文章导航
一、背景
文本嵌入(embedding)现在是一门比较火爆的技术。在nlp的领域中,将文本embedding成向量后,通过向量的相似度检索能够比较高效的实现文本相似度匹配或者语义识别。
其中实现向量相似度检索的高效组件就是向量数据库。目前市面上有很多不同种类的向量数据库实现,比如:pgvector、redis、qdrant等等。本文记录了qdrant的一些初步探索过程和其性能上的障碍。
二、测试遇到的几个问题现象
- qps超过一个瓶颈点几乎绝大部分请求响应超时,cpu使用率、负载、网络流量非常低。
- 副本数replication_factor从1设置成2大部分请求响应超时。
三、排障过程
(一)压测CPU始终上不去
集群模式:2台8c16g 2节点cluster,qdrant版本:v1.7.3
- 排查docker容器无cpu限制
- 尝试调整max_search_threads参数无效
https://qdrant.tech/documentation/guides/configuration/#configuration-file-example


- 升级版本到v1.9.4,尝试调整optimizer_cpu_budget参数,无效
https://qdrant.tech/articles/qdrant-1.8.x
- 尝试通过环境变量设置QDRANT_NUM_CPUS参数,无效
- 调整default_segment_number参数为2(之前为默认值0),终于cpu使用率提升、qps吞吐增加!
https://qdrant.tech/documentation/guides/optimize/#latency-vs-throughput
qdrant默认为每个请求做最快的响应,server端退化成了串行处理。猜测可能是遇到耗时稍久一点的查询,导致后续后多请求排队超时【猜测超时未取消排队?】排队越堵越多,导致业务响应不可用。
(二)增加副本qps吞吐下降一半
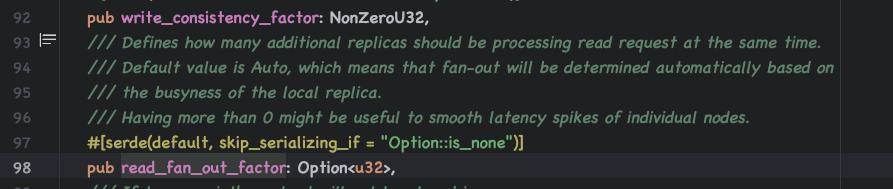

计算资源被重复使用,一个请求挤占了双份的计算资源,所以qps下降一半。
不能调整read_fan_out_factor成只用一个副本计算。
(三)几个核心参数
- max_search_threads: 最大搜索线程数【全局参数】。

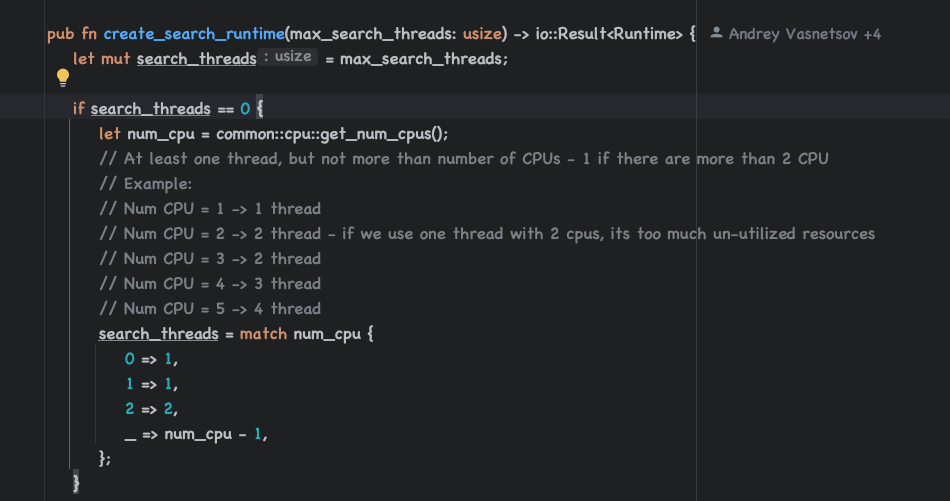
- default_segment_number:
collection创建时指定
https://qdrant.tech/documentation/guides/optimize/#latency-vs-throughput

影响qps的关键参数,默认和cpu核数一致。如果业务需要高qps吞吐,强烈建议不要使用默认值!可以设置成2。
- replication_factor、 read_fan_out_factor。
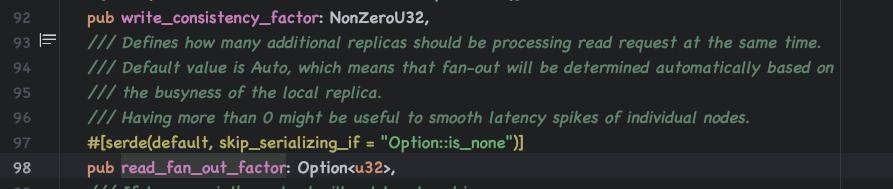

感觉qdrant为单个响应更快做了更多的考虑,对于需要高qps吞吐的业务,谨慎设置副本。【副本又是高可用的前提】
- slb
qdrant集群模式,读写发生在任意节点均可,集群内部做同步。如果使用cluster模式,建议做一层slb,业务指向slb地址,可以有效的做到入口均衡。
延展阅读:
Mongo性能优化实战:如何通过WiredTiger引擎提升MongoDB的性能和数据安全性
CAP理论与Raft协议如何在分布式系统中确保一致性和可用性?







