师负责产出(第三方)
一线业务老师宝贵经验:
- 拉取数据,要拉线上真实数据,即便是测服,可能与线上有差距;
- 业务数据拉取的范围:一开始要广-影响因素要足够多–可以看那些因素对结果的影响最大;
- Eg:会话状态判别模型业务
- 维度1:一开始拉取全部轮次聊天,但分析发现,0~2轮的消息不可用,不具有识别价值;
- 随着对业务和模型数据的认知,如果定位到先解决部分行业,则拉取数据要变化;
- Eg:会话状态判别模型业务
- 拉取的数据有一些处理的标签,如会话状态判别模型业务:轮次标签,订单状态等目的是为更好的理解数据分析数据用,但这些标签要考虑在数据标注阶段要删除;
数据扩量:
方法1:复杂类业务数据,人工进行:
- 数据扩量
- 标注标准明确文档版本,待标注数据文档
- 每日or双日复核抽检
- 效果+数量达标
方法2:常规类业务数据,GPT即可:
- 整理标准,及标签;
- 调整prompt,GPT帮忙进行打标
- 然后少量人工进行校准
一线业务老师宝贵经验:
- GPT打技巧:层层递进:
- 如果GPT标的不完美,可以修改标签中文描述-让GPT更容易理解
四、模型迭代
模型效果迭代核心的是有一个业务上可靠的测试集,在该测试集上进行效果持续的迭代。
迭代中,可能会发现各类问题,如:
- 标签的标准和粒度问题
- 训练数据内部问题(一致率、样本不均衡等)
- 数据的产出太慢-需加速
- ……
可多个角色一起讨论加速该过程(业务、算法、数据等)
一线业务老师宝贵经验:
- 是否有样本预处理逻辑,如果有,则要统一;
- 有的类别效果差:
- 先check是人工标注错了还是机器识别错了
- 机器错误:则可以增加该类别下的标注样本
- 人工错误:更正该样本标签
直到产出符合业务指标要求的模型,然后则可规划上线应用。







