在人工智能蓬勃发展的今天,大语言模型的训练成本一直是个备受关注的问题。高昂的成本如同一只无形的大手,限制了许多企业和研究机构在这一领域的深入探索。然而,DeepSeek-R1的出现犹如一道曙光,它在保持高性能的同时,训练成本却大幅降低。
在MATH基准测试中,它以77.5%的准确率与OpenAI-o1模型相媲美,但训练成本仅为其三分之一。这一现象不禁让我们好奇,DeepSeek-R1低成本训练的根本原因到底是什么呢?
文章导航
一、算法与训练流程创新
1.纯强化学习训练路径
DeepSeek-R1在训练策略上做出了大胆的创新,摒弃了传统大模型训练中先监督学习微调(SFT)再强化学习(RL)的策略,而是完全采用纯强化学习训练路径。这一举措具有重要意义,因为传统的先监督学习微调往往需要大量的标注数据。
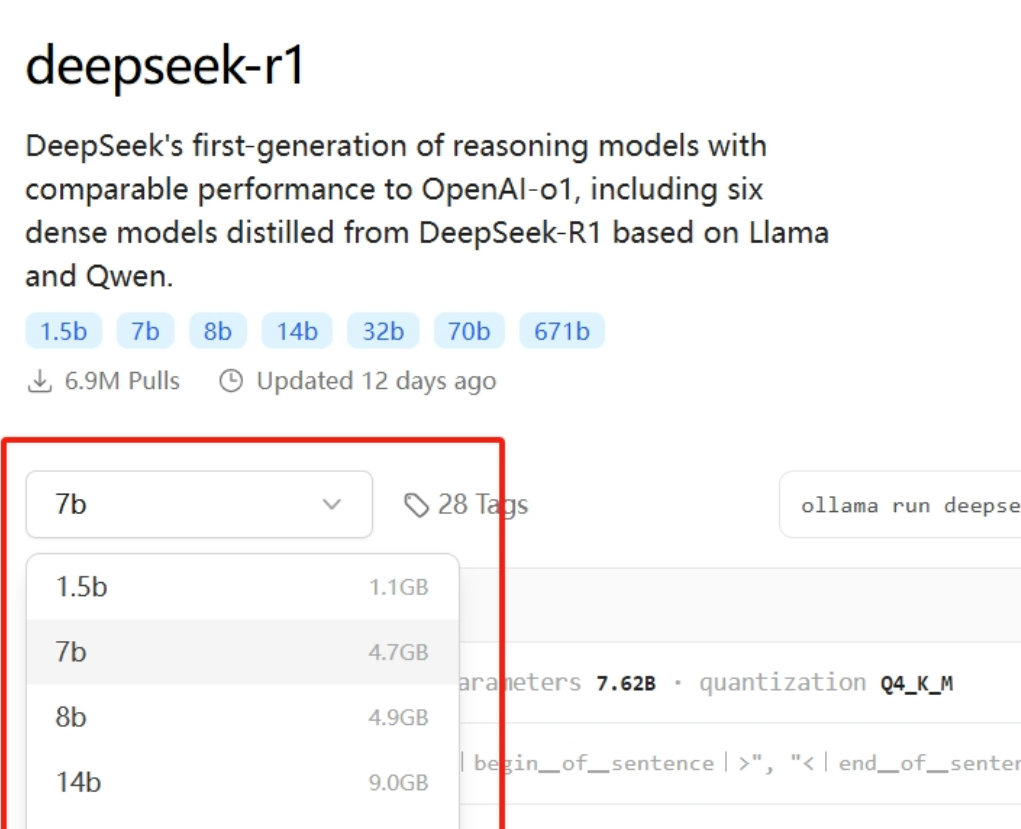

收集、整理和标注这些数据不仅耗时费力,还需要投入大量的人力和物力资源。而DeepSeek-R1的纯强化学习训练路径则减少了对大量标注数据的依赖,从而有效地降低了数据成本。
例如,在模型构建过程中,数据的获取和处理是成本的重要组成部分。如果需要人工对海量数据进行标注,这将是一笔不小的开支。而DeepSeek-R1通过纯强化学习,能够在不需要过多标注数据的情况下进行训练,这就像是在建造大厦时,找到了一种更高效、更节省材料的建筑方法。
2.减少监督微调(SFT)步骤
DeepSeek团队采用了一种独特的训练方案,通过减少监督微调(SFT)步骤来降低训练成本。他们甚至尝试完全跳过SFT,推出了名为DeepSeek-R1-Zero的版本,仅依赖其他的训练方式。
虽然在这个过程中出现了一些缺陷,并导致团队在构建模型的最后阶段重新引入了有限数量的SFT,但结果证实了根本性的突破:减少SFT步骤确实能够带来成本的显著降低。这是因为SFT步骤本身也需要一定的计算资源和数据资源,减少这一步骤,就像是在生产流程中简化了一道工序,从而降低了整体的生产成本。
二、技术突破绕开CUDA
DeepSeek-R1成本低的原因还可以从其绕开CUDA的技术突破来看。在硬件和软件层面,CUDA是许多大模型训练时常用的计算平台,但它也带来了一定的成本。DeepSeek R1通过独特的技术手段绕开了CUDA,这一突破显著降低了硬件和软件层面的成本。
在硬件方面,绕开CUDA可能意味着可以采用更具性价比的硬件设备或者架构。例如,不需要专门为CUDA进行优化的高端显卡等硬件,从而降低了硬件采购成本。
在软件方面,不再依赖CUDA相关的软件框架和工具,也减少了软件授权费用以及相关的开发和维护成本。这就好比是在交通出行中,找到了一条新的、不收费的道路,从而节省了通行费用。
三、模型架构的精心设计
DeepSeek-R1的成功也离不开其精心设计的模型架构。一个合理的模型架构能够在保证性能的前提下,提高计算效率,从而降低训练成本。虽然目前关于DeepSeek-R1具体的模型架构细节并没有完全公开,但从其表现来看,其架构必然有着独特之处。
例如,通过合理的分层结构、神经元连接方式等设计,可以让模型在训练过程中更有效地利用计算资源。就像一个精心设计的机械装置,每个零件的位置和连接方式都恰到好处,能够以最小的能量消耗实现最大的功能输出。这种精心设计的模型架构使得DeepSeek R1在训练过程中不需要过多的计算资源,进而降低了成本。
综上所述,DeepSeek R1低成本训练的根本原因是多方面的,包括算法与训练流程的创新、绕开CUDA的技术突破以及精心设计的模型架构等。这些因素共同作用,使得DeepSeek R1在大语言模型领域展现出了“低成本、高性能”的强大竞争力,也为未来大语言模型的开发提供了新的思路和借鉴。
延展阅读:







