题目为啥强调中小团队?
大团队不能用吗?不是,大团队更应该用。
但是本文的重点在于给大家展示PostgreSQL(后续简称PG),如何为中小团队赋能提效的内容,属于“不务正业”,文中会提到很多鲜为人知的使用姿势,这些技巧能促进中小产品快速迭代,避免很多重造轮子的工作。当然PG是如此稳定,任何特性在大的成熟产品上用也没有问题,问题在于产品复杂了后各个组件按理应该解耦各司其职,干各自擅长的工作,而PG主业还是做数据库用。
文章导航
一、PG介绍
PG是一款知名的开源关系型数据库,官方介绍:https://www.postgresql.org/about。近些年在国内陆续流行了起来,当然在国外一直是非常流行的。下图为2023年stackoverflow 数据库使用情况统计:
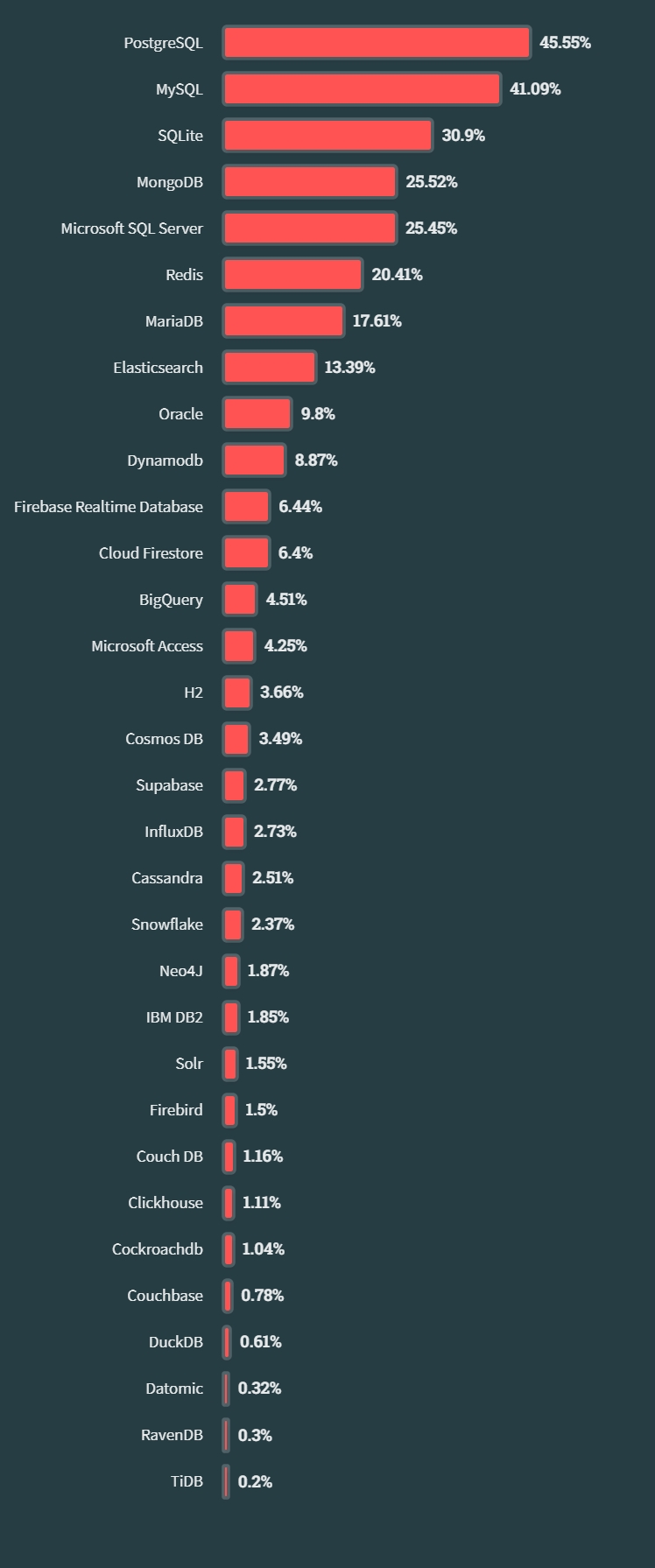

另外值得一提的是,两个上榜的知名NewSql 数据库 Cockroachdb(1.04%) 、TiDB(0.2%),前者PG协议兼容、后者MySQL协议兼容。可见PG在世界范围内还是要流行很多。
二、基于PG怎么快速迭代,让我们问题驱动
拴好安全带,马上出发。
1. 不如Mongo等NoSQL灵活?
PG也可以如此无拘无束。jsonb 可实现同等效果,不需要提前建立对应数据模型的表结构,可以像mongo一样随意插入,还可以对json中任意字段建索引。https://www.postgresql.org/docs/16/functions-json.html
示例:
create table books (
id serial primary key,
title text,
author text,
metadata jsonb # 自定义可扩展字段
);
insert into books
(title, author, metadata)
values
(
'The Poky Little Puppy',
'Janette Sebring Lowrey',
'{"description":"Puppy is slower than other, bigger animals.","price":5.95,"ages":[3,6]}'
),
(
'The Tale of Peter Rabbit',
'Beatrix Potter',
'{"description":"Rabbit eats some vegetables.","price":4.49,"ages":[2,5]}'
);2. 产品要实现模糊搜索,我需要引入ES,并把数据存一份过去?
不需要的。PG能满足你99%的搜索场景。
- 方法1:简单点的模型匹配需求,官方自带扩展pg_trgm就可以了https://www.postgresql.org/docs/current/pgtrgm.html。
但pg_trgm是每3个字符分割的,小于3个字符的搜索命中不了对应索引会比较慢,这个时候你可以使用三方扩展pg_bigm。
- 方法2:全文搜索索引 https://www.postgresql.org/docs/16/textsearch-tables.html, 它也支持jieba、zhparser等常见的分词器。
- 方法3:一些其他第三方扩展也实现了非常强的全文搜索能力,比如:PGroonga、rum
3. 功能上需要随意组合几十个字段的查询,索引个数要爆炸怎么办?
根据索引前缀匹配的原则, 确实是这样的,不同的字段组合,需要对应的索引才能命中。
这种情况,PG中, 只需要建一个包含对应那些查询字段的gin索引就可以了,不如需要各种组合。
比如:
create index concurrently idx1 on table1 using gin(a, b,c,d,e);
#命中 idx1
select * from table1 where a = x and b = xx;
#一样命中 idx1
select * from table1 where d = x and e = xx;4. 还有哪些常见的索引技巧?
PG提供了多种索引类型:B-树、哈希、GiST、SP-GiST、GIN 以及 BRIN 索引。每种索引基于不同的存储结构和算法,用于优化不同类型的查询。默认情况下,PostgreSQL 创建 B-树索引,因为它适合大部分情况下的查询。
哈希索引
通常情况下它能用btree索引代替,当索引列大小比较大,想要接口索引空间,或者值过大btree索引报错时可以使用哈希索引
create index concurrently idx_hash on table1 using hash(filed1);空间临近搜索
APP中需要搜索附近好友,怎么实现? PostGIS 扩展可满足所有几何空间相关搜索需求。
GIN索引什么时候用
GIN 代表广义倒排索引。
一般用于:(1)单个字段中包含多值的数据,比如: hstore、array、jsonb、range 等类型 (2)多列随意组合的索引场景
BRIN 块级索引什么时候用
主要适用于有着天然的时序的字段,而且该字段基本不会更新,比如订购时间,操作记录等。
它的优点是速度与btree相当,但是占用空间却只有btree的 1/12!要知道很多时候索引空间大小都赶上甚至超过数据本身大小了。
函数索引
这个非常适用,通常用于将原有数据变形处理后建索引。如果没有函数索引,恐怕你需要新增一个字段存储处理后的数据,再基于该字段建索引。
例子:
create table books (
id serial primary key,
title text,
author text, # 需要忽略大小写查询作者
);
create index func_idx1 on books(upper(name)); # upper 内置函数将字符串转换为大写
# 然后这样查询
select * from books where upper(author) = 'Mr Li';任何自定义函数都可以用于函数索引额!怎么用是不是很多困扰你很久的索引问题 突然就有解决方案了?!
部分索引
只索引真正需要检索的数据,这样可以有效避免空间的浪费。
怎么过滤那“部分数据呢”? 创建索引时加条件。
create table order (
id serial primary key,
price int,
payed bool,
goods_id text,
user_name text,
);
create index idx1 on order(user_name) where payed is true;当然查询时,需要带上 创建索引时的条件才可命中该索引。
覆盖索引
意思是只扫描索引就返回值, 而不需要再根据索引信息去随机IO取一次数据。如果对性能有极致追求,可尝试此特性。
CREATE TABLE t (a int, b int);
CREATE UNIQUE INDEX idx1 ON t USING btree (a) INCLUDE (b);
select b from t where a = 123; 上面的例子中查询会命中Index-Only模式直接返回数据,更快。
- 采集用户活动数据,操作数据,PG性能恐怕不得行,我需要搭建大数据栈?
PG只要资源够其实也能扛。
TimescaleDB了解下:https://www.timescale.com/blog/postgresql-timescaledb-1000x-faster-queries-90-data-compression-and-much-more/
90%的数据压缩比,1000相比普通查询倍级的效率提升。这个速度对常规中小产品运营分析来说应该是足够了。
6. 产品突然做大了能不能水平扩展?
可以。
- 方法一:PB级别以下只要硬件资源够单机都可以Hold住,并且可以使用自带的partition功能。
- 方法二:大表也可以使用citus分布式扩展,前两年该插件被微软收购了,以前商用的特性都开源了,比如分片间数据自动在线均衡。
7. 数据变更事件 容易管理吗?
容易。 首先PG支持常规的触发器功能,比如:
create trigger "trigger1"
after insert on "table1"
for each row
execute function trigger_func();此外,PG本身可以通过Notify/listen支持消息队列 功能。如果需要将变更通知到其他业务模块,可以结合触发器能力,将变更事件推到队列, 其他业务来消费。
另外,PG 也可以通过pg_cron扩展提供定时触发事件的能力。
8. 相比其他同类型数据库,它的优势是什么
强大的插件扩展能力。很多重要特性都是以插件方式提供服务的,有官方的比如pg_trgm, 也有第三方的比如citus
9. 我不能再问出认知边界之外的问题了, 还有什么PG相关知识可以教给我吗?
额, 那可太多了,列几个可能会帮你成功提效的功能吧。
HypoPG
HypoPG 是 PostgreSQL 的一个扩展,用于创建假设性的/虚拟的索引。HypoPG 允许用户快速创建出在PostgreSQL 查询规划器中可见的不消耗资源(CPU、磁盘、内存)的假设性/虚拟索引。
HypoPG 的动机是让用户能够迅速地寻找索引来提高慢查询的性能,而无需消耗服务器资源或等待索引的构建完成。
注:要知道很多大表建索引 动辄几个小时,时间成本很高, HypoPG可以解决大部分索引验证问题!
http扩展
假设有这样一个常规需求:需要临时去一个远程API取一批数据,然后存到本地数据表。
create extension http;
create table order (
id int,
price text,
goods_title text,
);
insert into order select "id", "price", "goods_title" from http_post('https://xxx.com/goods','{ "page": 1, "page_size": 20 }', 'application/json');怎么样快不快捷,比常规方法快多了吧?
plv8: 如果告诉你PG 可以作为一个JS FAAS平台来用, 会不会很意外?
PostgreSQL 本地运行 SQL 语言,但它也可以运行其他过程语言。
plv8 允许您运行 JavaScript 代码——具体而言,是任何在 V8 JavaScript 引擎上运行的代码。
它可以用于数据库函数、触发器、查询等等。
create extension plv8;
create or replace function hello_world(name text)
returns text as $$
let output = `Hello, ${name}!`;
return output;
$$ language plv8;基于此,外围包一层 http接口,req中指定调用函数名 & 参数, handler 中调用对应PG函数,比如:select hello_world(${arg}), 然后返回数据。
恭喜你用了2个小时实现了一个基于V8的强大的FAAS!!!
PostgREST
基于这个扩展,我们不需要自己实现上面的API 服务,直接就可以通过restful 风格的接口调用PG 进行CURD操作了。
pgjwt: JSON Web Tokens
通过pgjwt, 我们可以方便的实现jwt鉴权。
create extension pgjwt;
# 计算签名token
select
extensions.sign(
payload := '{"org":"org1","name":"name1","iat":1516239025}',
secret := 'your_secret',
algorithm := 'HS256'
);
# 验证token
select
extensions.verify(
token := 'token',
secret := 'secret',
algorithm := 'HS256'
);
- pgvector: Embeddings and vector similarity
最近流行一种观点:那些专门做向量的数据库,最终干不过PG 这类增加扩展实现向量的能力的。
不清楚是否真的这样, 让我们拭目以待。
- ……
三、最后
PG如此强大,完全得益于其优异的插件扩展能力。通过上述介绍你可以发现,它早已经不只是一个关系型数据库了。需要大家基于它能玩出更多花活。







