在数据驱动决策的今天,数据平台的稳定性与高效性显得尤为重要。今天,我想跟大家分享一个我之前在工作中亲身经历的事故,这次事故发生在Doris集群上,始于一个看似普通的业务日志报错——Doris集群数据写入异常。
文章导航
一、Doris集群数据写入异常的原因是什么?
工作背景是三台8c16g的云主机部署了一个3FE、3BE的Doris集群。
那天,业务日志突然报错,doris集群数据写入异常,我查看监控发现集群有两个节点cpu负载持续拉满,内存也居高不下,两节点还频繁出现unhealthy的tablet。
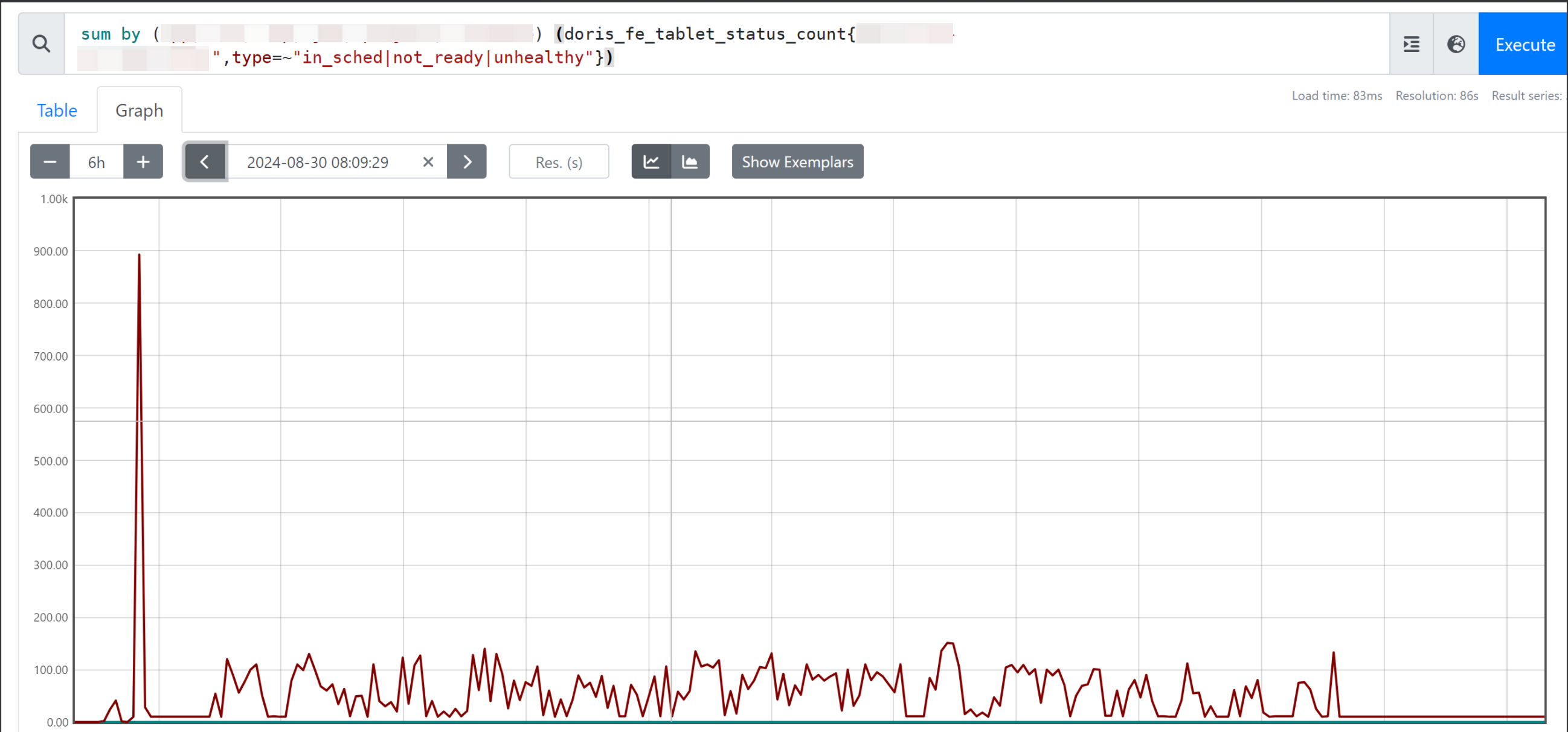

于是我迅速开始组织同事排查异常原因,调查异常开始发生的时间节点业务是否存在变动。结果发现是有人对一张千万级别的表进行了全量update操作,当操作停止后负载瞬间下降却又突然暴涨并处于持续拉满状态。查看日志、查询正在执行的语句都并未发现异常。
二、全量update操作后怎么降低负载,解决问题?
我首先尝试自行解决问题,通过触发Java程序的全量GC释放内存,起到了极短时间的效果,但很快又恢复到负载拉满的状态。
于是我转而向官方的社群反馈现象,并寻求解决办法,尝试多种方法后依然没有解决问题,束手无措之际只能选择滚动重启了BE实例,负载高的问题解决了。但随后又发现了新的问题,之前执行update的那张表出现了unhealthy的tablet,且无法修复,该表也就无法进行任何的增删改查操作,和官方沟通后确定数据丢失了一部分。
此时就只剩下两个处理方法:
- 使用空副本填充(从回收站恢复 – Apache Doris);
- 删表重建并从备份恢复数据
经历这次危机,我思考改进了操作方式,选择采用类似update操作的其他方式:
- 选 agg 模型的表更新,不使用unique
- 使用insert到新表的方式
结语
经过这一系列的排查、尝试与最终的解决方案实施,也只是堪堪恢复了Doris集群的正常运行。这次事故让我意识到,在大数据处理与实时查询系统中,任何细微的操作都可能引发连锁反应,因此,在日常工作中,我们需要更加注重操作的规范性和数据备份的重要性。也希望这次分享对你有帮助。
延展阅读:
2024双11淘宝3000亿国家补贴怎么领?成都家电以旧换新线上线下使用入口在哪里?
企业微信客服会话服务质量如何考核?如何统一评估私域公域客服会话服务水平?







