在当今的人工智能领域,DeepSeek以其强大的性能吸引着众多用户的目光。然而,如何在本地高效地部署DeepSeek却是一个令不少人头疼的问题。幸运的是,LMDeploy这个专为大语言模型(LLMs)和视觉 语言模型(VLMs)设计的高效且友好的部署工具箱出现了。
它就像是一把神奇的钥匙,能够帮助我们轻松地打开本地部署DeepSeek的大门,让我们可以尽情地探索DeepSeek的无限潜力,无论是进行文本生成、图像识别还是其他复杂的任务。
文章导航
一、环境搭建

1. pip
pip是Python中非常重要的包管理工具。在使用LMDeploy进行DeepSeek本地部署时,我们需要确保pip已经正确安装并且是最新版本。通过pip,我们可以方便地安装各种依赖库,这些库是运行DeepSeek模型所必需的。例如,一些用于数据处理、模型优化的库等。
2. git
git则是用于版本控制的工具。在获取DeepSeek相关的代码和模型文件时,git起到了关键的作用。我们可以通过git克隆DeepSeek的代码仓库,确保我们获取到的是最新、最稳定的版本。同时,git也方便我们在后续的开发和部署过程中对代码进行管理,比如进行代码的更新、回滚等操作。
二、模型准备
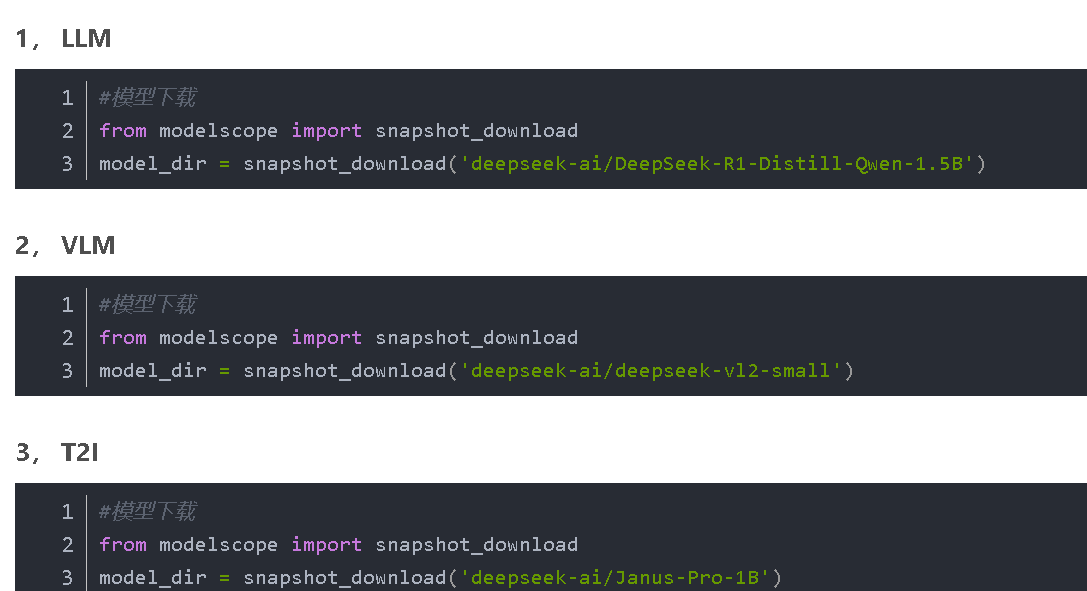
1. 下载模型地址
(1)huggingface
Huggingface是一个非常知名的人工智能模型共享平台。在这个平台上,我们可以找到各种版本的DeepSeek模型。它提供了丰富的资源和便捷的下载方式。我们只需要在Huggingface的官方网站上搜索DeepSeek,就可以找到我们需要的模型文件,然后按照提示进行下载即可。
(2)魔塔社区
魔塔社区也是获取DeepSeek模型的一个重要途径。这里可能会有一些经过特殊优化或者定制的DeepSeek模型版本。在魔塔社区中,我们可以与其他的开发者和用户进行交流,获取关于模型的更多信息,比如模型的性能特点、适用场景等,从而选择最适合自己需求的模型版本进行下载。
2. 模型选择
(1)LLM(文本生成)
如果我们的主要需求是进行文本生成任务,例如撰写文章、回答问题等,那么选择DeepSeek的LLM版本是一个不错的选择。这个版本的模型经过专门的训练,在处理文本相关的任务时具有很高的准确性和效率。
(2)VLM(图像识别)
对于图像识别任务,VLM版本的DeepSeek则更为合适。它能够识别图像中的各种元素、物体,甚至可以对图像的内容进行描述。无论是用于图像分类、目标检测还是图像内容的理解,VLM版本都能发挥重要的作用。
(3)T2I(文生图)
T2I版本的DeepSeek允许我们通过输入文字描述来生成相应的图像。这是一种非常有趣且具有创造性的功能。例如,我们可以输入“美丽的海边日落”这样的文字,模型就可以根据这个描述生成一幅相应的图像。
3. 下载模型
根据我们的需求选择好相应的模型(LLM、VLM或者T2I)之后,就可以开始下载模型了。在下载过程中,要确保网络的稳定,以免出现下载中断的情况。同时,根据模型的大小,下载可能需要一定的时间,需要耐心等待。
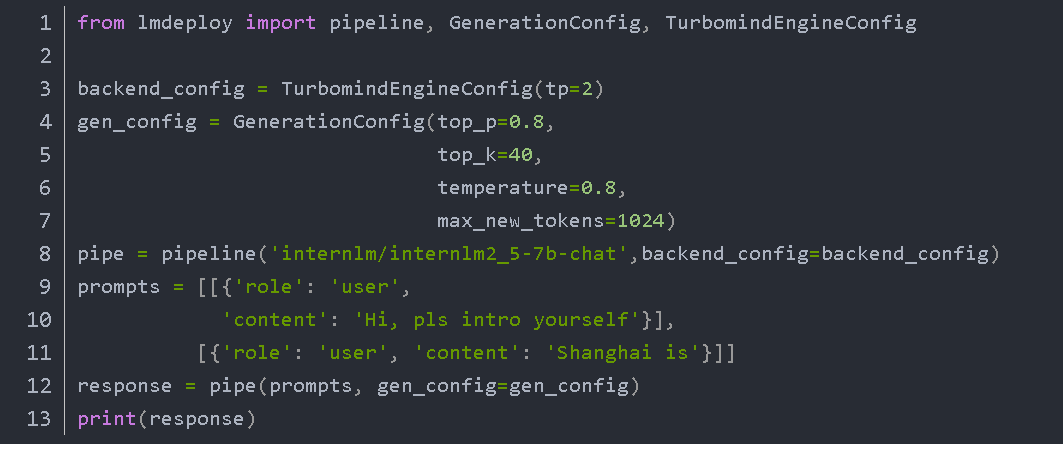
三、推理
1. 代码与输入
在推理阶段,我们需要编写相应的代码来调用已经下载和准备好的DeepSeek模型。对于文本输入,我们要将正确的文本格式传递给模型。例如,如果是一个问答任务,要将问题按照模型要求的格式进行组织。对于视觉相关的任务,要正确处理图像数据的输入格式。
2. 输出
模型经过推理之后会产生输出结果。对于文本任务,输出可能是一段文字答案;对于图像识别任务,输出可能是识别出的物体名称或者对图像内容的描述;对于文生图任务,输出就是根据输入文字生成的图像。我们需要对这些输出结果进行合理的处理和解读。
四、大语言模型(LLMs)部署
在这一阶段,我们要将LLMs版本的DeepSeek模型部署到本地环境中。这涉及到一些配置文件的设置、参数的调整等工作。确保模型能够在本地环境中稳定运行,并且能够充分利用本地的计算资源,如CPU、GPU等。
五、视觉语言模型(VLMs)部署
VLMs版本的部署与LLMs有一些不同之处。在部署VLMs时,需要考虑到图像数据的处理和存储。例如,要确保本地环境有足够的空间来存储图像数据,并且要对图像数据的读取和处理进行优化,以提高模型的运行效率。
六、LoRA推理服务
LoRA(Low Rank Adaptation)是一种用于优化模型推理的技术。在使用LMDeploy部署DeepSeek时,可以利用LoRA推理服务来提高模型的推理速度和准确性。通过对模型进行低秩分解和调整,可以在不显著增加计算资源消耗的情况下,提升模型的性能。
七、量化
1. INT4
INT4量化是一种将模型参数表示为4位整数的量化方式。这种量化方式可以大大减少模型的存储空间,同时在一定程度上提高模型的推理速度。但是,INT4量化可能会对模型的准确性产生一定的影响,需要在速度和准确性之间进行权衡。
2. INT8
INT8量化则是将模型参数表示为8位整数。相比于INT4,INT8在准确性上可能会更高一些,但存储空间的节省程度相对较小。在实际应用中,可以根据具体的需求选择INT4或者INT8量化方式。
3. KV Cache
KV Cache(Key Value Cache)是一种用于加速模型推理的缓存机制。在量化过程中,合理利用KV Cache可以进一步提高模型的推理效率。它可以缓存已经计算过的键值对,避免重复计算,从而节省计算时间。
八、测试对比
在完成本地部署之后,我们需要对部署的DeepSeek模型进行测试对比。可以将其与其他类似的模型或者在线版本的DeepSeek进行对比。
测试的内容包括模型的准确性、推理速度、资源消耗等方面。通过测试对比,我们可以了解到本地部署的DeepSeek模型的性能优势和不足之处,从而进行进一步的优化。
九、总结
通过LMDeploy进行DeepSeek的本地部署,我们可以从环境搭建、模型准备、推理、部署、量化等多个方面进行全面的操作。
虽然整个过程可能会涉及到一些复杂的技术环节,但是只要按照步骤进行,就能够轻松地玩转DeepSeek。这不仅让我们能够更好地利用DeepSeek的强大功能,还可以根据自己的需求进行定制化的开发和应用,为我们在人工智能领域的探索和创新提供了更多的可能性。
延展阅读:
deepseek服务器繁忙,API无法充值,如何使用其他渠道玩转deepseek







