在当今人工智能技术飞速发展的时代,模型训练成本一直是一个备受关注的问题。DeepSeek V2的出现引起了广泛的关注,因为与DeepSeek 67B相比,它竟然节省了42.5%的训练成本。
这一成果对于推动人工智能技术的发展和普及具有重要意义。那么,DeepSeek V2是如何做到这一点的呢?这背后隐藏着哪些创新的技术和优化措施呢?本文将深入探讨DeepSeek V2节省训练成本的奥秘。
文章导航
一、KV缓存优化:MLA机制的关键作用
(一)显著减少KV缓存
DeepSeek V2的训练成本节省得益于MLA(Multi head Latent Attention)机制对KV缓存的高效压缩。与DeepSeek 67B相比,DeepSeek V2的KV缓存减少了93.3%。
这种大幅度的减少是非常惊人的。KV缓存是模型在运行过程中存储信息的重要部分,缓存的大小直接影响到内存的占用情况。
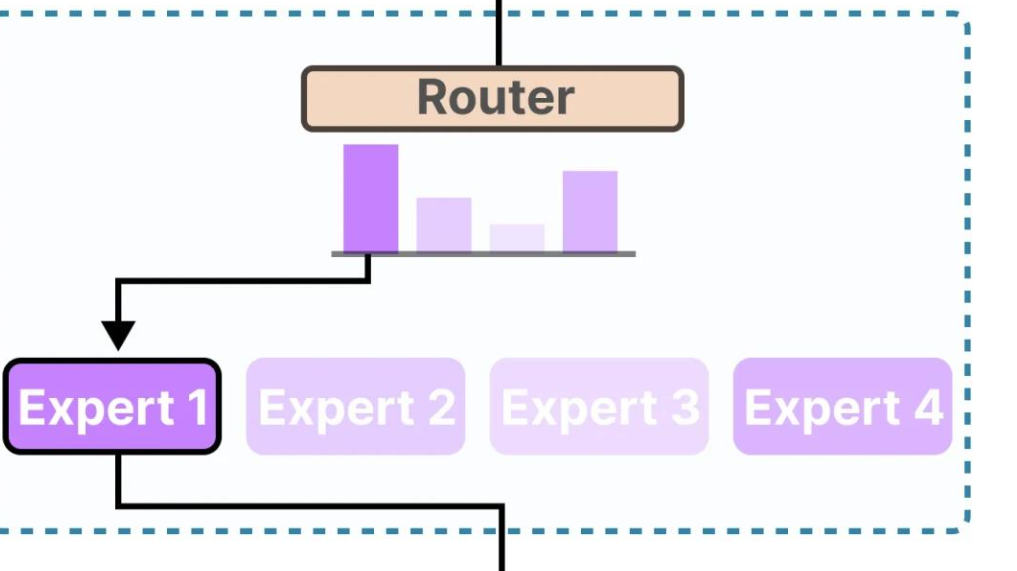

(二)提高推理效率与降低内存占用
KV缓存的优化不仅降低了模型的内存占用,还提高了推理效率。当模型在进行推理任务时,更小的KV缓存意味着可以更快地获取所需的信息,减少了数据读取和处理的时间。
这就好比在一个图书馆中,如果书籍的存放更加有序和紧凑(类比KV缓存的优化),那么读者(类比模型推理)就能够更快地找到自己需要的书籍,从而提高整个阅读(推理)的效率。同时,内存占用的降低也使得模型可以在相同的硬件资源下更加流畅地运行,减少了因内存不足而可能出现的卡顿等问题。
二、DeepSeek MoE架构对计算资源的高效利用
(一)DeepSeek MoE架构的核心策略
DeepSeek MoE(Mixture of Experts)架构对计算资源的高效利用也是DeepSeek V2节省训练成本的重要因素。其具体工作原理主要基于两个核心策略:细粒度专家细分和共享专家隔离。
通过这种方式,模型能够更加精准地分配计算资源,使得不同的任务可以由最适合的“专家”(模型中的特定部分)来处理。
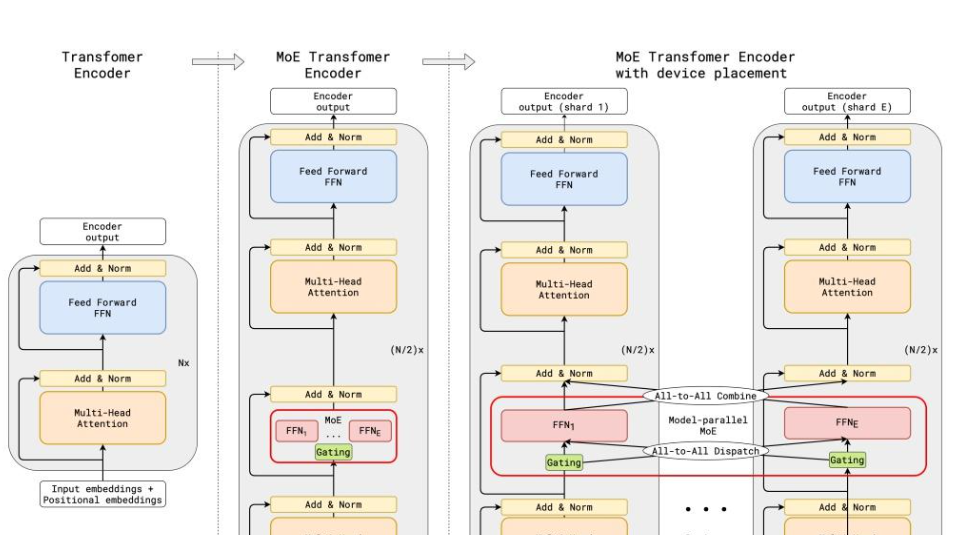
(二)提升性能的同时节省成本
这种架构在提升模型性能的同时,能够有效地降低训练成本。在模型训练过程中,计算资源的合理分配避免了不必要的资源浪费。例如,传统的模型可能会对所有任务采用相同的计算方式,导致在一些简单任务上浪费了过多的计算资源。
而DeepSeek MoE架构可以根据任务的特点,灵活地调用不同的专家模块,从而在保证性能的前提下,减少了总体的计算资源消耗,进而降低了训练成本。
三、DeepSeek V2在多领域的广泛应用前景
(一)多领域的应用现状
DeepSeek成立不久,但其产品和服务已广泛应用于智能客服、数据分析、智能推荐、自动化决策支持等多个领域。在这些领域中,DeepSeek V2的成本优势可以为企业带来更多的价值。
以智能客服为例,企业在部署智能客服系统时,需要考虑模型的训练成本和运行效率。DeepSeek V2较低的训练成本意味着企业可以以更低的投入获得一个高性能的智能客服模型,从而提高客户服务的质量和效率,增强企业的竞争力。
(二)推动行业发展
在整个行业中,DeepSeek V2的成本节省特性也有助于推动人工智能技术的更广泛应用。对于一些中小企业来说,高昂的模型训练成本可能是他们应用人工智能技术的一大障碍。而DeepSeek V2的出现,降低了这一技术门槛,使得更多的企业能够享受到人工智能带来的便利和优势,从而促进整个行业的发展和创新。
四、结论
DeepSeek V2通过MLA机制对KV缓存的优化以及DeepSeek MoE架构对计算资源的高效利用,成功地节省了42.5%的训练成本。这种成本的节省不仅使得模型自身在性能和效率上取得了很好的平衡,而且在多领域的应用中具有广泛的前景。随着人工智能技术的不断发展,相信DeepSeek V2这样的创新成果将为整个行业带来更多的机遇和变革。
延展阅读:
DeepSeek-V3开源后,开发者如何受益呢?其编程能力超越Claude了吗?







