对智能问答系统来说,文本相似度技术的核心目标是通过衡量用户问题与已存在问题或答案的相似性,自动或辅助提供准确、快速的回应。对于电商智能客服接待流程来说,这种技术极大地减少了重复回答常见问题的时间,也有效保障了用户满意度。
文章导航
一、智能客服机器人应用文本相似度的场景
当客户在电商网站或平台上提出问题时,比如“如何退货?”,智能客服系统可以通过文本相似度技术,查找数据库中是否有类似的问题已经被回答过。这相当于让系统去“回忆”以前的记录,从而快速为用户提供正确的答案,比如“您可以通过订单页面中的退货按钮申请退货”。
二、应用文本相似度技术的方法和好处
相似问题检索与匹配
- 相似问题的自动匹配:当客户提出问题时,智能客服系统可以通过计算新问题与数据库中已有问题的相似度,自动返回相似的问题和答案。这能够大大减少客服人员的工作量,并加快响应速度。
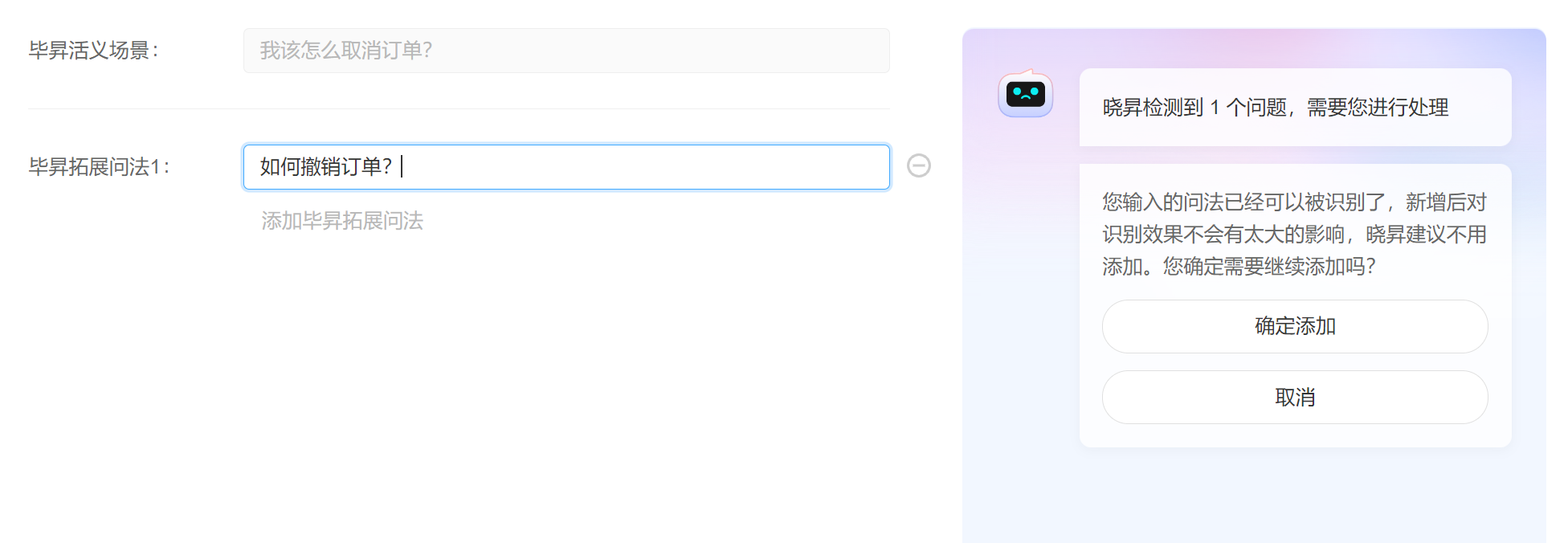
- 实例解释: 比如,客户问:“我该怎么取消订单?” 系统可以快速检索出类似的问题,如“如何撤销订单?”并返回相关的答案。即使问题的表达不完全相同,系统仍能通过语义相似性找到合适的答案。

自动回答生成
- 基于相似度的自动回答:系统可以根据客户问题的相似度,直接从已有的答案中生成最符合的回答。这在处理一些常见问题(如退货流程、配送问题、账户管理等)时特别有效。
- 实例解释: 客户问:“这件商品可以换货吗?” 系统可以通过相似度计算找到与换货相关的常见问题,并自动生成回答:“如果商品符合换货条件,您可以在订单详情页申请换货。”
个性化推荐
- 基于用户问题的个性化推荐:通过分析用户提出的问题,系统可以推测用户的需求,并推荐相似的产品或服务。例如,当用户在询问关于产品的具体功能时,系统可以自动推荐其他相似或相关的产品。
- 实例解释: 客户问:“这款手机支持无线充电吗?” 除了回答问题,系统还可以推荐其他同样支持无线充电的手机型号,帮助客户做出更好的购买决策。
混合式问答系统
- 人工与自动化的结合:虽然自动化客服可以处理大量常见问题,但在一些复杂场景中,系统可以通过文本相似度技术将未能匹配的问题转交给人工客服处理,从而实现自动化与人工的无缝衔接。
- 实例解释: 如果客户提出较为复杂的问题,例如“如果我购买的商品送到后出现质量问题,如何申请退货并获得赔偿?” 系统可能无法完全理解并生成适合的回答。这时,它会将问题标记为“需要人工处理”,并将客户的问题和可能的相关问题推送给客服人员,帮助他们更快找到答案。
文本相似度技术使得客服系统能够快速、准确地响应用户问题,这不仅节省了客户等待的时间,还提升了整体用户体验,增强了客户的满意度。
三、文本相似度技术应用中的挑战与解决方案
语义理解的多样性
用户可能用不同的表达方式提出相同的问题,而智能客服系统必须具备处理语言多样性的能力。为了解决这一问题,基于深度学习的文本相似度模型如BERT、RoBERTa等可以捕捉更深层次的语义信息。
- 实例解释: 客户问“我想要退货”与“我能不能把这个商品寄回来?”在语义上相似,但用词和句法不同。传统的方法可能会错过这种相似性,而现代基于深度学习的相似度计算可以更好地理解这些问题背后的相同含义。
数据稀疏性
在某些特定领域,数据库中的问题样本可能不足,导致系统在匹配时精度降低。解决方案可以通过预训练模型微调或迁移学习,将通用领域的知识迁移到特定领域。
- 实例解释: 某些新产品或少见问题的数据可能较少,但通过将现有模型与领域知识相结合,系统可以更好地处理这些问题,避免“回答不上来”的情况。
四、文本相似度应用在客服问答中的实例代码
可以使用Python和Hugging Face的Transformers库,结合预训练模型如BERT,进行相似度计算。
- 代码片段:
from transformers import BertTokenizer, BertModel
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 计算文本的BERT向量
def get_embedding(text):
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=128)
outputs = model(**inputs)
return outputs.last_hidden_state.mean(dim=1)
text1 = "如何取消订单?"
text2 = "怎么撤销订单?"
embedding1 = get_embedding(text1)
embedding2 = get_embedding(text2)
# 计算两个文本的余弦相似度
cos_sim = torch.nn.functional.cosine_similarity(embedding1, embedding2)
print(f"相似度: {cos_sim.item()}")
总结
文本相似度技术在客服问答系统中的应用不仅提高了自动化服务的效率,还提升了客户的购物体验。通过相似问题检索、自动回答生成、个性化推荐等功能,电商商家能够为用户提供更加精准的服务。同时,结合语义理解的深度模型和人工客服的混合策略,可以实现更高效的客服运营。
延展阅读:







