在自然语言处理(NLP)领域,文本相似度的计算是一个重要的研究课题。本文将介绍几种传统的文本相似度计算方法,包括基于词频的方法、基于编辑距离的方法以及基于向量空间模型的方法。并且,我们还将探讨基于词嵌入的方法及其在实际应用中的优势。
文章导航
一、基于词频的方法
1、词频(TF)
词频(Term Frequency,简称TF)是指某个词在一篇文档中出现的次数。这个概念背后的逻辑是,一个词在一篇文档中出现得越多,这个词对于这篇文档的重要性就越高。词频的计算很简单,就是统计一个词在文档中出现的次数。
- 示例:假设我们在做电商客服的自动回复系统,经常会收到用户的问题。比如,一个用户可能会问:“这款手机的电池续航时间如何?” 如果很多用户都问类似的问题,那么在这些问题中,“手机”和“电池”这两个词会频繁出现,因此它们的词频会很高。这表明用户对“手机”和“电池”这两个方面特别关心。
2、逆文档频率(IDF)
逆文档频率(Inverse Document Frequency,简称IDF)用于衡量一个词在所有文档中出现的稀有程度。它的计算公式是:IDF = log(总文档数 / 包含该词的文档数)。词越稀有,IDF值越高。这是因为稀有的词对区分文档的重要性更高。
- 示例:继续上面的电商客服系统的例子。在所有用户的问题中,“手机”和“电池”可能会在很多问题中出现,这两个词并不稀有,因此它们的IDF值较低。相比之下,“续航”这个词在用户问题中相对少见,所以它的IDF值较高。这意味着,“续航”这个词对于区分用户问题的重要性更高。
3、TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency)是词频和逆文档频率的组合,用于衡量一个词在特定文档中的重要性。TF-IDF的计算公式是:TF-IDF = TF * IDF。通过将词频和逆文档频率结合起来,我们可以更准确地衡量一个词在文档中的重要性。词频高但在其他文档中少见的词会有较高的TF-IDF值。
示例:在电商客服系统中,假设我们有两个用户问题:“这款手机的电池续航时间如何?”和“这款手机有几个摄像头?”。在第一个问题中,“手机”、“电池”、“续航”都是高频词,但“续航”在所有文档中相对少见,因此它的IDF值较高。通过计算TF-IDF,我们可以确定“续航”是这个问题的关键词,从而更好地匹配相关的答案。例如,如果有另一用户问“这款手机的续航表现怎么样?”,系统可以根据“续航”这个关键词,匹配到第一个用户问题的答案。
二、基于编辑距离的方法
在自然语言处理中,编辑距离是一种常用的方法,用来衡量两个字符串之间的相似性。
1、Levenshtein距离
Levenshtein距离衡量的是将一个字符串转换为另一个字符串所需的最少编辑操作(插入、删除、替换)的数量。
示例:
假设用户提出了两个问题:
- “这款手机的电池续航时间怎么样?”
- “这款手机电池续航如何?”
如果我们想把第一个问题转换为第二个问题,可以通过以下操作实现:
- 删除“的”
- 删除“时间”
- 替换“怎么样”成“如何”
总共需要进行3次操作,因此这两个问题的Levenshtein距离是3。距离小,说明两个问题很相似,我们可以认为这是相似的问题。
2、Jaccard相似系数
Jaccard相似系数衡量的是两个集合的交集和并集的比值。
示例:
我们再来看两个用户问题:
- “这款手机的电池续航时间怎么样?”
- “这款手机电池续航如何?”
我们可以将每个问题拆分成一组词:
- 问题1的词集:{“这款”, “手机”, “的”, “电池”, “续航”, “时间”, “怎么样”}
- 问题2的词集:{“这款”, “手机”, “电池”, “续航”, “如何”}
交集(相同的词):{“这款”, “手机”, “电池”, “续航”},共有4个词。 并集(所有不同的词):{“这款”, “手机”, “的”, “电池”, “续航”, “时间”, “怎么样”, “如何”},共有8个词。
Jaccard相似系数 = 交集的大小 / 并集的大小 = 4 / 8 = 0.5
因此,Jaccard相似系数为0.5,说明两个问题有一半的词是相同的,相似度较高。
3、余弦相似度
余弦相似度通过计算两个向量的夹角余弦值来衡量相似度,向量越接近,余弦值越接近1。
示例:
假设我们将用户问题转化为向量。比如:
- “这款手机的电池续航时间怎么样?” -> [1, 1, 1, 1, 1, 1, 1]
- “这款手机电池续航如何?” -> [1, 1, 0, 1, 1, 0, 1]
向量中的每个位置对应一个词,1表示词出现,0表示词未出现。为了简单起见,这里假设所有词都已对齐。
计算两个向量的余弦相似度:
余弦相似度 = 向量点积 / (向量1的模长 * 向量2的模长)
点积 = 11 + 11 + 10 + 11 + 11 + 10 + 1*1 = 5 模长1 = sqrt(1^7) = sqrt(7) 模长2 = sqrt(1^5) = sqrt(5)
余弦相似度 = 5 / (sqrt(7) * sqrt(5)) ≈ 0.845
余弦相似度为0.845,接近1,表明这两个问题的相似度很高。
三、基于向量空间模型的方法
向量空间模型是一种常见的文本表示方法,它将文本转换为向量,从而可以进行各种数学和统计操作。
1、词袋模型(Bag of Words, BoW)
词袋模型将文本表示为词的集合,忽略词序,但记录每个词的出现次数。在这种模型中,文本被看作是一个“袋子”,里面的词就是“袋子”中的元素。无论词的顺序如何,只要出现了就算一个。
示例: 假设我们在电商客服系统中处理用户的问题,有两个用户提出了以下问题:
- “这款手机的电池续航时间怎么样?”
- “电池续航这款手机的时间怎么样?”
虽然这两个问题的词序不同,但词袋模型会将它们视为相同的问题。我们可以将每个问题表示为一个词频向量:
问题1的词频向量:[“这款”:1, “手机”:1, “的”:1, “电池”:1, “续航”:1, “时间”:1, “怎么样”:1] 问题2的词频向量:[“这款”:1, “手机”:1, “的”:1, “电池”:1, “续航”:1, “时间”:1, “怎么样”:1]
这两个向量完全相同,因此在词袋模型中,它们被认为是相同的问题。这种方法忽略了词序,只关注词的出现次数,适用于词序不重要的情况。
2、词共现矩阵
词共现矩阵记录词在文档中共同出现的次数,用于捕捉词与词之间的关系。通过统计词与词之间的共现频率,我们可以了解词与词之间的关联性。
示例: 继续我们的电商客服系统的例子。假设在许多用户问题中,我们经常看到以下词:“手机”、“电池”、“续航”。我们可以构建一个词共现矩阵来记录这些词在同一个问题中共同出现的次数。
假设我们有以下几个问题:
- “这款手机的电池续航时间怎么样?”
- “电池续航这款手机的时间怎么样?”
- “手机电池寿命如何?”
我们可以构建一个词共现矩阵,记录这些词在同一个问题中出现的次数:
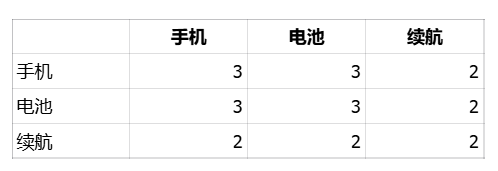

在这个矩阵中,手机和电池共同出现了3次,手机和续航共同出现了2次,电池和续航共同出现了2次。通过词共现矩阵,我们可以发现“手机”和“电池”之间有很强的关联性,用户的问题可能是关于手机电池的。
延展阅读:
如何通过微调Embedding模型提升RAG(检索增强生成)在问答中的召回效果







