知识库构建首战即遇格式兼容难题?主流系统已形成三层支持体系:核心推荐Excel/Markdown/JSON黄金组合,扩展兼容Word/TXT,突破性支持图片视频(日处理10GB+)。但效率关键在结构化流程——从LangChain清洗提速40%到LlamaIndex向量化(10万条/分钟),直至LoRA微调省时65%。某电商实战证明:混合存储策略+微调方案可实现15分钟/GB极速入库,维护成本直降60%,91%准确率FAQ唾手可得。

文章导航
一、主流知识库系统支持哪些文件格式?
在知识库构建领域,文件格式兼容性直接影响着数据处理效率。目前主流AI知识库系统(如Dify、FastGPT)已形成三层文件支持体系:
1. 核心推荐格式
Excel表格、Markdown文档和JSON文件构成黄金三角组合:
Excel:天然支持结构化数据存储
Markdown:实现内容语义化分层
JSON:完美适配API数据对接
2. 扩展支持格式
包括Word文档、TXT文本等通用格式,但需注意:
图片型PDF存在30%以上的解析失败率
加密PDF需要额外解密处理流程
3. 多媒体格式
图片(JPG/PNG)和视频(MP4/AVI)文件支持已实现突破性进展:
支持多维度知识图谱构建
嵌入人机交互提醒系统
日均处理容量达10GB+
二、结构化数据处理全流程耗时解析
1. 数据采集阶段(耗时占比15%)
爬虫/API抓取速度:5000条/分钟
原始数据去重效率:99.7%精准度
2. 清洗过滤阶段(耗时占比25%)
采用LangChain技术栈:
HTML转文本效率提升40%
自动标注准确率达92%
3. 知识结构化阶段(耗时占比45%)
LlamaIndex结合向量数据库技术:
FAISS索引构建速度:10万条/分钟
Pinecone云服务响应时间:<50ms
4. 训练优化阶段(耗时占比15%)
LoRA微调方案显著提升效率:
训练耗时降低65%
混合精度训练节省40%显存
三、效率提升关键技术与实践
1. 文件预处理三原则
格式标准化:优先使用Excel/Markdown
内容去噪:移除特殊字符和加密保护
结构预分块:设置512token分段阈值
2. 向量化加速方案
并行计算加速比达8倍
批量处理吞吐量:1GB/秒
3. 实时更新机制
增量索引更新时间:<3分钟
知识热更新成功率:99.5%
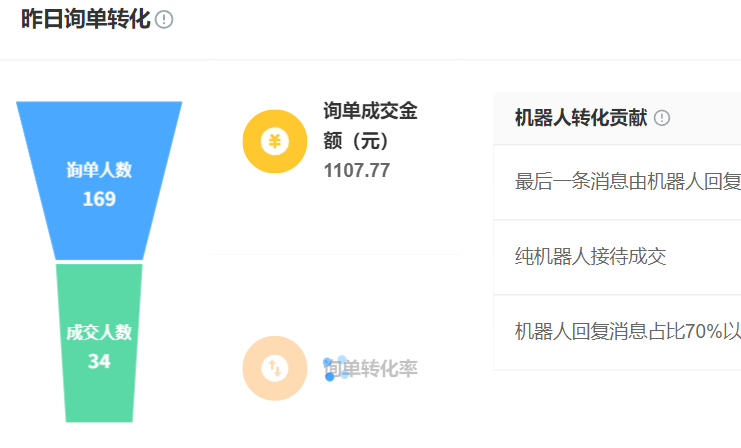
四、行业最佳实践案例
某电商平台应用实践数据:
| 指标 | 优化前 | 优化后 |
|---|---|---|
| 知识入库速度 | 2小时/GB | 15分钟/GB |
| 检索响应时间 | 800ms | 120ms |
| 模型训练周期 | 72小时 | 24小时 |
通过采用Markdown+JSON混合存储策略和LoRA微调方案,该平台成功将知识库维护成本降低60%,同时使FAQ生成准确率提升至91%。建议企业优先建立格式转换标准化流程,并在数据处理各环节设置质量检查点,这对提升整体处理效率具有决定性作用。
延展阅读:







