embedding-model是将自然语言转换成稠密向量的模型。我们日常使用的embedding-model大多是基于Bert进行数据微调得到的。但是是否只有bert这种auto-encoder结构的模型才能做embedding-model,是否有基于auto-regress或者encoder-deconder结构的embedding-model。
文章导航
总结
1、现有的EmbeddingModel主流是基于Bert-Style的小模型。
2、目前的主流训练策略是使用大规模弱监督数据训练进行预训练,然后使用小规模高质量数据针对任务进行微调。
3、但是也出现了对于LLM微调的尝试,目前效果没有超过主流结构。
Fine-tunning 方法
Text2vec模型实验报告
text2vec(https://github.com/shibing624/text2vec) 是我们目前recall阶段使用的模型的,其中实现了几个常见的向量化模型:SBERT(Sentence-Bert), CoSENT(Cosine Sentence), BGE (BAAI general embedding)。其中SBERT 和CoSENT都是基于预训练模型进行微调的方法。
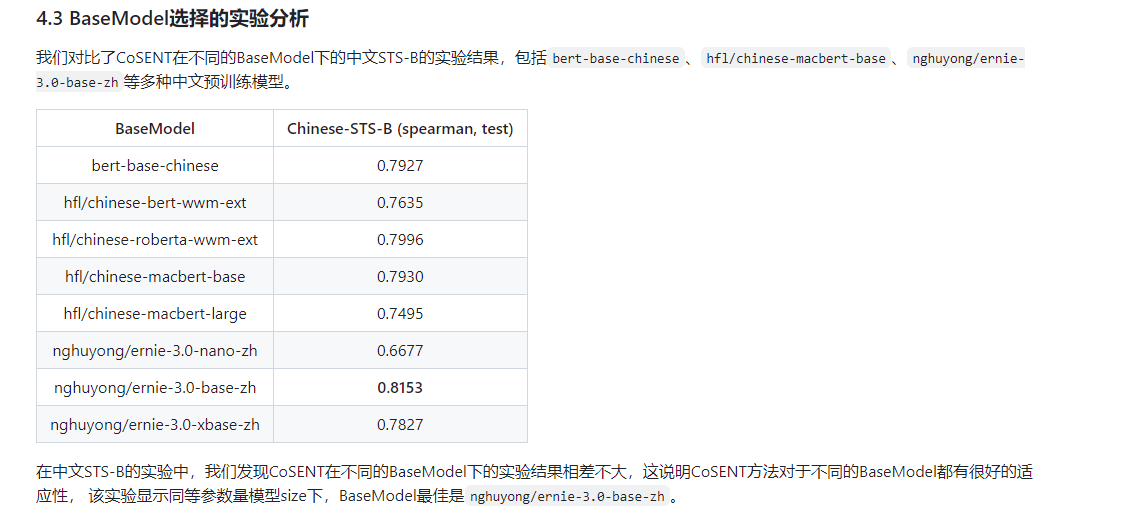

其中 bert, roberta, macbert是auto-encoding结构的模型,
ERNIE(ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation https://arxiv.org/pdf/2107.02137.pdf 百度,2021年, Transformer-xl结构) 是一种混合了auto-regressive network 和 auto-encoding netwoker的大模型,他认为单纯的使用auto-regressive方式进行训练,没有融入知识是大模型(T5, GPT-3)在下游工作中进行针对任务的微调但是表现不佳的原因。(Bart的升级?)
结论:可以看出经过微调后模型ernie的效果更好,但是这个结构可能是因为模型参数量带来的。主流还是Bert这种auto-encoding模型。
Pre-training模型
Auto-encoder 模型:
主流的embedding模型,例如Contriever, OpenAI Embeddings, E5, BGE等方法采用多阶段训练策略。
- 大规模无监督文本进行预训练。
- 小规模高质量有监督数据集进行微调。
GTE(阿里达摩院 2308)训练过程
- 训练的Loss是流行的infoNCE loss。
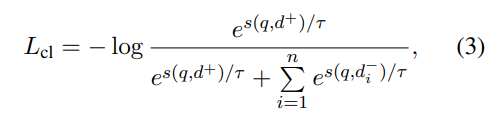
- 预训练阶段选取多元数据进行组合形成数据,共计800MB,利用数据之间的内在关系训练构建正负样本对。比如在问答平台中的问题和答案。
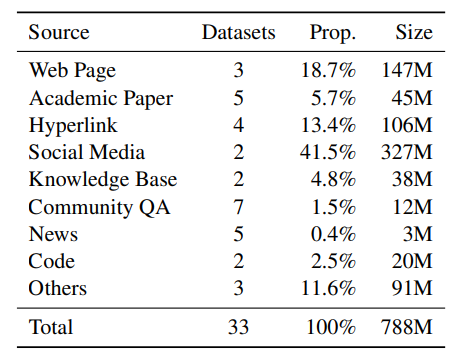
- 使用经过人工标注的小规模高质量数据共计(3百万个三元组)
LLM
初步探索但效果不佳:RepLLaMA, SGPT,GTR, Udever
E5-mistral-7b-instruct: 使用llm合成训练数据,微调mistral模型。
https://arxiv.org/pdf/2401.00368.pdf
- Llm 生成任务

- Llm 生成任务对应的数据

- 训练:
1)输入:{task_definition}是任务名称
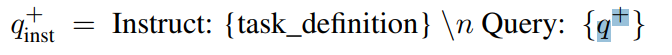
2)取[EOS]位置的向量作为Embedding
3)Loss function:简单的对比学习Loss
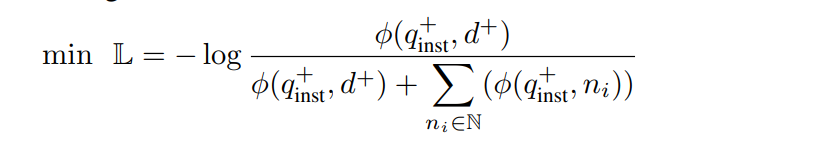
MTEB(Massive Text Embedding Benchmark)中文榜单
https://huggingface.co/spaces/mteb/leaderboard
huggingface.co
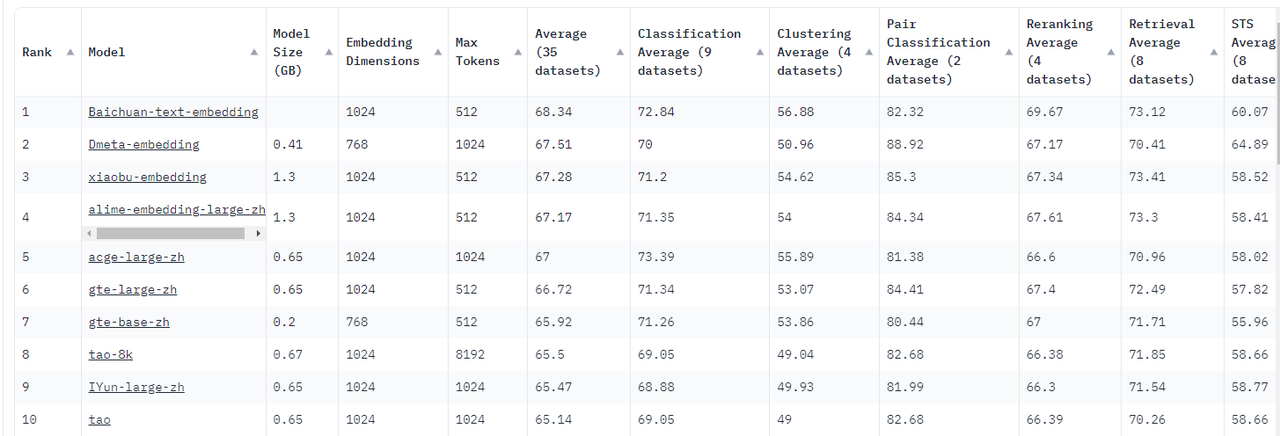
| rank | model | ModelSize(GB) | structure |
| 1 | Baichuan-text-embedding | ||
| 2 | Dmeta-embedding | 0.41 | encoder |
| 3 | xiaobu-embedding | 1.3 | encoder(GTE微调) |
| 4 | alime-embedding-large-zh | 1.3 | bert |
| 5 | acge-large-zh | 0.65 | bert |
| 6 | get-large-zh | 0.65 | bert |
| 7 | get-base-zh | 0.2 | bert |
| 8 | tao-8k | 0.67 | bert |
| 9 | IYun-large-zh | 0.65 | bert |
| 10 | tao | 0.65 | bert |
推荐阅读:







