在数据管理的广阔天地中,PostgreSQL(简称 pg)以其卓越的在线事务处理(OLTP)能力而闻名遐迩,其强大的事务处理能力和坚如磐石的可靠性赢得了业界的广泛赞誉。然而,在面对需要大规模数据分析的场景时,PostgreSQL有时会显得力不从心,其响应速度难以满足高效分析的需求。正是在这样的背景下,DuckDB作为一款高效的列式数据库引擎,开始在数据分析领域崭露头角,引起了业界的广泛关注。
DuckDB以其轻量级的设计和卓越的查询性能,在处理大规模数据集时展现出了非凡的能力。它不仅能够为数据湖(Data Lake)或湖屋(Lakehouse)架构提供快速、便捷的分析能力,更是推动数据分析向更高效、灵活的方向发展的重要力量。在这样的大环境下,pg_duckdb作为一项创新的扩展,为PostgreSQL注入了新的活力,仿佛为这头数据管理领域的大象插上了翅膀。
pg_duckdb是一个将DuckDB的分析引擎直接集成到PostgreSQL中的扩展,它允许用户在传统的事务工作负载上快速进行数据分析查询。这种深度集成不仅为用户提供了一种便捷、简单且高效的数据分析架构,还使得用户能够快速执行复杂的分析查询,充分挖掘数据的潜力。
接下来,让我们快速体验一下pg_duckdb的强大功能,感受其带来的高效数据分析能力。
- 集成优势:pg_duckdb通过将DuckDB的列式存储和查询优化技术与PostgreSQL的事务处理能力相结合,为用户提供了一个强大的数据分析平台。这种集成不仅简化了数据架构,还提高了数据处理的效率。
- 性能提升:DuckDB的列式存储和压缩技术使得数据在存储和查询时更加高效。与传统的行式数据库相比,列式数据库在处理分析查询时能够更快地读取和处理数据,从而显著提升性能。
- 灵活性增强:pg_duckdb允许用户在不改变现有PostgreSQL架构的情况下,直接利用DuckDB的强大分析能力。这意味着用户可以在同一个数据库中同时处理事务和分析工作,无需在不同的系统之间迁移数据。
- 易用性:pg_duckdb作为一个PostgreSQL扩展,保持了PostgreSQL的易用性。用户可以利用熟悉的SQL语法来执行复杂的分析查询,无需学习新的查询语言或工具。
- 扩展性:随着数据量的增长,pg_duckdb可以轻松扩展以适应更大规模的数据分析需求。DuckDB的设计允许它在分布式环境中运行,这意味着用户可以水平扩展他们的分析能力。
通过pg_duckdb,PostgreSQL用户现在可以享受到DuckDB在数据分析方面的优势,同时保持了PostgreSQL在事务处理方面的稳定性和可靠性。这种结合为数据分析提供了一个全新的维度,使得数据管理更加高效和灵活。
文章导航
优缺点
pg_duckdb 的潜在优势:
- 性能提升:DuckDB 的列式存储和查询优化可以显著提高 PostgreSQL 在处理大规模数据集时的性能。
- 简化架构:用户无需在 PostgreSQL 和其他分析数据库之间迁移数据,可以直接在 PostgreSQL 上进行分析,简化了数据架构。
- 灵活性增强:DuckDB 支持多种数据格式和查询语言,这使得 PostgreSQL 能够处理更多样化的数据和查询需求。
- 成本效益:通过在 PostgreSQL 上直接进行分析,可以减少额外的硬件和软件成本。
- 实时分析:DuckDB 的实时分析能力可以让用户在处理事务的同时进行数据分析,无需等待数据同步。
实施 pg_duckdb 可能面临的挑战:
- 兼容性问题:确保 PostgreSQL 和 DuckDB 在数据类型、查询语言等方面完全兼容可能是一个挑战。
- 数据一致性:在两个系统之间同步数据时,保持数据的一致性是一个关键问题。
- 性能调优:虽然 DuckDB 提供了高性能的分析能力,但在实际部署中可能需要针对特定工作负载进行性能调优。
- 社区和支持:作为一个相对较新的技术,从而在旧版软件和操作系统的兼容性不咋兼容以及pg_duckdb 可能缺乏广泛的社区支持和文档。
- 安全性和合规性:集成两个不同的数据库系统可能需要额外的安全措施,以确保数据的安全性和符合相关法规。
验证
实验条件
- line表测试数据:3亿+

- local_table:少量数据,由于实验条件有限,所以仅仅写入1W条
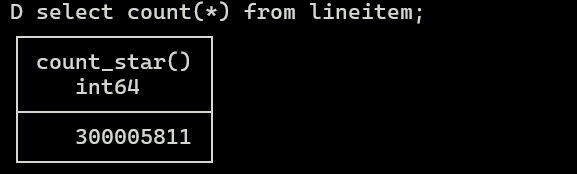
场景1:直接查询PG中本地表
通过直接查询PG本地表,创建索引后,查询耗时接近5min分钟
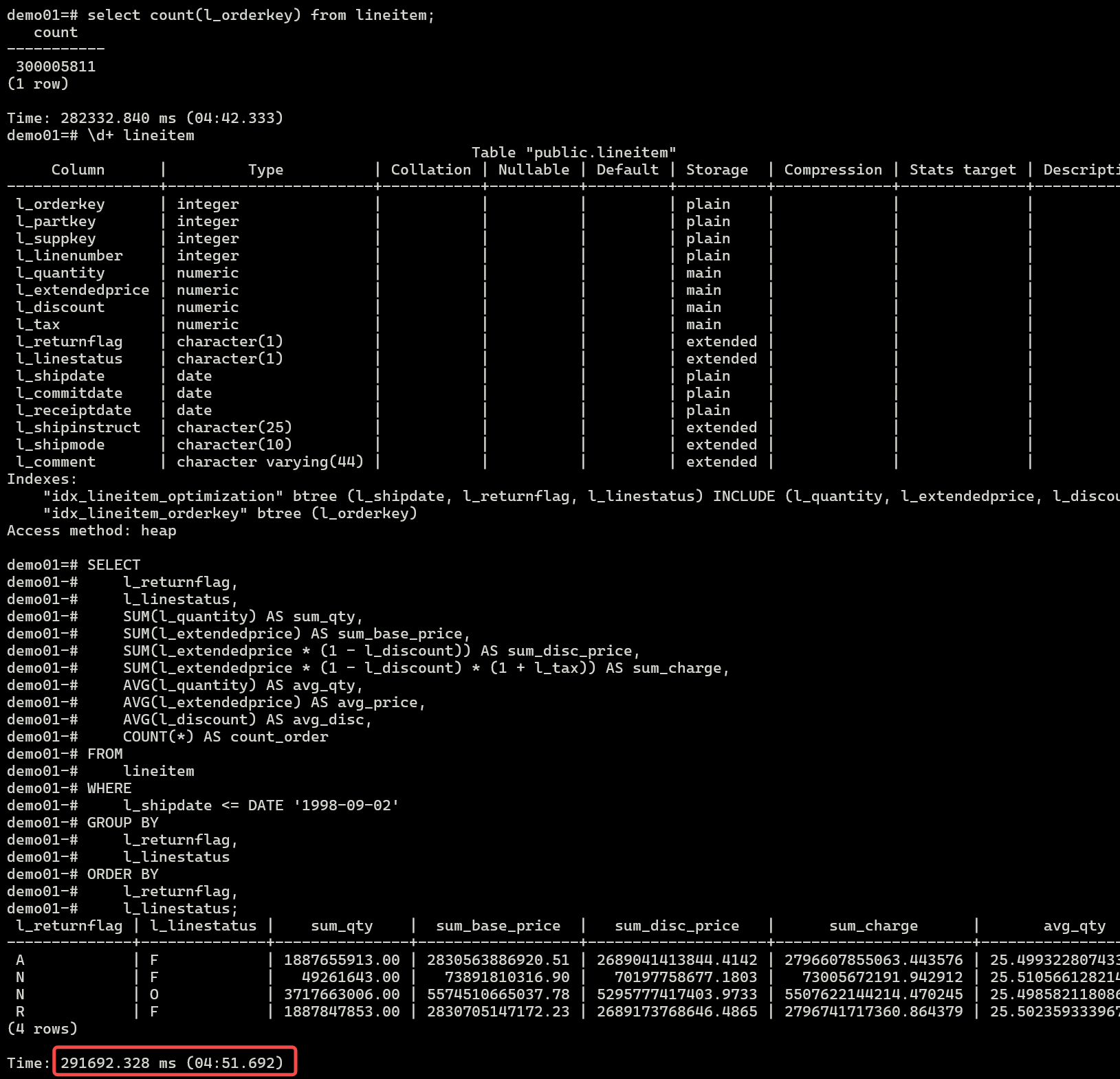
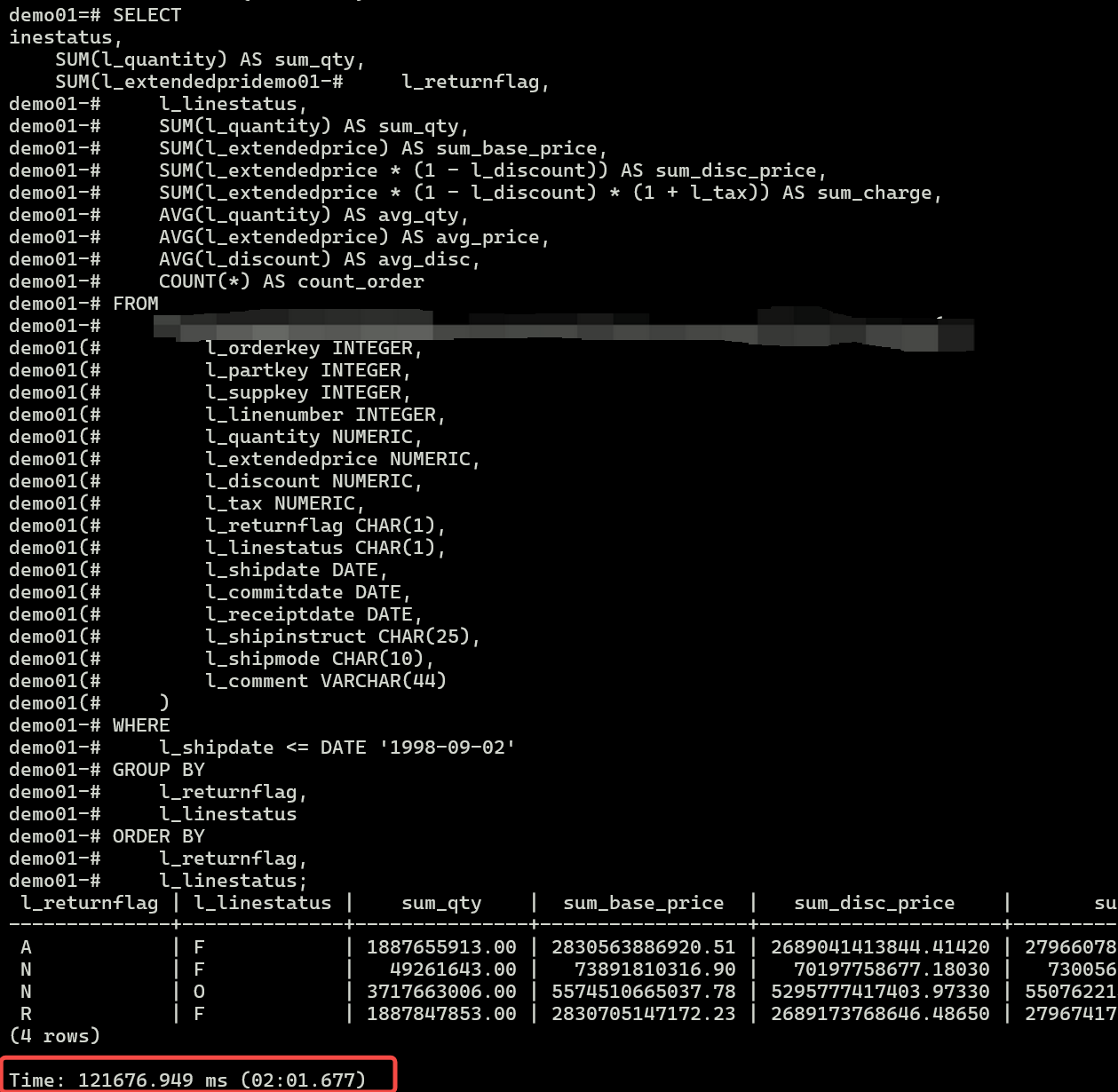
场景2:通过duckdb引擎查询
现在通过duckdb引擎查询,可以发现耗时在2min左右,相比查询PG本地表时间节约1半+
场景3: 本地表和duckdb联合查询
比如某些大表用duckdb查询+本地表进行过滤筛选,从而加速查询
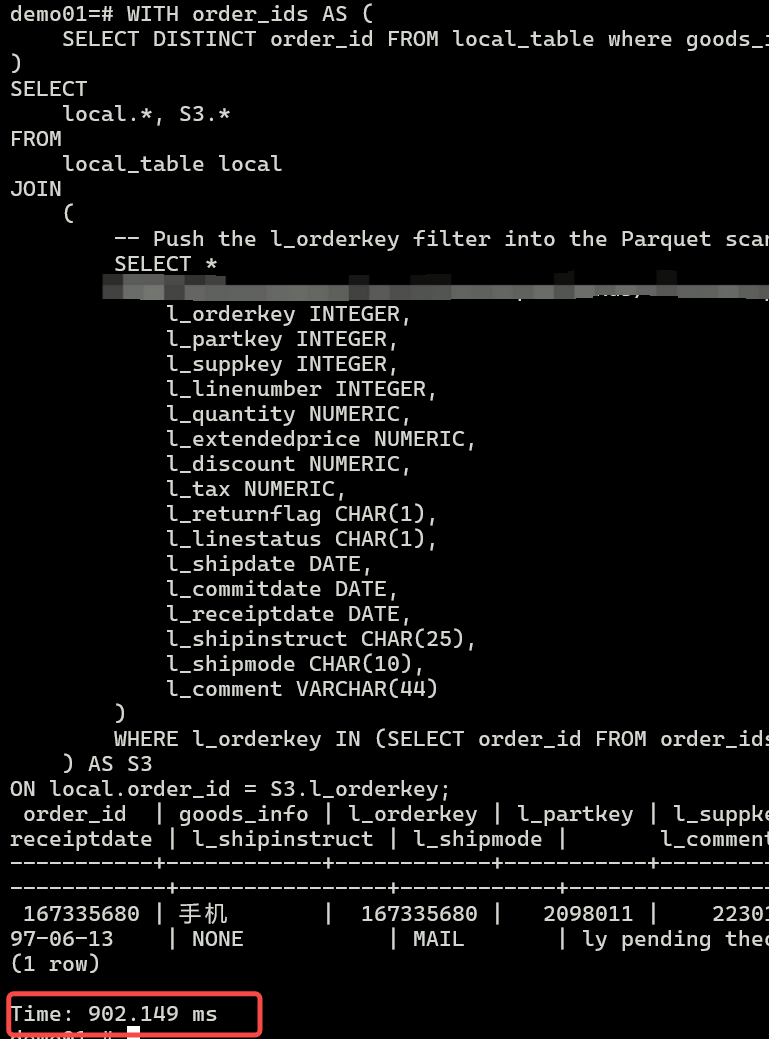
通过如上三类场景,即可发现,pg+duckdb完成OLAP的分析是可行的。
展望
通过上面的场景验证,可以对pg+duckdb有如下展望:
- 不管是ck还是doris均支持导出为parquet模式,这样就可以将历史悠久数据导出保存到oss,并且通过oss的声明周期来管理数据的归档或者过期
- ck、doris数据库,尽量保存热数据,温数据或者冷数据即可导出到oss,从而节约成本并且不用将ck、doris复杂化
- 减少了业务数据关联时候的导入导出等复杂逻辑流程







