多模态(multimodality)指 NLP 即文本 + 一种或多种其他模态(图像、语音、音频、嗅觉等)。对于“另一种模态”,我们将主要关注图像。
为什么重要:
- 忠实:人类体验是多模态的
- 实用:互联网和许多应用程序都是多模态的
- 数据效率和可用性
多模态是当前基础模型革命的主要前沿之一。
文章导航
一、多模态应用是什么
假设处理两种模态 – 文本和图像:
- 检索(retrieval, image <-> text)
- 图像描述(captioning, image -> text)
- 生成 (generation, text -> image)
- 看图问答 (visual question answering, image+text -> text)
- 多模态分类(multimodal classification, image+text -> label)
- 理解与生成(better understanding/generation, image+text -> label/text)
二、多模态应用发展主线
- 早期模型(early models)
- 特征与融合(features and fusion)
- 对比模型(contrastive models)
- 多模态基础模型(multimodal foundation models)
- 评测(evaluation)
- 超越图像:其它模态(beyond images: other modalities)
三、多模态早期模型有哪些
跨模态“视觉语义嵌入”
跨模态“视觉语义嵌入”(Cross-modal “Visual-Semantic Embeddings”)
WSABI(Weston et al 2010), DeVise(Frome et al 2013), Cross-Modal Transfer(Socher et al 2013)
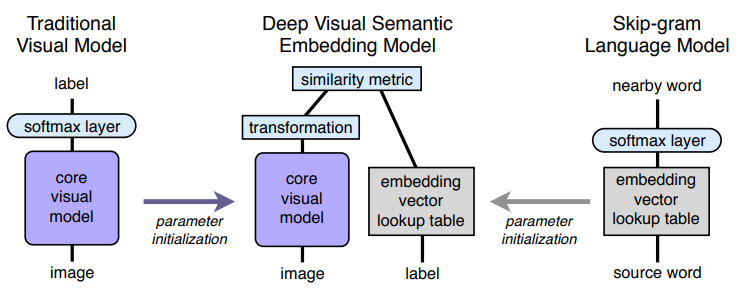

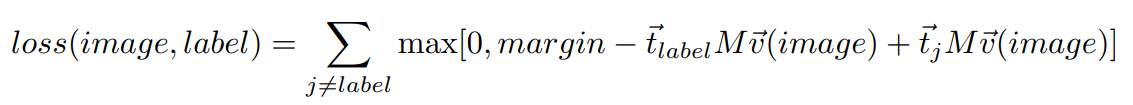
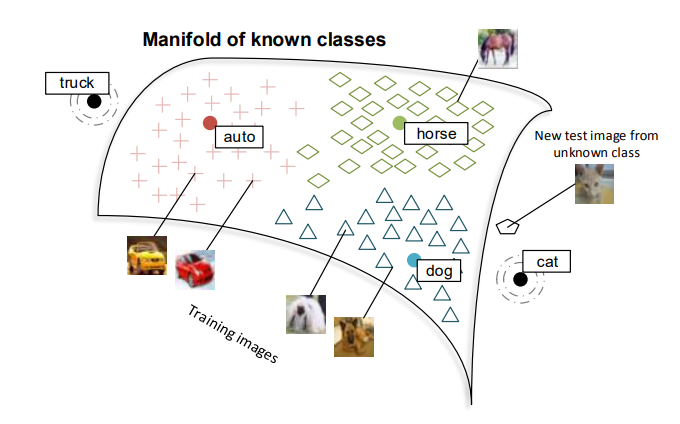
超越单词:句子级别对齐
Ground Compositional Semantics (Socher et al., 2013)
Visual-Semantic Embeddings (Kiros et al., 2014; Faghri et al., 2015)
Visual-Semantic Alignment (Karpathy & Li, 2015)
Grounded Sentence Representations (Kiela et al., 2016)
Hinge/margin-like loss as in WSABI/DeViSE.
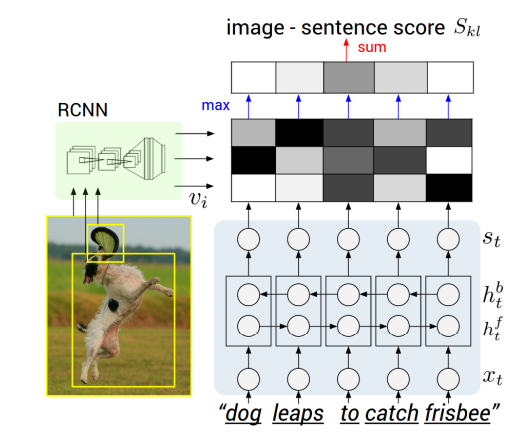
Karpathy & Li, 2015
图片转文本:图像描述
Show and tell (Vinyals et al., 2015)
Show, attend and tell (Xu et al., 2016)
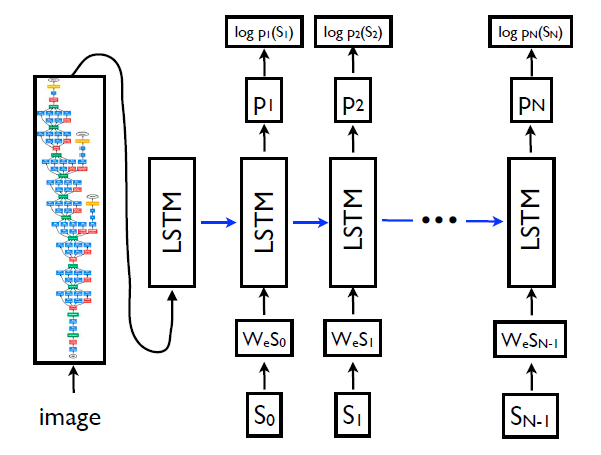
Vinyals et al., 2015
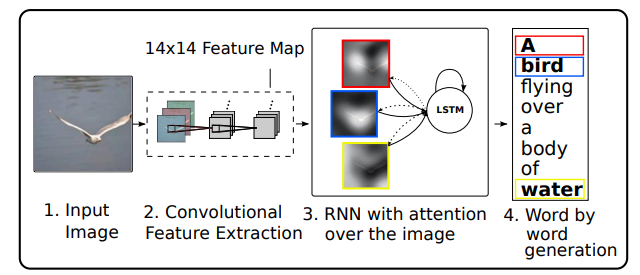
Xu et al., 2016
文本转图像:条件图像合成
Generative adversarial nets (Goodfellow et al. 2014)
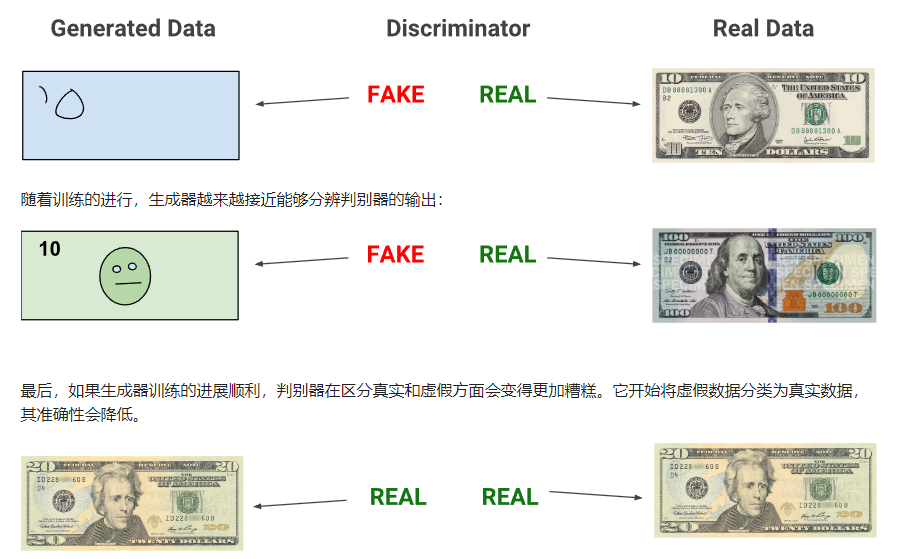
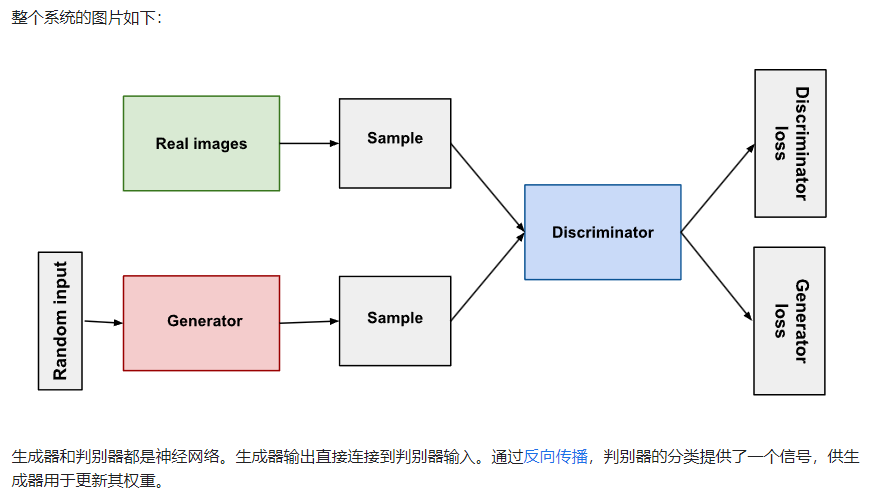
四、多模态特征与融合
多模态的问题
如果它如此重要,为什么并非每个系统都从一开始就是多模态的?
- 一种模态可以支配其他模态 (One modality can dominate other modalities)
- 额外的模态可能会增加噪音 (Additional modalities can add noise)
- 无法保证模态的全面覆盖 (Full coverage over modalities is not guaranteed)
- 我们还没有准备好
- 情况很复杂
特征(Features)
文本特征:Batch_size x Sequence_length x Hidden_size.
图像特征:
- 稀疏“区域”特征(Sparse region features)
- 对象监测
- 稠密特征
- ConvNet 的层和特征图
- Vision Transformer 的层
多模融合(Multimodal fusion)
- 相似性(Similarity)
- 内积(Inner product):uv
- 线性/求和(Linear/sum)
- 连接(Concat):W[u, v]
- 求和(Sum):Wu+Vv
- 最大值(Max):max(Wu, Vv)
- 乘法(Multiplicative)
- 乘法(Multiplicative):Wu⊙Vv
- 门控(Gating):σ(Wu)⊙Vv
- LSTM风格:tanh(Wu)⊙Vv
- 注意力(Attention)
- 注意力(Attention):αWu+βVv
- 调制(Modulation):[αu,(1-α)v]
- 双线性(Bilinear)
- 双线性(Bilinear):uWv
- 双线性门控(Bilinear gated):uWσ(v)
五、存在什么对比模型
CLIP (Radford et al. 2021)
与之前的 contrastive loss 完全相同,但是..Transformers 和*web data*!
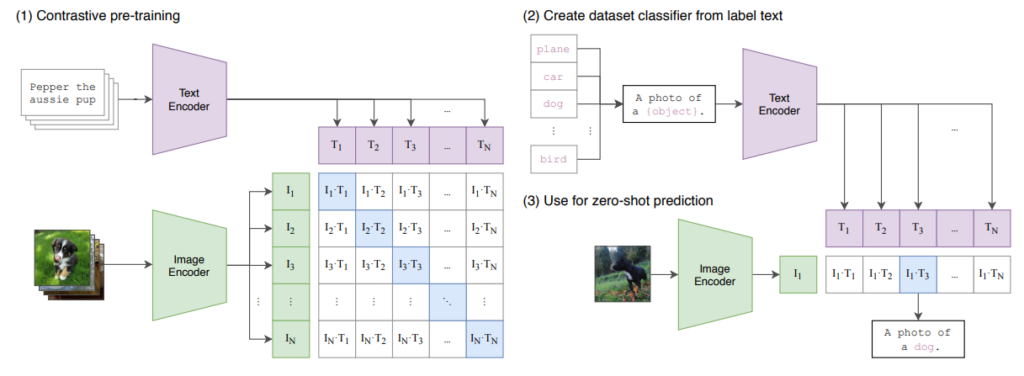
泛化能力超强:

ALIGN (Jia et al., 2021)
同样的想法,但更多的数据 (JFT at 1.8B image-text pairs vs CLIP’s 300m)
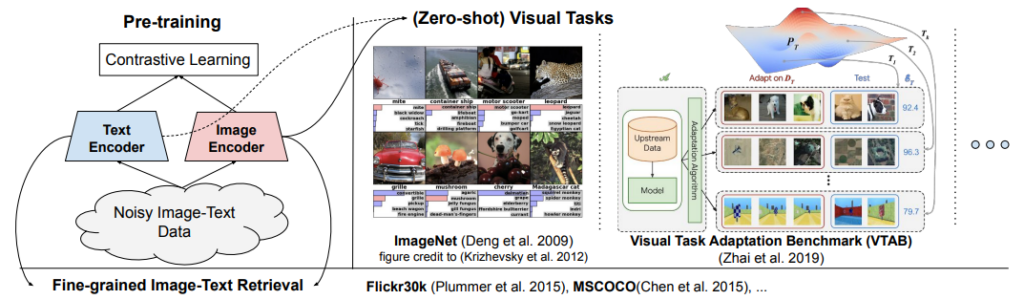
对齐数据集
现存大量图像-文本对的开源数据集,例如用于训练 StableDiffusion(Rombach et al., 2022)的 LAION-5B: An open large-scale dataset for training next generation image-text models
https://laion.ai/blog/laion-5b
六、多模态基础模型
Visual BERTs: ViLBERT


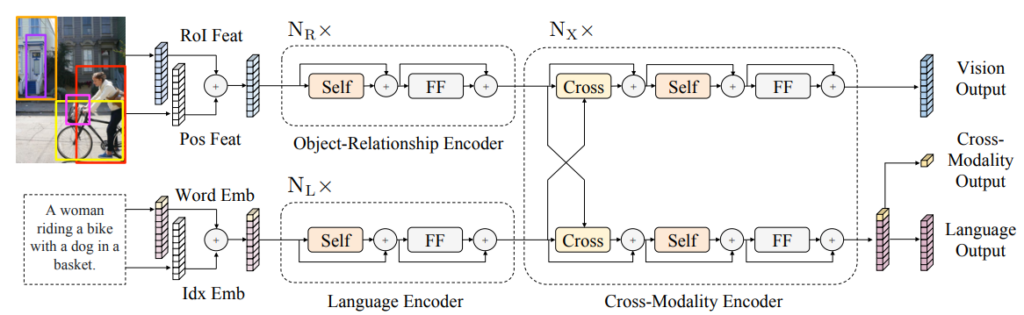
Visual BERTs: LXMERT
从 Transformers 学习跨模态编码器表示
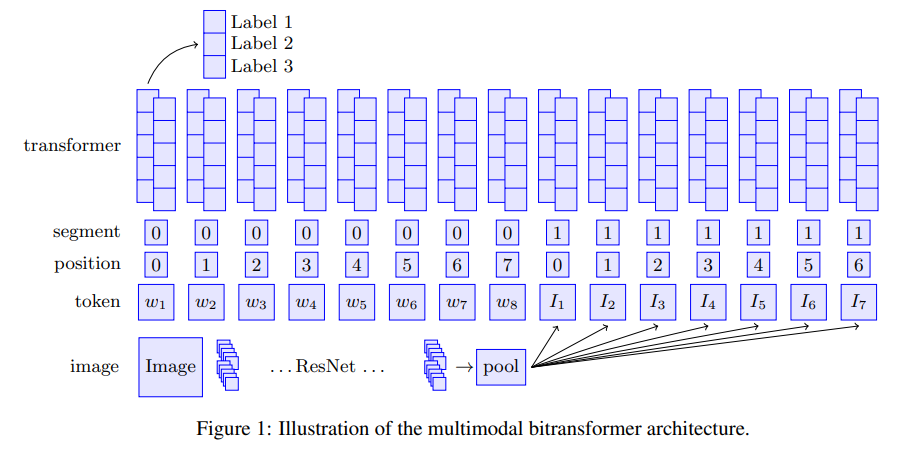
Visual BERTs: Supervised Multimodal Bitransformers
SimVLM (Wang et al., 2022)
Slowly moving from contrastive/discriminative to generative.
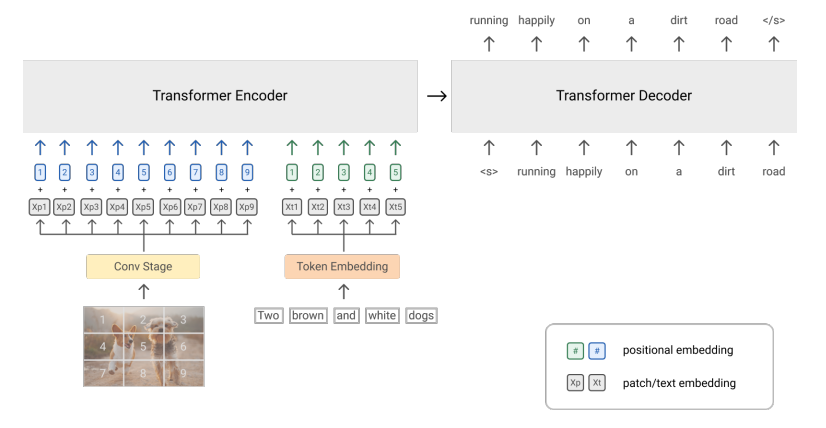
CoCa Contrastive Captioner (Yu et al., 2022)
Best of both (contrastive and generaative) worlds.
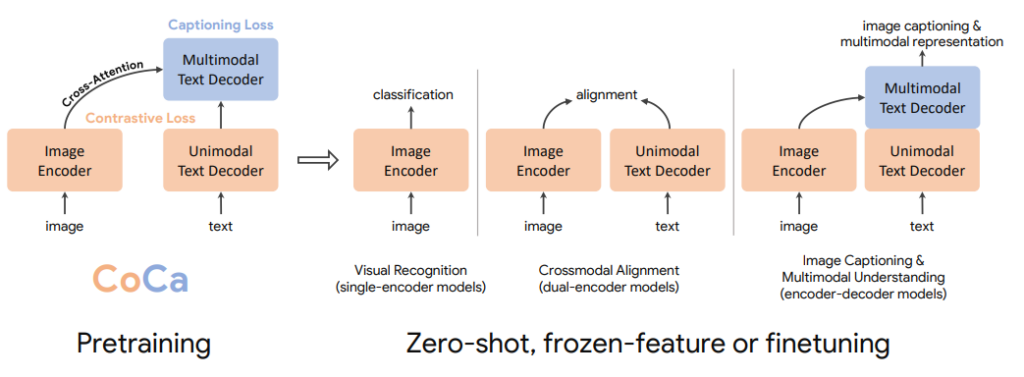
Frozen (Tsimpoukelli, Menick, Cabi, et al., 2021)
有点像 MMBT,但有更好的 LLM(T5)和更好的视觉编码器(NF-ResNet)。
Multi-Modal Few-Shot Learners!
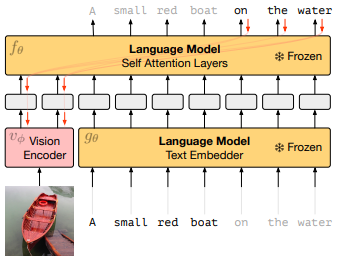
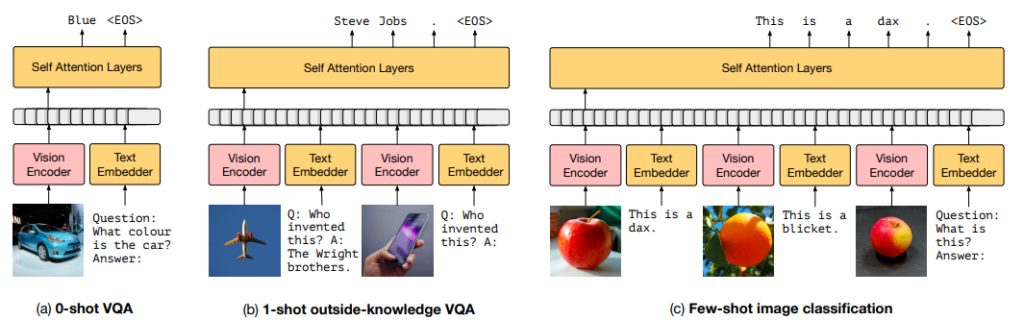
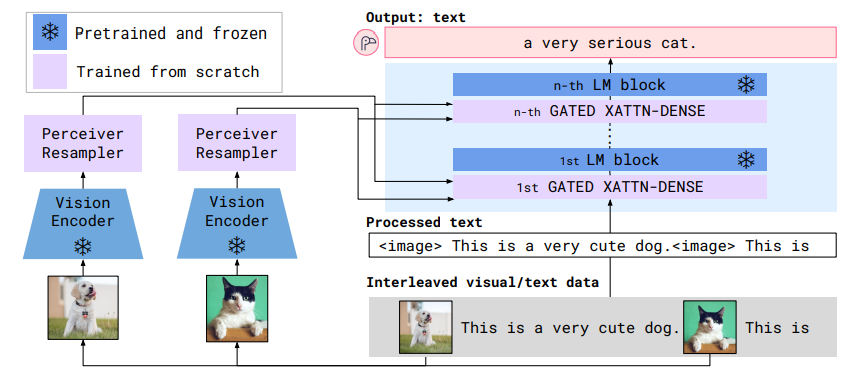
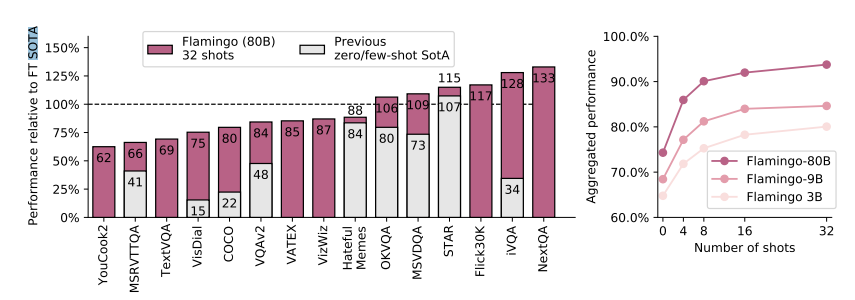
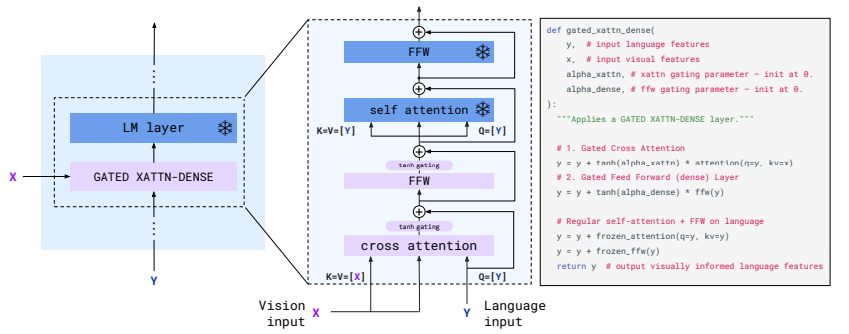
Flamingo (Alayrac et al., 2022)
80b param model based on Chinchilla.
Multi-image.
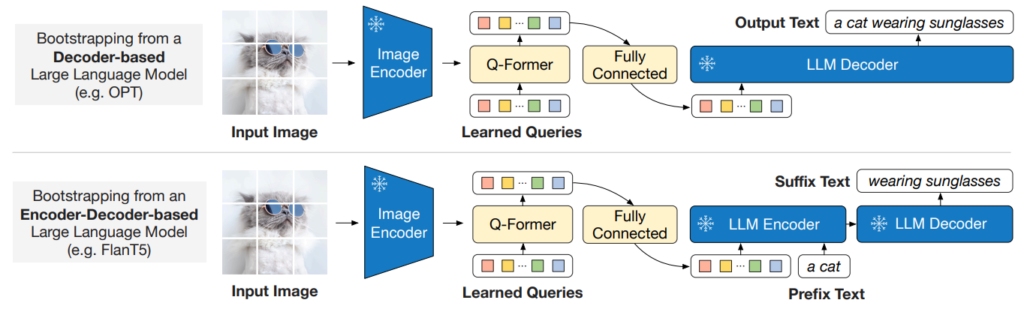
BLIP/BLIP2 (Li et al., 2023)
Freeze it all (CLIP-ViT / OPT decoder / FlanT5 encoder-decoder)

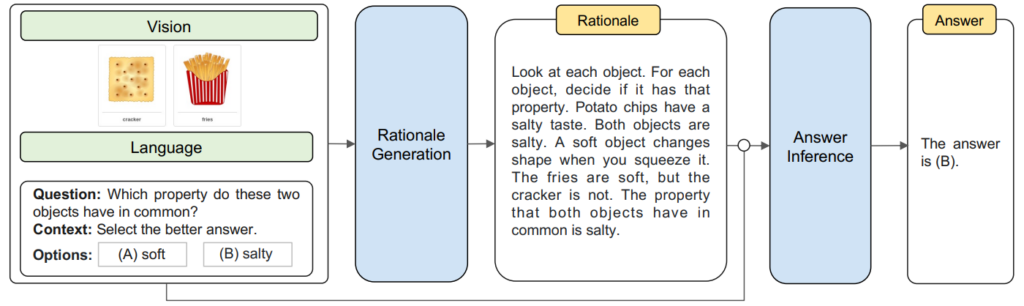
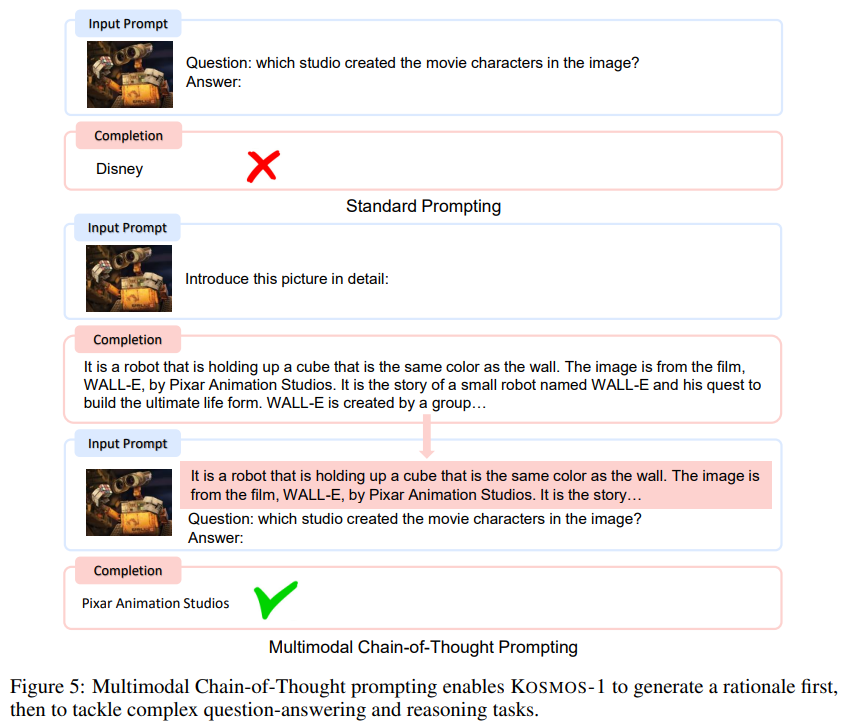
Multimodal “Chain of Thought” (Zhang et al., 2023)
Providing a rationale helps give the right answer.
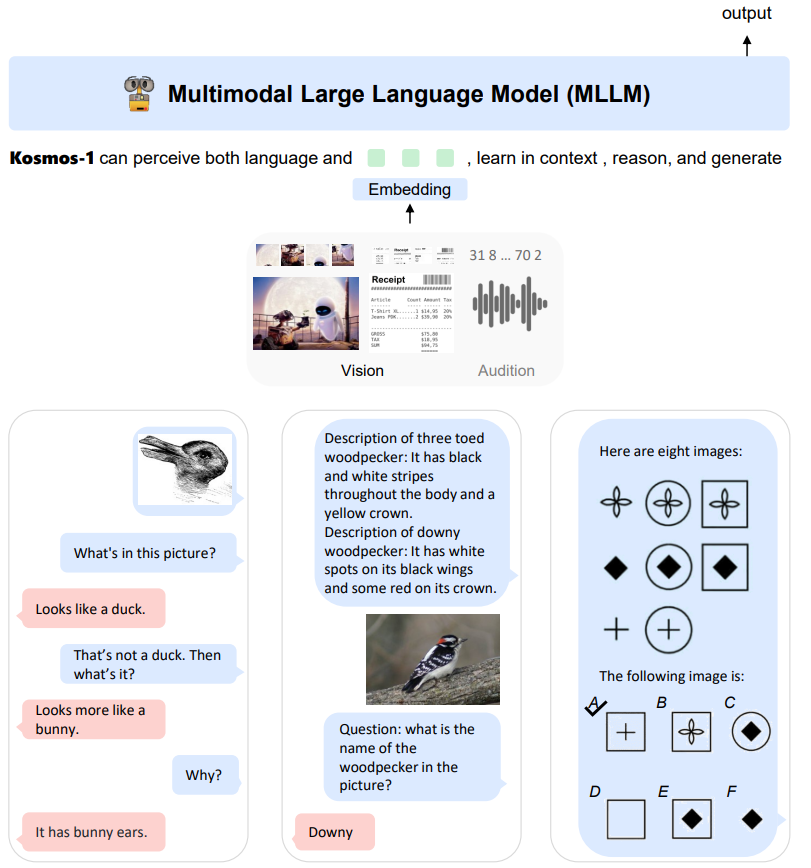
KOSMOS-1 (Huang et al., 2023)
LLMs => MLLMs == FMs
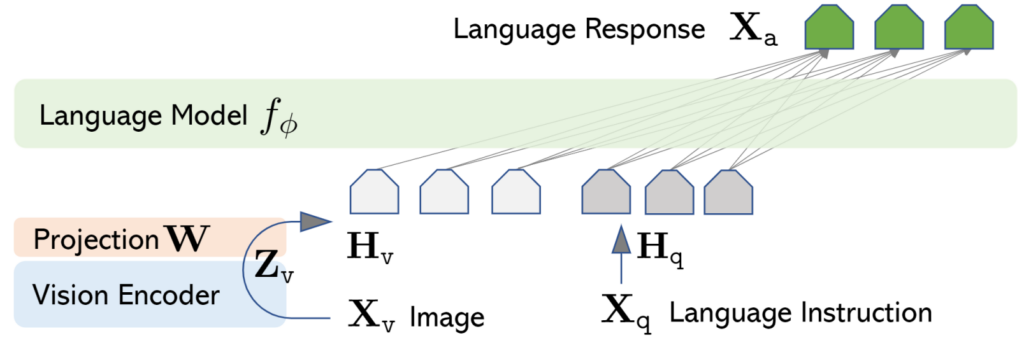
LLaVA: Large Language-and-Vision Assistant
LLaVa 使用简单的投影矩阵连接预训练的 CLIP ViT-L/14 视觉编码器(visual encoder)和大语言模型 Vicuna。是一个两阶段的指令微调过程:
- 第 1 阶段:特征对齐的预训练。仅基于 CC3M 的子集更新投影矩阵。
- 第 2 阶段:端到端微调。投影矩阵和 LLM 均针对两种不同的使用场景进行更新: 可视化聊天:LLaVA 针对我们生成的多模式指令跟踪数据进行了微调,用于面向日常用户的应用程序。 Science QA:LLaVA 在科学领域的多模态推理数据集上进行了微调。
七、多模态使用情况评测
COCO – Common Objects in Context
Super impactful datasets (Lin et al. 2014; Chen et al. 2015)
Main multimodal tasks:
- Image captioning
- Image-caption retrieval
Similar datasets:
- Flickr30k, ConceptualCaptuions, VisualGenome, SBU, RedCaps, LAION
VQA – Visual Question Answering (Antol et al., 2015)
VQA是一个视觉问答数据集,包含有关图像的开放式问题。这些问题需要对视觉、语言和常识知识的理解才能回答。

OK-VQA
OK-VQA是更难的视觉问答数据集,它需要利用外部知识来回答关于图像的问题。

TextVQA
TextVQA 要求模型能够读取和推理图像中的文本,以回答有关问题。具体来说,模型需要结合图像中存在的文本并对其进行推理以回答问题。

what brand liquor is on the right?
ChartQA
图表在分析数据时非常流行。在探索图表时,人们经常会提出各种复杂的推理问题,其中涉及多种逻辑和算术运算。
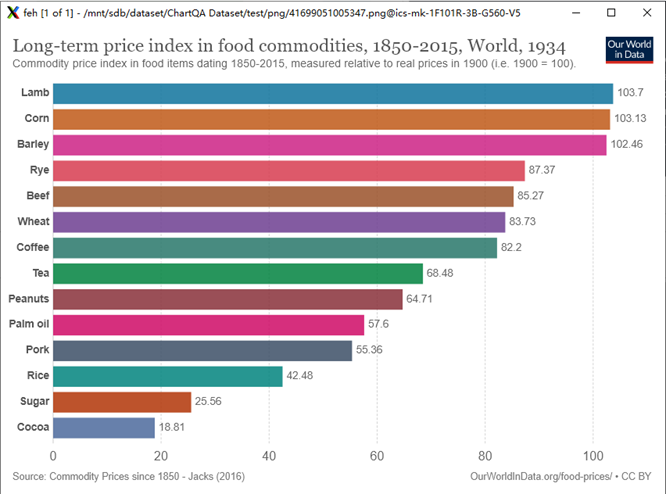
问题:How many food item is shown in the bar graph?
DocVQA
DocVQA 是一个关于文档图像信息提取的开放式问答数据集。该数据集需要对文档进行理解和推理才能正确回答。
CLEVER (Johnson et al., 2016)

Hateful Memes (Kiela et al., 2020)
受到其他 V&L 数据集缺点的启发:我们需要更难、更现实的东西,并且需要真正的多模态推理和理解。

八:有哪些超越图像的其它模态
Whisper: Radford et al., 2022
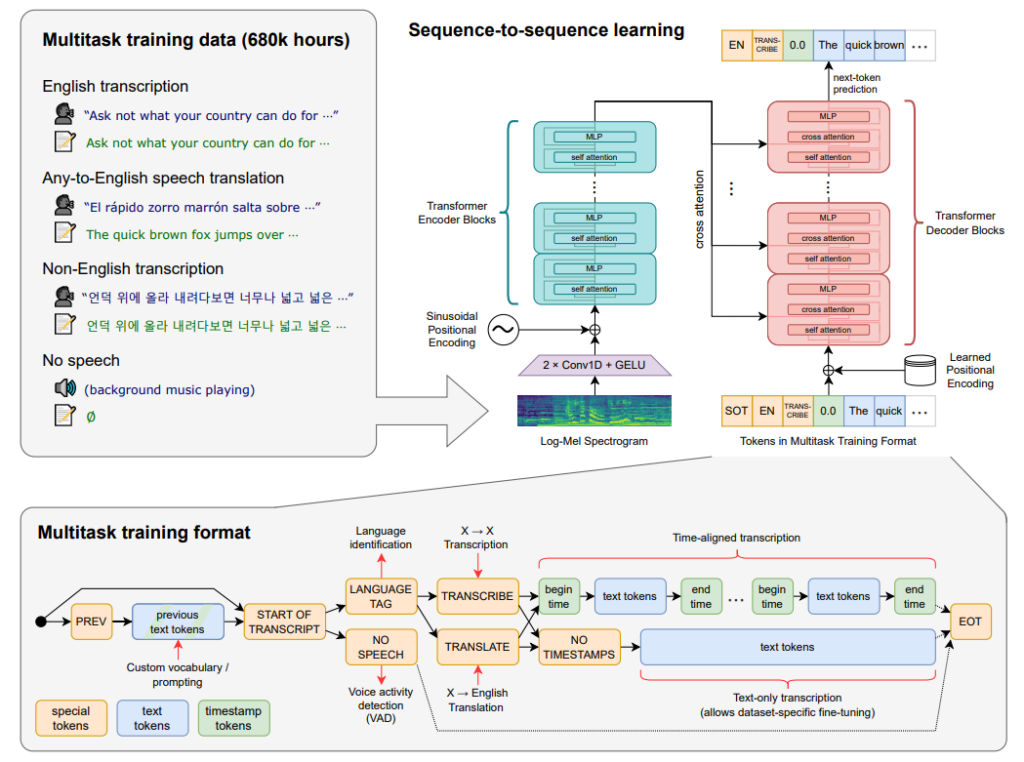
延展阅读:







