文章导航
CAP理论
由来
CAP含义为Consistency(一致性)、Availability(可用性)、 Partition Tolerance(分区容忍性)。CAP 定理( CAP theorem )又被称作布鲁尔定理( Brewe theorem ),是由加州大学伯克利分校(领域神一样的大学)的计算机科学家埃里克·布鲁尔在2000年的ACM PODC上提出的一个猜想。 2002 年,麻省理工学院(另一所计算机领域神一样的大学的赛斯·吉尔伯特和南希·林奇发表了布鲁尔猜想的证明使之成为分布式计算领域公认的一个定理。对于设计分布式系统的架构师来说, CAP 是必须掌握的理论。
描述
CAP理论的提出者并没有详细定义CAP,所以描述版本比较多, 以下是其中一个版本:
In a distributed system (a collection of interconnected nodes that share data.), you can only have two out of the following three guarantees across a write/read pair:Consistency, Availability, and Partition Tolerance - one of them must be sacrificed。即,在一个分布式系统 指互相连接并共 数据的节点的 合)中,当涉及读写操作时,只能保证一致性( Consistence )、可用性( Availabilit )、分区容错性( Part ition Tolerance) 三者中的两个,另外一个必须被牺牲。
一致性(consistency)
A read is guaranteed to return the most recent te fo given client.
即,对某个指定的客户端来说,读操作保证能够返回最新的写操作结果。事务在执行过程中client是无法读取到未提交的数据的,只有等到事务提交后, client 才能读取到事务写入的数据,而如果事务失败则会进行回滚,client 不会读取到事务中间写入的数据。
可用性(availability)
A non-failing node will return a reasonable response within a reasonable amount of time (no error or timeout).
非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应).
分区容忍性(Partition Tolerance)
The system will continue to function when network partitlons occur。
当出现网络分区后,系统能够继续“履行职责”。
CAP的应用
虽然CAP理论定义是三个要素中只能取两个,但放到分布式环境下来思考,我们会发现必须选择分区容忍要素,因为网络本身无法做 100% ,有可能出故障,所以分区是一 个必然的现象。如果我们选择了 CA 而放弃了P ,那么当发生分区现象时,为了保证一致性,系统需要禁止写入。当有写入请求时,系统直接返回 error (即当前系统不允许写入), 这又和A冲突了,因为A要求返回 no error和 no timeout 。因此,分布式系统理论上不可能选择 CA 架构, 只能选择CP和AP架构。
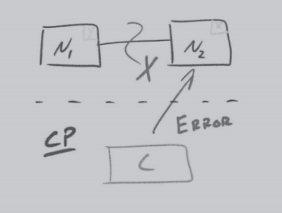

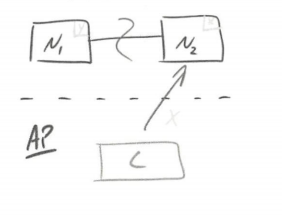
以上内容主要参考 李运华–《从零开始学架构》
RAFT协议
raft的paper原文如下:
In Search of an Understandable Consensus Algorithm (raft.github.io)
分布式存储系统通常通过维护多个副本来进行容错,提高系统的可用性。要实现此目标,就必须要解决分布式存储系统的最核心问题—-维护多个副本的一致性。一致性协议通常基于复制状态机(replicated state machines)实现。所有结点都从同一个state出发,都经过同样的一些操作序列(log),最后到达同样的state。
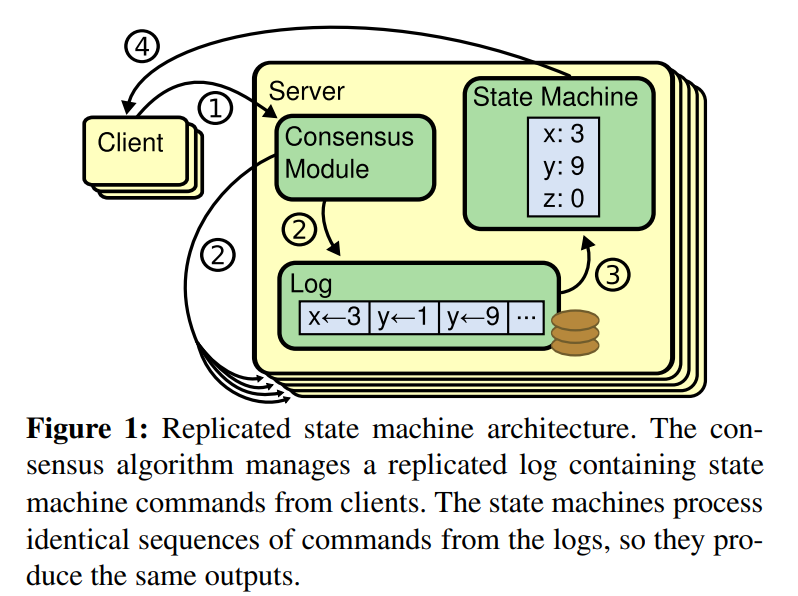
如上图所示,系统中每个节点有三个组件–状态机、Log和一致性模块:
状态机: 当我们说一致性的时候,实际就是在说要保证这个状态机的一致性。状态机会从log里面取出所有的命令,然后执行一遍,得到的结果就是我们对外提供的保证了一致性的数据
Log: 保存了所有修改记录
一致性模块: 一致性模块算法就是用来保证写入的log的命令的一致性,这也是raft算法的核心内容。
以下主要讲raft的三个重要组成部分:领导人选举(Leader election)、日志复制(Log replicate)、安全性。
Leader election
Raft协议的每个副本都会处于三种状态之一:Leader、Follower、Candidate。
Leader:所有请求的处理者,Leader副本接受client的更新请求,本地处理后再同步至多个其他副本;
Follower:请求的被动更新者,从Leader接受更新请求,然后写入本地日志文件
Candidate:如果Follower副本在一段时间内没有收到Leader副本的心跳,则判断Leader可能已经故障,此时启动选主过程,此时副本会变成Candidate状态,直到选主结束。
众所周知,分布式环境下的“时间同步”是一个大难题,于是任期(term)在raft中起着逻辑时钟作用,同时也用于检测raft节点中的过期信息。
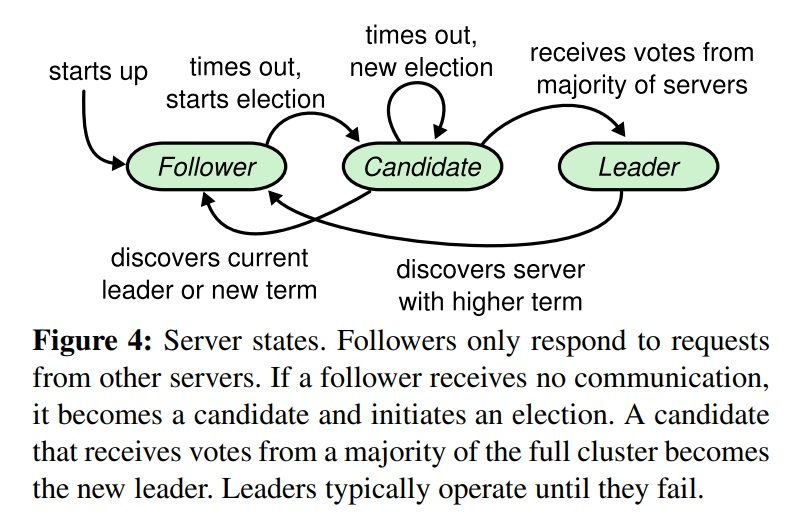
每个新加入集群的节点初始状态为follower, 若等待leader心跳包(appendEntries RPC)超时,则将自己本地term+1,然后状态转换为candidte并给自己先投一票, 并进行广播(RequestVote RPC)。以下是节点状态流转的条件:
- candidate收到大多数投票,则将自己转为leader
- 收到leader胜选通知则转为follower,
- 若没有leader胜选,则会在一个随机时间后再发起选举。
附RequestVote RPC调用的协议:
Term 候选人的任期号
candidateId 请求投票的候选人ID
LastLogIndex 候选人最新日志条目的索引值(槽位)
LastLogTerm 候选人最新日志条目对应的任期号
返回值列表
Term 当前任期号,用于候选人自己更新
voteGranted 是否投票
Request接收节点返回voteGranted=true的条件是候选人任期>=自己任期,并且日志没有自己旧。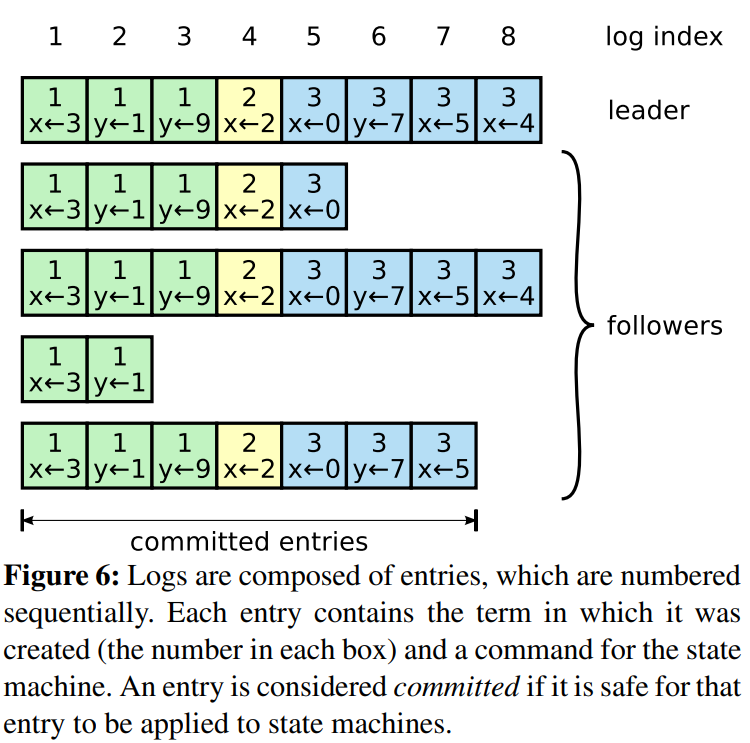
Log Replication
当Leader被选出来后,就可以接受客户端发来的请求了,每个请求包含一条需要被replicated state machines执行的命令。leader会把它作为一个log entry append到日志中,然后给其它的server发AppendEntriesRPC请求。若检测到大部分节点都将操作写入日志,那么就将该日志标记为commited,并向客户端返回成功。raft协议保证一条commited的log entry已经持久化并会被所有节点执行。
当然也有可能新选出的leader与follower日志不一致,那么如何来解决这种情况。
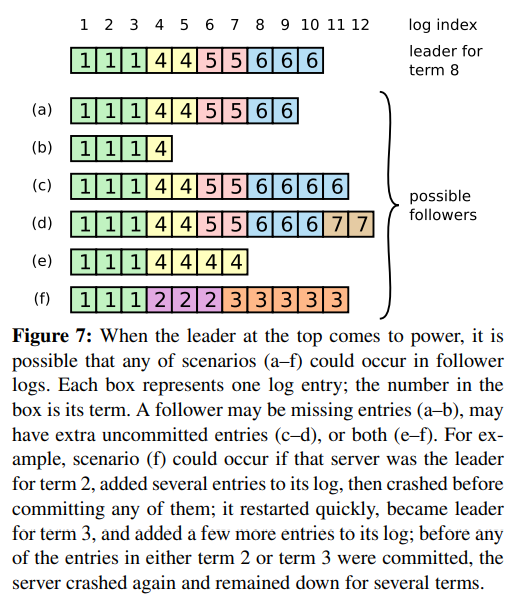
最上面的节点当选任期8的leader,那么(a-f)6种情况在followers中都可能发生。
将6种情况的节点与leader进行对比:
(a-b) 缺失了某些日志
(c-d) 多了一些未提交的日志
(e-f) 既多了一些日志,又少了一些日志
由于提交日志流程不少,所以中间可能会出现故障,比如主机宕机,客户端与leader网络闪断之类的。以下是提交日志的全过程:
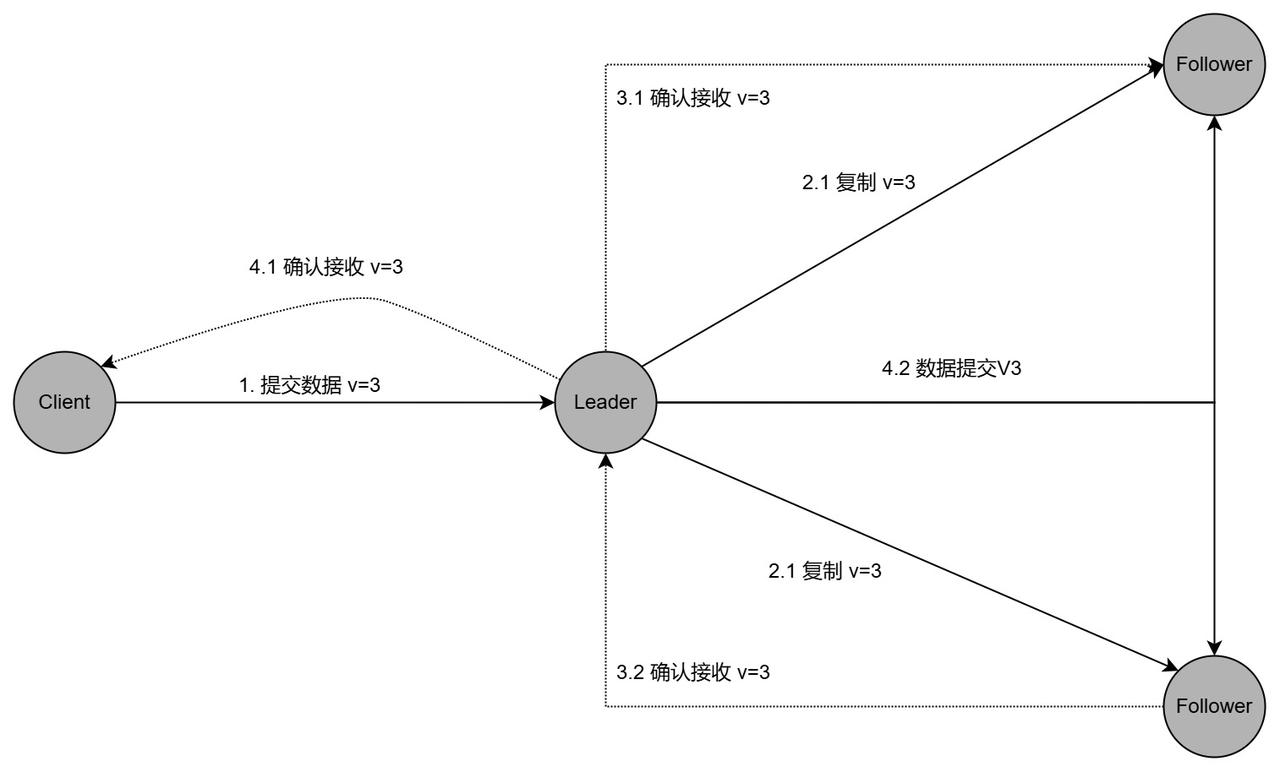
安全性
Raft算法保证新当选的领导人拥有之前任期已提交的所有日志条目,该保证隐含一下两点:
1)没有包含所有已提交日志条目的节点成为不了领导人。
2)日志条目只有一条流向:从Leader流向Follower. 领导人用于不会覆盖已经存在的日志条目。
实现方式是在选主时拒绝任期比自己小,或者日志比自己旧的选举请求。因为所有已提交日志都已经得到大部分节点的确认。
另外考虑一种情况。
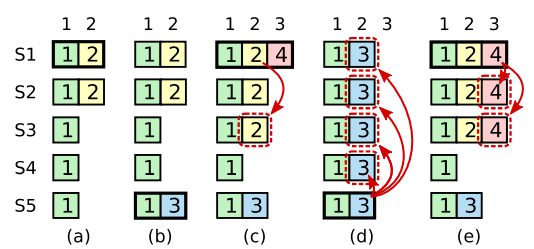
- 在阶段a,term为2,S1是Leader,且S1写入日志(term, index)为(2, 2),并且日志被同步写入了S2;
- 在阶段b,S1离线,触发一次新的选主,此时S5被选为新的Leader,此时系统term为3,且写入了日志(term, index)为(3, 2);
- S5尚未将日志推送到Followers变离线了,进而触发了一次新的选主,而之前离线的S1经过重新上线后被选中变成Leader,此时系统term为4,此时S1会将自己的日志同步到Followers,按照上图就是将日志(2, 2)同步到了S3,而此时由于该日志已经被同步到了多数节点(S1, S2, S3),因此,此时日志(2,2)可以被commit了(即更新到状态机);
- 在阶段d,S1又很不幸地下线了,系统触发一次选主,而S5有可能被选为新的Leader(这是因为S5可以满足作为主的一切条件:1. term = 3 > 2, 2. 最新的日志index为2,比大多数节点(如S2/S3/S4的日志都新),然后S5会将自己的日志更新到Followers,于是S2、S3中已经被提交的日志(2,2)被截断了,这是致命性的错误,因为一致性协议中不允许出现已经应用到状态机中的日志被截断。
针对以上场景,Raft算法对日志提交条件增加了一个额外的限制:
要求Leader在当前任期至少有一条日志被提交,即被超过半数的节点写盘。
也就是在(c)节点,S1作为任期4的节点,它不能单独去提交任期2的历史日志。它必须提交index=3然后顺带提交任期2的日志。这样就不会出现已经提交的日志还会被覆盖。
Log Compaction
在实际的系统中,不能让日志无限增长,否则系统重启时需要花很长的时间进行回放,从而影响availability。Raft采用对整个系统进行snapshot来处理,snapshot之前的日志都可以丢弃。
raft的go语言实现:
hashicorp/raft: Golang implementation of the Raft consensus protocol (github.com)
raft的js语言实现:
参考文章:
In Search of an Understandable Consensus Algorithm (raft.github.io)
动画演示:
Raft (thesecretlivesofdata.com)
延展阅读:







