当金融领域需百万级标注数据、冷启动期识别率不足65%成为行业常态,智能客服部署陷入”数据饥渴”与”效果焦虑”的双重困局。通过TF-IDF筛选30%高价值对话、三阶段置信度响应机制,配合通用知识包与店铺模板的动态融合,企业可在3周内将准确率拉升至78%——本文揭晓从数据脱敏到熔断保护的全链路攻坚方案。
文章导航
一、智能客服机器人的核心挑战
当企业着手部署智能客服系统时,训练数据量级和冷启动阶段的准确率保障成为两大核心关注点。行业实践表明,一个基础版客服机器人通常需要10万级有效对话样本支撑,而在金融、医疗等专业领域,这个数字可能跃升至百万级别。如何在海量数据需求与有限初期资源间找到平衡点,同时确保系统上线初期的服务质量,直接决定了智能客服项目的实施效果。
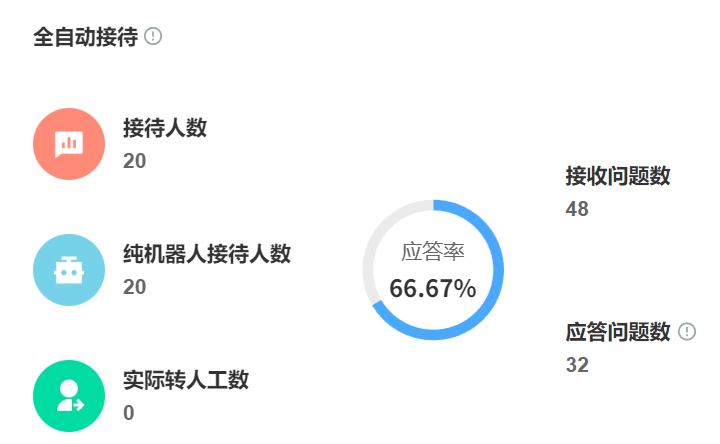

二、训练数据需求的核心影响因素
1. 业务复杂程度
标准商品零售场景通常需要5到10万条对话记录,覆盖80%的常见咨询类型;而专业技术服务领域则需20万+标注数据,特别需要包含行业术语、法规条款等专业内容。
2. 场景覆盖要求
全渠道客服系统需整合网页端(35%)、APP端(40%)和社交媒体(25%)的多维度对话特征,跨平台数据融合可提升15到20%的意图识别准确率。
3. 知识库完善度
建议采用「3层知识架构」:
基础问答库(占60%)
业务流逻辑库(30%)
应急处理预案(10%)
三、冷启动阶段准确率提升方案
1. 数据智能筛选机制
通过TF-IDF关键词提取+语义聚类分析,可从原始对话中筛选出价值密度最高的30%数据作为初训核心素材,使系统上线首周即可达到65到70%的基础识别率。
2. 混合应答模式设计
采用三阶段响应策略:
“`html
第一阶段:置信度>85% → 自动应答
第二阶段:60到85%置信度 → 人工确认后应答
第三阶段:<60%置信度 → 转接人工+自动学习 “`
3. 动态知识库优化
参考快手商家实践,通过「通用知识包+自定义话术库」的双层架构:
1. 开通官方通用知识库(覆盖60%标准场景)
2. 创建店铺专属问答模板
3. 加载行业特型知识包(如年货节专题)
四、数据安全与效果保障措施
1. 隐私保护技术方案
对话数据脱敏处理(实现率≥98%)
加密存储(AES到256标准)
访问权限三级管控
2. 服务稳定性保障
针对实时数据波动问题,采用:
数据平滑算法(消除30%异常波动)
异步更新机制(关键指标每15分钟持久化)
异常状态熔断保护
3. 效果验证体系
建立三维度评估矩阵:
1. 意图识别准确率(基准值≥78%)
2. 问题解决率(目标值>82%)
3. 对话转人工率(控制值<18%)
五、实施路径建议
阶段化部署方案:
1. 冷启动期(1到2周):聚焦高频问题处理
2. 优化期(3到4周):完善长尾问题覆盖
3. 成熟期(5周+):启动智能推荐功能
六、行业前沿发展方向
最新技术趋势显示,多模态数据融合正在改变训练范式:
文本对话数据(50%)
用户行为数据(30%)
语音/图像数据(20%)
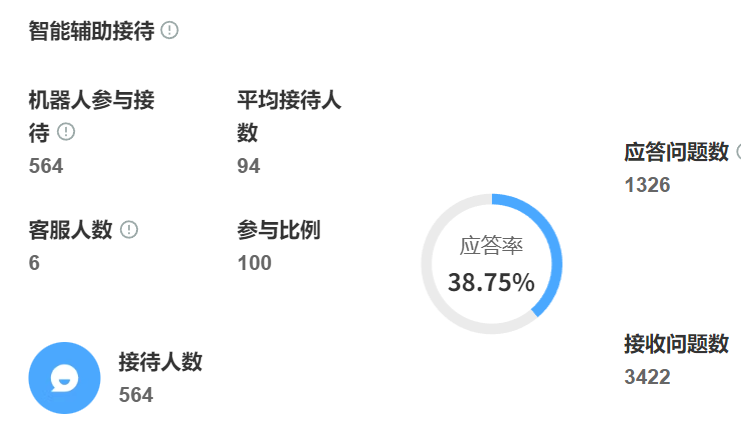
通过合理规划训练数据采集路径、建立动态优化机制,配合混合应答策略,企业完全可以在3到6个月内构建出准确率超85%的智能客服系统。建议商家参考快手智能客服的部署经验,从通用知识包起步,逐步叠加个性化配置,在保障服务质量的同时实现效率的阶梯式提升。
延展阅读:







