在现代信息检索领域,多通道召回和精确匹配的结合已成为提高搜索系统准确性和效率的基石。随着GPT-4等大型模型的出现,这些技术已经发展到利用先进的算法、深度学习方法以及大模型。本文将深入探讨大型模型多路召回的原理、实现和应用。
文章导航
一、什么是多路召回?
多路召回是指使用多种检索方法和策略从庞大的数据集中检索相关信息的过程。这种方法通过利用不同的视角和技术来确保全面准确的回忆。
多路召回类型详解:
1. 基于关键字的召回:利用传统的关键字匹配技术,通常通过倒排索引实现,快速检索包含特定术语的文档。
2. 基于向量的召回:采用向量表示和相似度计算来执行语义级检索,使其适用于自然语言处理任务。
3. 融合检索(Fusion Retrieval):结合多种检索方法(例如,基于关键字和向量的),并使用互惠排名融合(RRF)等算法对结果进行重新排序。
4. 递归分层检索(Recursive Retrieval):采用分层方法逐步过滤和优化结果,提高召回率。
二、融合检索
融合检索(Fusion Retrieval)结合多种检索方法,通过排序算法(如RRF)对召回结果进行重新排序和融合,以弥补单一向量索引在检索精确性上的不足。
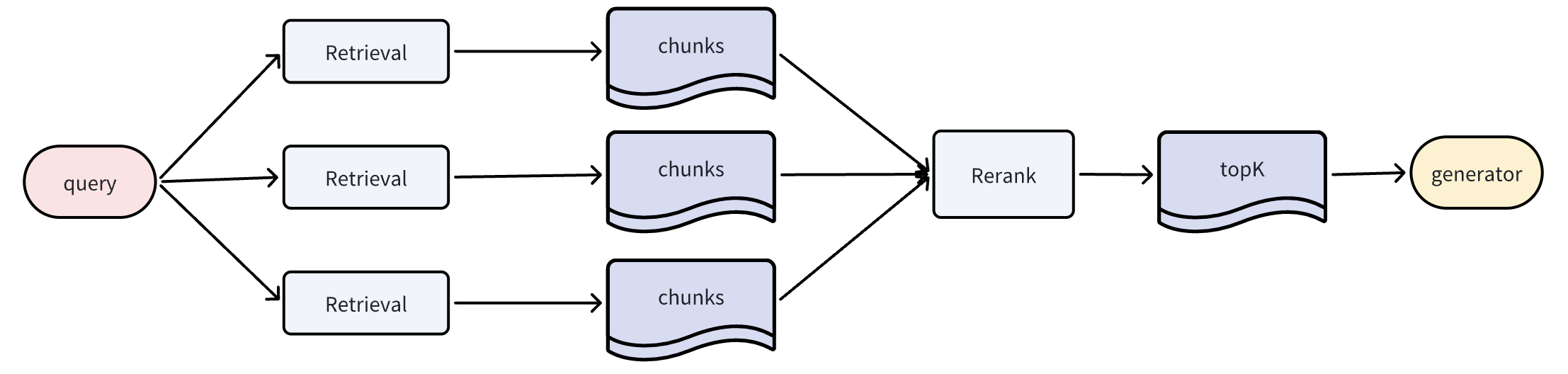

基于问题重写与扩展
通过查询重写扩展输入问题,生成多种表达形式并分别检索,然后使用重排模块对召回的知识块重新排序,取最终的top_K用于后续生成。
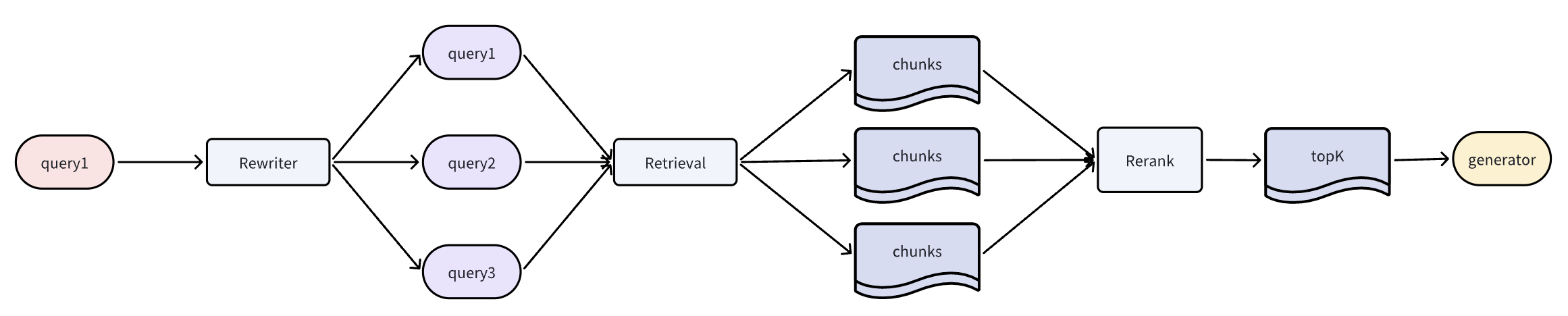
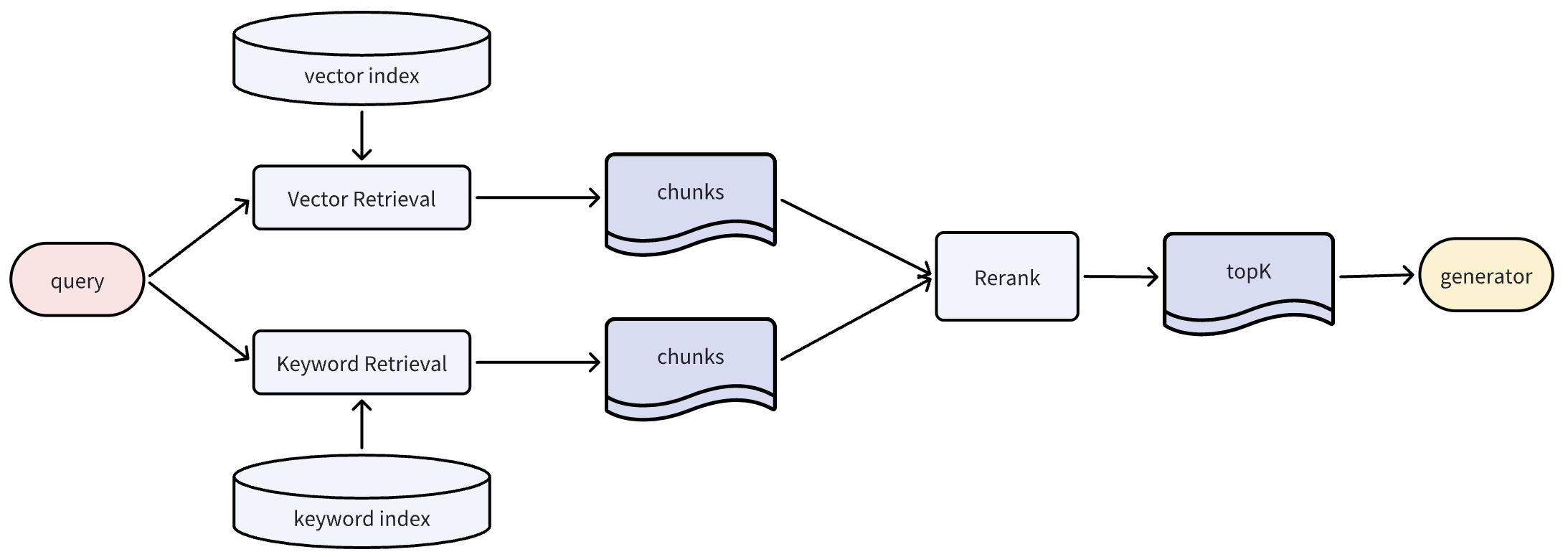
基于多种类型的索引扩展
虽然高维向量索引在自然语言语义检索中表现良好,但并非万能。你可以使用知识图谱索引获取实体关系,或树状摘要索引回答概要性问题。因此,可以通过多种索引类型(如向量索引和关键词索引)检索输入问题,并对召回的知识块重排序后获取top_K结果。
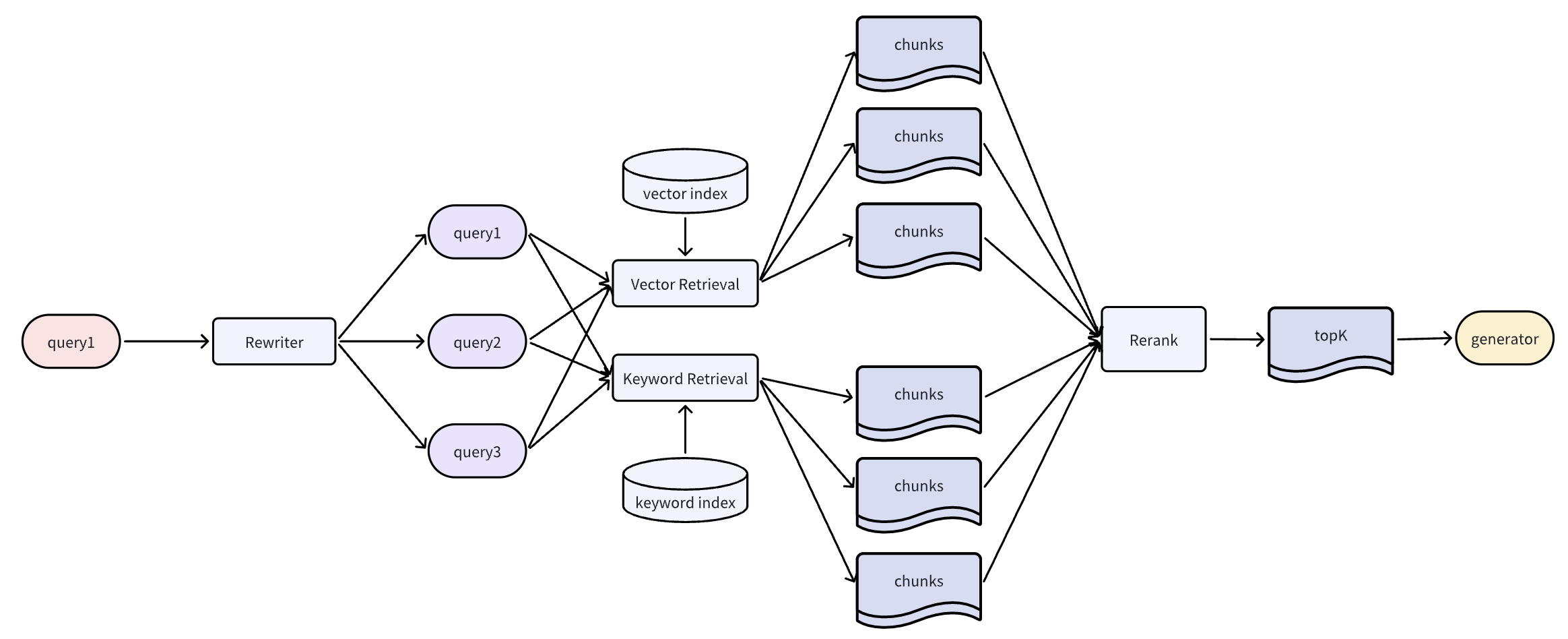
基于复合方案的多路检索
这是一种结合问题扩展和索引扩展的方法,通过多路知识召回和重新排序获得top_K结果。虽然这种方法能获取更相关的知识,但也增加了系统性能消耗和模型使用成本,需要根据测试结果进行取舍。
融合检索关键技术
实现融合检索并不复杂。在LangChain或LlamaIndex框架中,可以通过组合转换器、检索器和排序器来实现。
- 查询扩展:使用LLM自行实现,或使用现有组件如LlamaIndex的QueryTransform。
- Reranker:自行实现RRF算法,或使用Cohere Reranker等专业排序模型。
- 检索融合:扩展现有的Retriever组件,或使用现成的融合检索器如LlamaIndex的QueryFusionRetriever。
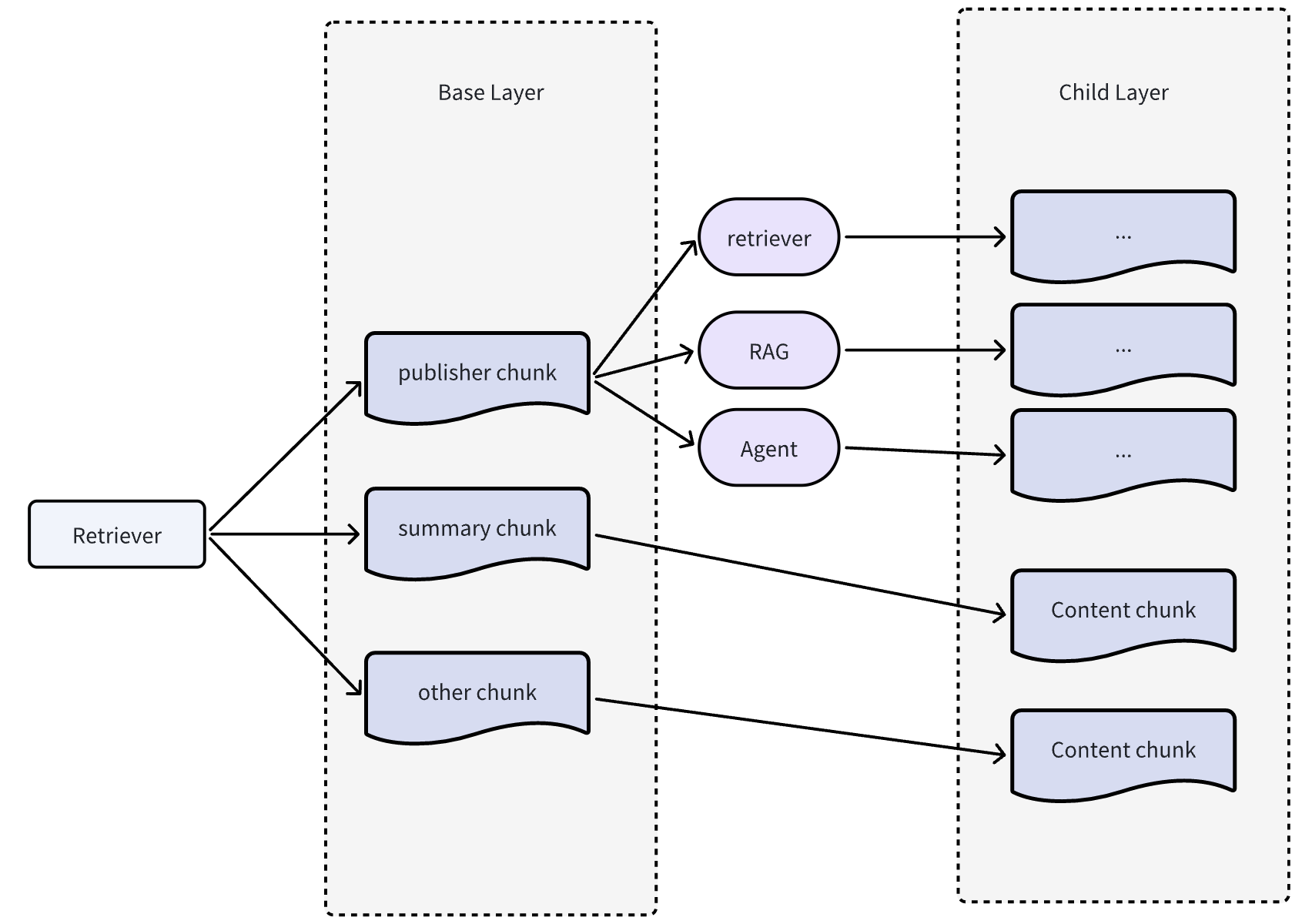
三、递归分层检索
相比易于理解的融合检索,递归检索更复杂。它类似于在大量书籍中找到特定段落的过程:
- 进行基本过滤(如出版社)。
- 查看书籍简介,缩小范围。
- 在少量书中,通过目录和翻阅找到目标内容。
递归检索本质上是在不同层次上构建节点和检索器,并建立层次间的链接,实现自动向下递归探索,直到找到目标内容。
四、多路召回的应用场景与实践
多路召回在搜索中是常见的操作,主要是为了应对用户提问的复杂性和内容的多样性。以下是多路召回的几个维度及其使用场景:
- 意图/路由划分:根据不同需求采取不同操作。例如,查音乐和查天气需要不同的内容召回路径。音乐查询可能涉及歌手、歌名、流派等,而天气查询则直接调用天气接口。
- 不同内容结构:例如,音乐和购物的数据结构不同,但用户的查询可能模糊。多路召回可以同时处理这些模糊查询,具体优先级可以在后续精排层决定。
- 不同检索方式:例如,向量召回和字面召回可以分开处理,以提高检索效率。
- 不同表征方式:基于不同的表征特征,可以有多种召回方式。例如,向量召回可以基于不同的表征目标和特征进行多样化处理。
多种召回方式通常是并发进行的,以节省时间并提高效率。
五、多路召回在不同领域的应用
1、电子商务推荐系统:在电子商务平台中,多渠道召回和精确匹配用于推荐产品。通过结合用户的搜索历史、浏览记录和购买行为,该系统可以准确地建议用户可能感兴趣的产品。
2、智能客户服务系统:智能客户服务系统利用多渠道召回从知识库中检索潜在答案。然后,精确匹配会过滤这些答案,以提供最合适的响应,从而提高用户满意度。
3、内容推荐系统:内容推荐系统使用多通道召回来从庞大的数据集中过滤相关内容。精确匹配可确保推荐的内容与用户兴趣紧密结合,从而提高参与度。
总结
在信息爆炸的时代,搜索系统的准确性和效率变得尤为重要。多路召回和融合检索技术的结合,为解决这一问题提供了强有力的支持。通过利用大模型和先进算法,检索系统不仅能提供更加精确的搜索结果,还能更好地理解用户意图,满足复杂多样的需求。在双11这样的电商大战中,结合Stable Diffusion等创新技术,不仅能提升品牌的市场竞争力,还能为用户带来更优质的购物体验。
延展阅读:







